第 4 章
数字系统
介绍
在数据恢复编程或任何其他磁盘故障排除编程中,通常需要同时使用不同类型的数字系统来执行单个任务或甚至很小一部分工作,例如根据 CHS(柱面、磁头和扇区)计算扩展 MBR 的具体位置,并且这些位置指导程序员完成整个操作。
大多数新程序员在尝试学习汇编语言系统编程(必须使用二进制和十六进制数字系统)时,可能会面临将不同类型的数字系统相互转换的问题或困惑。
在本章中,我们将讨论许多重要概念,包括二进制、十进制、十六进制数字系统以及二进制数据组织,例如位、半字节、字节、字和双字等的转换,以及许多其他相关的数字系统主题。
大多数现代计算机系统不使用十进制系统来表示数值,而是通常使用二进制或二进制补码系统。
编程中常用的数制有四种:
二进制、八进制、十进制和十六进制
。然而,我们最常遇到的是二进制、十进制和十六进制数字系统。这些数字系统根据其基数而不同。
每个数字系统都有自己的基数和表示符号。我在下表中列出了这四个数字:
| 数字系统名称
|
基本号码
|
用来表示的符号
|
| 二进制
|
2
|
乙
|
| 八进制
|
8
|
问或答
|
| 十进制
|
10
|
D 或否
|
| 十六进制
|
16
|
时间
|
十进制数制
十进制数字系统以 10 为基数,包括数字 0 到 9。不要混淆,这是我们在日常生活中用于计算的常见数字系统。每个位置的功率加权值将是:

因此,如果我有十进制数 218,并且我想以上述方式表示它,那么数字 218 将表示如下:
2 * 102 + 1 * 101 + 8 * 100
= 2 * 100 + 1 * 10 + 8 * 1
= 200 + 10 + 8
= 218
现在让我们看任意小数部分的小数的一个例子。假设我们有数字 821,128。小数点左边的每个数字代表从零到九的一个值,十的幂由其在数字中的位置表示(从 0 开始)。
小数点右边的数字代表从零到九的数值乘以十的上升负幂。让我们看看如何:
8*102+2*101+1*100+1*10-1+2*10-2+8*10-3
= 8 * 100 + 2 * 10 + 1 * 1 + 1 * 0,1 + 2 * 0,01 + 8 * 0,001
= 800 + 20 + 1 + 0,1 + 0,02 + 0,008
= 821,128
二进制数系统
当今,大多数现代计算机系统都采用二进制逻辑运行。计算机使用两个电压电平来表示值,
使用 0 和 1 表示 OFF 或 ON。
例如,0 V 电压通常用逻辑 0 表示,而 +3.3 V 或 +5 V 电压用逻辑 1 表示。因此,通过两个电平,我们可以准确地表示两个不同的值。它们可以是任意两个不同的值,但按照惯例我们使用值 0 和 1。
由于计算机所采用的逻辑电平和二进制数制中的两个数字之间存在对应关系,因此计算机采用二进制也就不足为奇了。
二进制数系统与十进制数系统的工作原理相同,不同之处在于二进制数系统使用基数2,并且只使用数字0和1,使用任何其他数字都会使该数字成为无效的二进制数。
每个项目的加权值呈现如下:

下表显示了二进制数与十进制数的表示形式对比:
| 十进制数
|
数字的二进制表示
|
| 0
|
0000
|
| 1
|
0001
|
| 2
|
0010
|
| 3
|
0011
|
| 4
|
0100
|
| 5
|
0101
|
| 6
|
0110
|
| 7
|
0111
|
| 8
|
1000
|
| 9
|
1001
|
| 10
|
1010
|
| 11
|
1011
|
| 12
|
1100
|
| 十三
|
1101
|
| 14
|
1110
|
| 15
|
1111
|
通常对于十进制数,每三位十进制数用逗号分隔,以使较大的数字更容易阅读。例如,数字 840,349,823 比 840349823 更容易阅读。
受到相同想法的启发,二进制数也有类似的约定,以便更容易读取二进制数,但对于二进制数,我们将从小数点左边的最低有效数字开始,每四位数字添加一个空格。
例如,
如果二进制值为 1010011001101011,则写为 1010 0110 0110 1011。
二进制到十进制数的转换
要将二进制数转换为十进制数,我们将每个数字乘以其加权位置,然后将每个加权值相加。例如,二进制值 1011 0101 表示:
1*27 + 0*26 + 1*25 + 1*24 + 0*23 + 1*22 + 0*21 + 1*20 = 1 * 128 + 0 * 64 + 1 * 32 + 1 * 16 + 0 * 8 + 1 * 4 + 0 * 2 + 1 * 1 = 128 + 0 + 32 + 16 + 0 + 4 + 0 + 1 = 181
十进制到二进制的转换
要将任何十进制数转换为二进制数,一般方法是将十进制数除以 2,如果余数为 0,则在旁边写下 0。如果余数为 1,则写下 1。
继续此过程,将商除以 2,并去掉之前的余数,直到商为 0。执行除法时,余数将表示十进制数的二进制等值,从最低有效数字(右边)开始写入,并且每个新数字都写入前一位数字的更高有效数字(左边)。
让我们举个例子
。考虑数字 2671。下表给出了数字 2671 的二进制转换。
| 分配
|
商
|
余
|
二进制数
|
| 2671 / 2
|
1335
|
1
|
1
|
| 1335 / 2
|
667
|
1
|
11
|
| 667 / 2
|
333
|
1
|
111
|
| 333 / 2
|
166
|
1
|
1111
|
| 166 / 2
|
83
|
0
|
0 1111
|
| 83 / 2
|
41
|
1
|
10 1111
|
| 41 / 2
|
20
|
1
|
110 1111
|
| 20 / 2
|
10
|
0
|
0110 1111
|
| 10 / 2
|
5
|
0
|
0 0110 1111
|
| 5 / 2
|
2
|
1
|
10 0110 1111
|
| 2 / 2
|
1
|
0
|
010 0110 1111
|
| 1 / 2
|
0
|
1
|
1010 0110 1111
|
此表是为了阐明转换的每个步骤,然而在实践中,为了获得转换的便利和速度,您可以按照以下方式获取结果。
假设 1980 是任意十进制数,需要将其转换为二进制数。然后按照表中给出的方法,我们将以以下方式解决此问题:
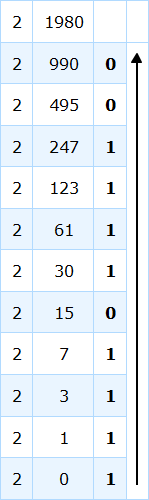
当我们将余数按照箭头方向排列时,我们得到相当于十进制数
1980 的二进制数 = 0111 1011 1100
二进制数格式
通常我们将二进制数写成位序列。“位”是机器中“二进制数字”的缩写。这些位有定义的格式边界。这些格式边界已在下表中表示:
| 姓名
|
大小(以位为单位)
|
例子
|
| 少量
|
1
|
1
|
| 蚕食
|
4
|
0101
|
| 字节
|
8
|
0000 0101
|
| 单词
|
16
|
0000 0000 0000 0101
|
| 双字
|
三十二
|
0000 0000 0000 0000 0000 0000 0000 0101
|
我们可以根据需要添加任意数量的前导零,而无需改变其在任何数字基数中的值,但是我们通常添加前导零来将二进制数调整到所需的大小边界。
例如,
我们可以用下表所示的不同情况来表示数字 7:
| | 15
| 14
| 十三
| 12
| 11
| 10
| 9
| 8
| 7
| 6
| 5
| 4
| 3
| 2
| 1
| 0
|
| 少量
| | | | | | | | | | | | | | 1
| 1
| 1
|
| 蚕食
| | | | | | | | | | | | | 0
| 1
| 1
| 1
|
| 字节
| | | | | | | | | 0
| 0
| 0
| 0
| 0
| 1
| 1
| 1
|
| 单词
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 1
| 1
| 1
|
二进制数的最右边的位是位位置零,并且左边的每个位都被赋予下一个连续的位数,如上表所示。
位零通常称为最低有效位或 LSB,最左边的位通常称为最高有效位或 MSB。让我们了解这些表示格式:
比特
位是二进制计算机上最小的数据单位。单个位只能表示一个值,即 0 或 1。如果您使用位来表示布尔值(真/假),那么该
位表示真或假
。
啃咬
当我们谈论数字系统、BCD(二进制编码的十进制)或/和十六进制(以 16 为基数)数字时,Nibble 特别引起我们的兴趣。
半字节是 4 位边界上的位集合。需要四位来表示单个 BCD 或十六进制数字。使用半字节,我们可以表示最多 16 个不同的值。
对于十六进制数,值 0、1、2、3、4、5、6、7、8、9、A、B、C、D、E 和 F 用四位表示。BCD 使用十个不同的数字(0、1、2、3、4、5、6、7、8、9),需要四位。
事实上,任何十六个不同的值都可以用一个半字节表示,但十六进制和 BCD 数字是我们可以用单个半字节表示的主要项目。半字节的位级表示如下:
字节
字节是 80x86 微处理器使用的最重要的数据结构。一个字节由 8 位组成,是微处理器中最小的可寻址数据项。计算机中的主内存和 I/O 地址都是字节地址,因此 80x86 微处理器程序可以单独访问的最小项是 8 位值。
要访问任何较小的数据,您需要读取包含数据的字节并屏蔽掉不需要的位。我们将在下一章中编写程序来执行此操作。
字节最重要的用途是保存字符代码。字节中的位从位零 (b0) 到位七 (b7) 编号如下:

位 0 (b0) 是字节的低位或最低有效位,位 7 (b7) 是字节的高位或最高有效位。
从这里可以看出,一个字节恰好包含两个半字节,其中位 b0 到 b3 构成低位半字节,位 b4 到 b7 构成高位半字节。
由于一个字节恰好包含两个半字节,因此字节值需要两个十六进制数字。
由于传统的现代计算机是字节寻址机器,因此操作整个字节比操作单个位或半字节更有效率。
这就是大多数程序员使用整个字节来表示不超过 256 个项目的数据类型的原因
由于一个字节包含八位,它可以表示 28 或 256 个不同的值,因为最大的 8 位二进制数可以是 1111 1111,相当于 256(十进制),因此通常用一个字节来表示以下内容:
- 0 至 255 范围内的无符号数值
- -128 至 +127 范围内的有符号数
- ASCII 字符代码
- 其他特殊数据类型需要的不同值不超过 256 个,因为许多数据类型的项目少于 256 个,因此八位通常就足够了。
话语
一个字是一组 16 位
。但传统上,字的边界定义为 16 位或处理器数据总线的大小,而双字是两个字。因此,字和双字不是固定大小,而是根据处理器的不同而因系统而异。但是,为了概念性阅读,我们将一个字定义为两个字节。
当我们在位级别上看到一个字时,它将被编号为字中的位,从位零 (b0) 开始到位十五 (b15)。位级表示如下:

其中位 0 是 LSB(最低有效位),位 15 是 MSB(最高有效位)。当需要引用字中的其他位时,使用其位位置编号来引用它们。
这样,一个字恰好包含两个字节,即位 b0 到位 b7 构成低位字节,位 b8 到 b15 构成高位字节。使用 16 位字,我们可以表示 216 (65536) 个不同的值。这些值可能如下:
- 0 至 65,535 范围内的无符号数值。
- 有符号数值范围在 -32,768 至 +32,767 之间
- 任何不超过 65,536 个值的数据类型。这样的话,单词主要用于:
- 16 位整数数据值
- 16 位内存地址
- 任何需要 16 位或更少的数字系统
双重词
双字顾名思义就是两个字,所以一个
双字的数量是32位
,双字也可以分为一个高位字和一个低位字,四个字节,或者八个半字节等等。
这样,双字就可以表示各种不同的数据。它可能有以下几种:
- 一个无符号双字,范围为 0 至 4,294,967,295,
- 有符号双字,范围为 -2,147,483,648 至 2,147,483,647,
- 32 位浮点值
- 或者任何其他需要 32 位或更少的数据。
八进制数系统
八进制数字系统在旧计算机系统中很流行,但如今很少使用。不过,我们仅从知识角度考虑,还是采用八进制系统作为理想系统。
八进制系统以二进制系统为基础,以 3 位为边界。八进制数系统使用 8 进制,仅包含数字 0 到 7。这样,任何其他数字都会使该数字成为无效的八进制数。
各位置权重值如下表所示:
| (基本)功率
|
85
|
84
|
83
|
82
|
81
|
80
|
| 价值
|
32768
|
4096
|
512
|
64
|
8
|
1
|
二进制到八进制的转换
要将整数二进制数转换为八进制数,我们遵循以下两个步骤:
首先将二进制数从
LSB 到 MSB
分成 3 位部分。然后将 3 位二进制数转换为其八进制等价数。让我们举一个例子来更好地理解它。如果我们给出任何二进制数,比如 11001011010001 以转换为八进制数,我们将对这个数字应用上述两个步骤,如下所示:
| 二进制数的 3 位部分
|
011
|
001
|
011
|
010
|
001
|
| 当量数
|
3
|
1
|
3
|
2
|
1
|
因此,相当于
二进制数 11001011010001 的八进制数是 31321。
八进制到二进制的转换
要将任何整数八进制数转换为其对应的二进制数,我们遵循以下两个步骤:
首先将十进制数转换为其 3 位二进制数。然后通过删除空格将 3 位部分组合起来。举个例子。如果我们要将任何八进制数整数 31321(Q) 转换为其对应的二进制数,我们将按如下方式应用上述两个步骤:
| 当量数
|
3
|
1
|
3
|
2
|
1
|
| 二进制数的 3 位部分
|
011
|
001
|
011
|
010
|
001
|
因此,
八进制数 31321(Q) 的二进制等价于 011 0010 1101 0001。
八进制到十进制的转换
要将任何八进制数转换为十进制,我们将每个位置的值乘以其八进制权重,然后将每个值相加。
让我们举一个例子来更好地理解这一点。假设我们要将任意八进制数 31321Q 转换为其对应的十进制数。然后我们将遵循以下步骤:
3*84 + 1*83 + 3*82 + 2*81 + 1*80 = 3*4096 + 1*512 + 3*64 + 2*8 + 1*1 = 12288 + 512 + 192 + 16 + 1 = 13009
十进制到八进制的转换
将十进制转换为八进制稍微困难一些。将十进制转换为八进制的典型方法是重复除以 8。对于这种方法,我们将十进制数除以 8,并将余数写在一边作为最低有效位。继续此过程,将商除以 8,并写出余数,直到商为 0。
执行除法时,表示十进制数的八进制等值的余数从最低有效数字(右边)开始写出,并且每个新数字写入前一位数字的下一个更有效的数字(左边)。
让我们通过一个例子来更好地理解它。如果我们有任何十进制数,比如 13009(我们从上面的例子中找到了这个十进制数,通过将其转换回八进制数,我们也可以检查前面的例子。)那么这种方法已经在下表中进行了描述:
| 分配
|
商
|
余
|
八进制数
|
| 13009 / 8
|
1626
|
1
|
1
|
| 1626 / 8
|
203
|
2
|
21
|
| 203 / 8
|
二十五
|
3
|
321
|
| 25 / 8
|
3
|
1
|
1321
|
| 3 / 8
|
0
|
3
|
31321
|
如您所见,我们回到了原始数字。这正是我们所期望的。此表用于了解该过程。现在让我们重复相同的转换,以了解在实践中应遵循的方法,以便轻松工作并节省时间。事实上,两者是同一件事。
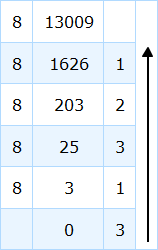
当我们将余数按照箭头方向排列时,我们得到了我们所期望的八进制数 31321。
十六进制数系统
十六进制数最常用于我们的数据恢复或任何其他类型的磁盘故障排除或磁盘分析编程,因为十六进制数提供以下两个功能:
十六进制数非常紧凑。而且很容易从十六进制转换为二进制,从二进制转换为十六进制。当我们要计算硬盘的磁柱数、磁头数和扇区数等许多重要信息,或者使用硬盘编辑器程序分析不同的特性和问题时,我们需要对十六进制系统有很好的了解。十六进制系统基于使用半字节或 4 位边界的二进制系统。
十六进制数系统
使用 16 进制
,仅包含数字 0 到 9 以及字母 A、B、C、D、E 和 F。我们使用 H 和数字来表示任何十六进制数。下表显示了各种数系统的表示方法,并将它们相互区分:
| 二进制
| 八进制
| 十进制
| 十六进制
|
| 0000B
| 00Q
| 00
| 00小时
|
| 0001B
| 01Q
| 01
| 01小时
|
| 0010B
| 02Q
| 02
| 02小时
|
| 0011B
| 03季
| 03
| 03小时
|
| 0100B
| 04季
| 04
| 04 小时
|
| 0101B
| 05Q
| 05
| 05小时
|
| 0110B
| 06Q
| 06
| 06小时
|
| 0111B
| 07Q
| 07
| 07H
|
| 1000B
| 10问
| 08
| 08小时
|
| 1001B
| 11问
| 09
| 09H
|
| 1010B
| 12Q
| 10
| 0AH
|
| 1011B
| 13问
| 11
| 0BH
|
| 1100B
| 14问
| 12
| 0通道
|
| 1101B
| 15问
| 十三
| 0DH
|
| 1110B
| 16问
| 14
| 0EH
|
| 1111B
| 17问
| 15
| 0FH
|
| 1 0000B
| 20问
| 16
| 10H
|
该表提供了将 0 至 16 的十进制值从一个数基转换为另一个数基所需的所有信息。
十六进制数各个位置的加权值如下表所示:
| (基本)功率
|
163
|
162
|
161
|
160
|
| 价值
|
4096
|
256
|
16
|
1
|
二进制到十六进制的转换
要将二进制数转换为十六进制格式,首先在二进制数的最左侧用前导零填充,以确保二进制数包含四位的倍数。之后请遵循以下两个步骤:
首先,将二进制数从 LSB 到 MSB 分成 4 位部分。然后将 4 位二进制数转换为其十六进制等价数。让我们举一个例子来更好地理解该方法。假设我们有任意二进制数 100 1110 1101 0011 需要转换为其对应的十六进制数。然后我们将应用上述两个步骤,如下所示:
| 4位二进制数部分
|
0100
|
1110
|
1101
|
0011
|
| 十六进制值
|
4
|
和
|
德
|
3
|
因此,与二进制数 100 1110 1101 0011 对应的十六进制值为
4ED3。
十六进制到二进制的转换
要将十六进制数转换为二进制数,我们遵循以下两个步骤:
首先,将十六进制数转换为其 4 位二进制等价数。然后通过删除空格来合并 4 位部分。为了更好地理解该过程,让我们以上述十六进制数 4ED3 为例,并按如下方式对其应用这两个步骤
| 十六进制值
|
4
|
和
|
德
|
3
|
| 4位二进制数部分
|
0100
|
1110
|
1101
|
0011
|
因此,对于十六进制数 4ED3,我们得到相应的二进制数 = 0100 1110 1101 0011
这是预期的答案。
十六进制到十进制的转换 要从十六进制转换为十进制,我们将每个位置的值乘以其十六进制权重,然后将每个值相加。让我们举一个例子来更好地理解这个过程。假设我们有一个十六进制数 3ABE 需要转换为其等效的十进制数。那么过程如下:3*163 + A*162 + B*161 + E*160 = 3* 4096 + 10* 256 + 11*16 + 14 = 12288 + 2560 + 176 + 14 = 15038
因此十六进制数 3ABE 对应的十进制数
是 15038。
十进制到十六进制的转换
要将十进制转换为十六进制,典型的方法是
重复除以 16
。对于此方法,我们将十进制数除以 16 并将余数写在边上作为最低有效位。
继续此过程,将商除以 16,并写入余数,直到商为 0。执行除法时,表示十进制数的十六进制等值的余数从最低有效数字(右边)开始写入,并且每个新数字都写入前一位数字的下一个更有效的数字(左边)。
让我们通过例子来学习。我们取上面转换后得到的十进制数 15038。通过这个我们也可以检查上面的转换,反之亦然。
| 分配
|
商
|
余
|
十六进制数
|
| 15038 / 16
|
939
|
14(
E
H)
|
和
|
| 939 / 16
|
58
|
11(
B
H)
|
是
|
| 58 / 16
|
3
|
10(
好
)
|
安倍晋三
|
| 3 / 16
|
0
|
3(
3
小时)
|
03ABE
|
这样我们就得到了十六进制数 03ABE H,相当于十进制数 15038,这样我们就回到了原始数字。这正是我们所期望的。
下表可以帮助您在 0 到 255 十进制数范围内快速搜索十六进制数与十进制数的转换,反之亦然。
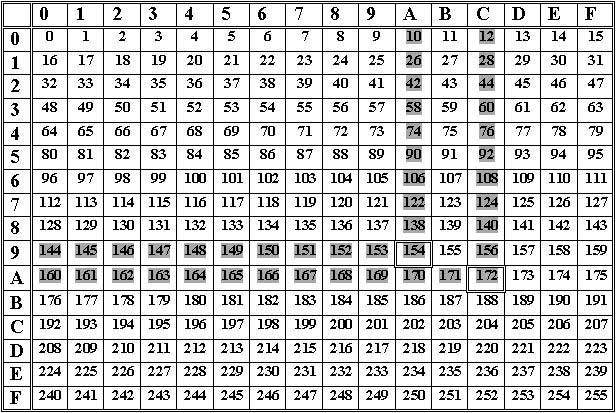
在这个方格表中,有 16 行,从 0 到 A,还有 16 列,也从 0 到 A。从这个表中,你可以找到 0H 到 FFH 范围内的任何十六进制数的十进制值。这意味着数字的十进制值应该在 0 到 255 十进制数的范围内。
- 从上表中查找十六进制数的十进制值:在上表中,行数代表十六进制数的第一位十六进制数字(左边十六进制数字),列数代表十六进制数的第二个十六进制数字(右边十六进制数字)。
假设我们有一个十六进制数,比如 ACH,需要将其转换为等效的十进制数。那么我们将在表格中第 A 行第 C 列看到十进制值,并得到十进制值 172,这是十六进制数 ACH 的等效十进制数。
- 从上表中查找十进制数的十六进制值:在上表中,行数代表十六进制数的第一位十六进制数字(左边十六进制数字),列数代表十六进制数的第二个十六进制数字(右边十六进制数字),因此如果您有任何十进制数需要转换为等效的十六进制数,请在表中搜索该数字并找到等效的十六进制值,如下所示:
十进制数的十六进制值 = (行号)(列号)
例如,如果您想找到十进制数 154 的等效十六进制值,请查看表中数字的位置。数字 154 位于表格的第 9 行和第 A 列。因此,十进制数 154 的等效十六进制值为 9AH。
ASCII 码
ASCII 的缩写代表美国信息交换标准代码。它是字符、数字和符号的编码标准,与 ASCII 字符集的前 128 个字符相同,但与其余字符不同。这些其他字符通常称为 IBM 定义的扩展字符的特殊 ASCII 字符。
前 32 个字符是 ASCII 代码 0 到 1FH,形成一组特殊的非打印字符。这些字符称为控制字符,因为这些字符执行各种打印机和显示控制操作,而不是显示符号。这些字符已在本章给出的 ASCII 字符表中列出。这些控制字符具有以下含义:
零(ZERO):
无字符。它用于填充时间或填充存储设备表面(例如盘片表面)上没有数据的空间。当我们对数据擦除器(破坏性和非破坏性)进行编程时,我们将使用此字符来擦除未分配的空间,以便任何人或任何程序都无法恢复已删除的数据。
SOH(航向开始):
该字符用于指示航向的开始,可能包含地址或路线信息。
TX(文本开始):
该字符用于指示文本的开始,同样也用于指示标题的结束。
ETX(正文结束):
该字符用于终止以 STX 开始的文本。
EOT(传输结束):
此字符表示传输的结束,其中可能包含一个或多个带有标题的“测试”。
ENQ (询问):
这是对远程站点的响应请求。这是对站点进行自我识别的请求。
ACK(确认):
它是一个字符,由接收设备作为对砂磨机的肯定响应发送。它用作对轮询消息的肯定响应。
BEL(贝尔):
它用于需要引起人们注意的时候。它可以控制警报或注意设备。当您在命令提示符中键入此字符时,您会听到连接到计算机的扬声器发出的铃声,如下所示:
C:\> 回显 ^G
这里的 ^G 是通过 Ctrl + G 组合键组合打印的。
BS(退格键):
该字符指示打印机制或显示光标在一个位置向后移动。
HT(水平制表符):
它指示打印机制或显示光标向前移动到下一个预先指定的“Tab”或停止位置。
LF(换行):
它指示打印机制或显示光标移动到下一行的开头。
VT(垂直制表符):
它指示打印机制或显示光标移动到一系列预先指定的打印行中的下一行。
FF(换页):
它表示打印机制或显示光标移动到下一页、下一页或下一屏幕的起始位置。
CR(回车):
指示打印机器或显示光标移动到同一行的起始位置。
SO(移出):
它表示后面的代码组合应被解释为标准字符集之外,直到达到 Shift In 字符为止。
I (移入):
表示后面的代码组合要按照标准字符集来解释。
DLE(数据链路逃逸):
它是一个可以改变一个或多个连续字符含义的字符。它可以提供补充控制,或允许发送具有任意位组合的数据字符。
DC1、DC2、DC3 和 DC4(设备控制):
这些是用于控制辅助设备或特殊终端功能的字符。
NAK(否定确认):
它是接收设备作为对发送方的否定响应而发送的字符。它用作对轮询消息的否定响应。
SYN(同步/空闲):
它用于同步传输系统实现同步,当没有数据正在发送时,同步传输系统可能会连续发送SYN字符。
ETB(传输块结束):
此字符表示通信数据块的结束。它用于分块数据,其中块结构不一定与处理格式相关。
CAN(取消):
它表示应忽略消息或块中它之前的数据,通常是因为检测到了错误。
EM(介质末端):
它表示磁带、表面(通常是磁盘的盘片)或其他介质的物理末端,或者介质所需使用部分的末端。
SUB(替代):
替代发现错误或无效的字符。
ESC(Escape):
它是一个旨在提供代码扩展的字符,它为指定数量的连续字符赋予替代含义。
FS(文件分隔符):
此字符用作文件分隔符。
GS(Group Separator):
作为组分隔符。
RS(记录分隔符):
用作记录分隔符。
美国(联合分隔符):
它是一个联合分隔符。
第二组 32 个 ASCII 字符代码包含各种标点符号、特殊字符和数字。此组中最值得注意的字符包括:
空格字符(ASCII 代码 20H) 数字 0 至 9(ASCII 代码 30h 至 39h) 数学和逻辑符号
SP(空格):
它是一种非打印字符,用于分隔单词或移动打印机制,或将光标向前显示一个位置。
第三组 32 个 ASCII 字符是大写字母字符组。字符 A 到 Z 的 ASCII 代码位于 41H 到 5AH 范围内。由于只有 26 个不同的字母字符,因此其余六个代码包含各种特殊符号。
第四组 32 个 ASCII 字符代码是小写字母符号、五个附加特殊符号和另一个控制字符删除的组。
DEL(删除):
它用于消除不需要的字符,或者我们可以说是删除不需要的字符。
接下来显示了两个表,分别表示 ASCII 代码和扩展字符。第一个表表示所描述的所有四组不同类型的字符。该表是数据表示和 ASCII 表,如下所示:
数据表示及 ASCII 码表:
| 十六进制
| 十二月
| 人权委员会
| 控制键
|
|---|
| 00
| 0
| 无效的
| ^@
|
| 01
| 1
| 索氏
| ^A
|
| 02
| 2
| 星火
| ^B
|
| 03
| 3
| 乙炔
| ^C
|
| 04
| 4
| 终止时间
| ^D
|
| 05
| 5
| 询问
| ^E
|
| 06
| 6
| 确认
| ^F
|
| 07
| 7
| 比利时
| ^G
|
| 08
| 8
| 学士学位
| ^H
|
| 09
| 9
| 高温
| ^我
|
| 0A
| 10
| 低频
| ^J
|
| 0B
| 11
| 室性心动过速
| ^K
|
| 0摄氏度
| 12
| FF
| ^L
|
| 0D
| 十三
| 碳排放
| ^M
|
| 0E
| 14
| 所以
| ^N
|
| 0F
| 15
| 和
| ^O
|
| 10
| 16
| 根据
| ^P
|
| 11
| 17
| DC1
| ^Q
|
| 12
| 18
| DC2
| ^R
|
| 十三
| 19
| DC3
| ^S
|
| 14
| 20
| DC4
| ^T
|
| 15
| 21
| 通缉
| ^U
|
| 16
| 22
| 他的
| ^V
|
| 17
| 23
| 乙肝疫苗
| ^W
|
| 18
| 24
| 能
| ^X
|
| 19
| 二十五
| 在
| ^并且
|
| 1A
| 二十六
| 子
| ^Z
|
| 1B
| 二十七
| ESC键
|
| 1C
| 二十八
| FS
|
| 1D
| 二十九
| GS
|
| 1E
| 三十
| 遥感
|
| 1F
| 31
| 我们
|
| 十六进制
| 十二月
| 人权委员会
|
|---|
| 20
| 三十二
| 服务供应商
|
| 21
| 33
| !
|
| 22
| 三十四
| “
|
| 23
| 三十五
| #
|
| 24
| 三十六
| $
|
| 二十五
| 三十七
| %
|
| 二十六
| 三十八
| &
|
| 二十七
| 三十九
| ‘
|
| 二十八
| 40
| (
|
| 二十九
| 41
| )
|
| 2A
| 四十二
| *
|
| 2B
| 43
| +
|
| 2C
| 四十四
| ,
|
| 2D
| 四十五
| -
|
| 2E
| 四十六
| 。
|
| 2F
| 四十七
| /
|
| 三十
| 四十八
| 0
|
| 31
| 49
| 1
|
| 三十二
| 50
| 2
|
| 33
| 51
| 3
|
| 三十四
| 52
| 4
|
| 三十五
| 53
| 5
|
| 三十六
| 54
| 6
|
| 三十七
| 55
| 7
|
| 三十八
| 56
| 8
|
| 三十九
| 57
| 9
|
| 3A
| 58
| :
|
| 3B
| 59
| ;
|
| 3C
| 60
| <
|
| 3D
| 61
| =
|
| 3E
| 62
| >
|
| 3楼
| 63
| ?
|
| 十六进制
| 十二月
| 人权委员会
|
|---|
| 40
| 64
| @
|
| 41
| 65
| 一个
|
| 四十二
| 66
| 乙
|
| 43
| 67
| 碳
|
| 四十四
| 68
| 德
|
| 四十五
| 69
| 和
|
| 四十六
| 70
| 弗
|
| 四十七
| 71
| 格
|
| 四十八
| 72
| 赫
|
| 49
| 73
| 我
|
| 4A
| 74
| J
|
| 4B
| 75
| 钾
|
| 4C
| 76
| 大号
|
| 4D
| 77
| 米
|
| 4E
| 78
| 否
|
| 4楼
| 79
| 这
|
| 50
| 80
| 磷
|
| 51
| 81
| 问
|
| 52
| 82
| R
|
| 53
| 83
| 年代
|
| 54
| 84
| 电视
|
| 55
| 85
| 在
|
| 56
| 86
| 在
|
| 57
| 87
| 在
|
| 58
| 88
| 十
|
| 59
| 89
| 和
|
| 5A
| 90
| 和
|
| 5B
| 91
| [
|
| 5C
| 92
| \
|
| 5D
| 93
| ]
|
| 5E
| 94
| ^
|
| 5楼
| 95
| _
|
| 十六进制
| 十二月
| 人权委员会
|
|---|
| 60
| 96
| `
|
| 61
| 97
| 一个
|
| 62
| 98
| b
|
| 63
| 99
| c
|
| 64
| 100
| d
|
| 65
| 101
| 和
|
| 66
| 102
| f
|
| 67
| 103
| 克
|
| 68
| 104
| 时长
|
| 69
| 105
| 我
|
| 6A
| 106
| 杰
|
| 6B
| 107
| 钾
|
| 6C
| 108
| 升
|
| 6D
| 109
| 米
|
| 6E
| 110
| n
|
| 6楼
| 111
| 这
|
| 70
| 112
| 页
|
| 71
| 113
| 问
|
| 72
| 114
| r
|
| 73
| 115
| s
|
| 74
| 116
| 吨
|
| 75
| 117
| 在
|
| 76
| 118
| 在
|
| 77
| 119
| 在
|
| 78
| 120
| 十
|
| 79
| 121
| 和
|
| 7A
| 122
| 和
|
| 7B
| 123
| {[}
|
| 7C
| 124
| |
|
| 7D
| 125
| }
|
| 7E
| 126
| ~
|
| 7楼
| 127
| 的
|
下表显示了 128 个特殊 ASCII 字符集,通常称为扩展 ASCII 字符:
| 十六进制
| 十二月
| 人权委员会
|
|---|
| 80
| 128
| 什么
|
| 81
| 129
| ü
|
| 82
| 130
| 和
|
| 83
| 131
| 一个
|
| 84
| 132
| 一个
|
| 85
| 133
| 有
|
| 86
| 134
| 到
|
| 87
| 135
| 什么
|
| 88
| 136
| 将要
|
| 89
| 137
| s
|
| 8A
| 138
| 和
|
| 8B
| 139
| 我
|
| 8C
| 140
| 问
|
| 8D
| 141
| 在
|
| 8E
| 142
| 一个
|
| 8楼
| 143
| 哦
|
| 90
| 144
| 和
|
| 91
| 145
| 哦
|
| 92
| 146
| 噢,噢
|
| 93
| 147
| 伞
|
| 94
| 148
| 他
|
| 95
| 149
| 不
|
| 96
| 150
| 和
|
| 97
| 151
| ù
|
| 98
| 152
| ÿ
|
| 99
| 153
| 他
|
| 9A
| 154
| 乌
|
| 9B
| 155
| ¢
|
| 9C
| 156
| £
|
| 9D
| 157
| ¥
|
| 9E
| 158
| ₧
|
| 9楼
| 159
| ƒ
|
| A0
| 160
| 在
|
| A1
| 161
| 在
|
| A2
| 162
| 从
|
| A3
| 163
| 呃
|
| A4
| 164
| ñ
|
| 十六进制
| 十二月
| 人权委员会
|
|---|
| A5
| 165
| Ñ
|
| A6
| 166
| ª
|
| A7
| 167
| º
|
| A8
| 168
| ¿
|
| A9
| 169
| ⌐
|
| AA
| 170
| ¬
|
| AB
| 171
| ½
|
| 交流电
| 172
| ¼
|
| 广告
| 173
| ¡
|
| 但
| 174
| «
|
| 的
| 175
| »
|
| B0
| 176
| ░
|
| B1
| 177
| ▒
|
| B2
| 178
| ▓
|
| B3
| 179
| │
|
| B4
| 180
| ┤
|
| B5
| 181
| ╡
|
| B6
| 182
| ╢
|
| B7
| 183
| ╖
|
| B8
| 184
| ╕
|
| B9
| 185
| ╣
|
| 不是
| 186
| ║
|
| BB
| 187
| ╗
|
| 公元前
| 188
| ╝
|
| 屋宇署
| 189
| ╜
|
| 是
| 190
| ╛
|
| 高炉
| 191
| ┐
|
| C0
| 192
| └
|
| C1
| 193
| ┴
|
| C2
| 194
| ┬
|
| C3
| 195
| υ
|
| C4
| 196
| ─
|
| C5
| 197
| ┼
|
| C6
| 198
| ╞
|
| C7
| 199
| ╟
|
| C8
| 200
| ╚
|
| C9
| 201
| ╔
|
| 十六进制
| 十二月
| 人权委员会
|
|---|
| 那
| 202
| ╩
|
| 炭黑
| 203
| ╦
|
| 抄送
| 204
| ╠
|
| 光盘
| 205
| ═
|
| 这
| 206
| ╬
|
| CF
| 207
| ╧
|
| D0
| 208
| ╨
|
| D1
| 209
| ╤
|
| D2
| 210
| ╥
|
| D3
| 211
| ╙
|
| D4
| 212
| ╘
|
| D5
| 213
| ╒
|
| D6
| 214
| ╓
|
| D7
| 215
| ╫
|
| D8
| 216
| ╪
|
| D9
| 217
| ┘
|
| 和
| 218
| ┌
|
| 屋宇署
| 219
| █
|
| 哥伦比亚特区
| 220
| ▄
|
| 直接差分
| 221
| ▌
|
| 从
| 222
| ▐
|
| 自由度
| 223
| ▀
|
| E0
| 224
| 一个
|
| E1
| 225
| SS
|
| E2
| 226
| 和
|
| E3
| 227
| n
|
| E4
| 228
| 和
|
| E5
| 229
| 和
|
| E6
| 230
| µ
|
| E7
| 231
| 电视
|
| E8
| 232
| F
|
| E9
| 233
| 我
|
| 是的
| 234
| 想法
|
| EB
| 235
| 格
|
| 欧盟
| 236
| ∞
|
| ED
| 237
| f
|
| 电子工程
| 238
| 埃
|
| 十六进制
| 十二月
| 热轧
|
|---|
| 如果
| 239
| ∩
|
| F0
| 240
| ≡
|
| F1
| 241
| ±
|
| F2
| 242
| ≥
|
| F3
| 243
| ≤
|
| F4
| 244
| ⌠
|
| F5
| 245
| ⌡
|
| F6
| 246
| ÷
|
| F7
| 247
| ≈
|
| F8
| 248
| °
|
| F9
| 249
| ∙
|
| 但
| 250
| ·
|
| 脸书
| 251
| √
|
| 足球俱乐部
| 252
| ⁿ
|
| FD
| 253
| ²
|
| 费米
| 254
| ■
|
| FF
| 255
| |
一些常用于表示和存储数据的重要数字系统术语
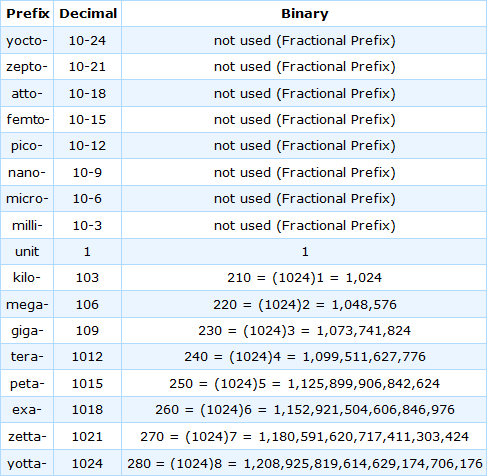
下表列出了用作分数前缀和增多前缀的各种前缀:
字节:
字节最重要的用途是存储字符代码。我们之前讨论过这个问题。
千字节
从技术上讲,1 千字节等于 1024 字节,但它通常被广泛用作 1000 字节的同义词。在十进制中,千等于 1000,但在二进制中,千等于 1024(210)。
千字节通常表示为 K 或 Kb。为了区分十进制的 K(1000)和二进制的 K(1024),IEEE(电气电子工程师协会)标准建议遵循使用小写字母 k 表示十进制千、使用大写字母 K 表示二进制千的惯例,但绝不会严格遵循这一惯例。
兆字节
兆字节用于描述 1,048,576(220)字节的数据存储,但当它用于描述数据传输速度(例如 MB/s)时,它指的是一百万字节。兆字节通常缩写为 M 或 MB。
技嘉
一千兆字节用于描述 1,073,741,824(230)字节的存储,一千兆字节等于 1,024 兆字节。技嘉通常缩写为G或GB。
太字节
1 兆兆字节等于 1,099,511,627,776(240)字节,约为 1 万亿字节。 1 TB 有时被描述为 1012(1,000,000,000,000)字节,正好是一万亿。
PB 级
1PB 等于 1,125,899,906,842,624(250)个字节。 1PB 等于 1,024TB。
艾字节
1 EB 表示为 1,152,921,504,606,846,976(260)个字节。 1艾字节等于1,024拍字节。
泽字节
1 泽字节等于 1,180,591,620,717,411,303,424(270)字节,约为 1021(1,000,000,000,000,000,000,000)字节。 1泽字节 (ZB) 等于 1.024艾字节 (EB)。
尧字节
1 尧字节等于 1,208,925,819,614,629,174,706,176(280)字节,约为 1024(1,000,000,000,000,000,000,000,000)字节。尧字节等于1.024泽字节。
数据存储的一般条款
对于不同的数据位组,前面给出的术语有不同的名称。下表列出了一些最常用的:
| 最后期限
|
位数
|
| 页码 / 号码 / 标志
|
1
|
| 咬 / 咬
|
4
|
| 字节/字符
|
8
|
| 单词
|
16
|
| 双字/长字
|
三十二
|
| 很长的单词
|
64
|