第 5 章
C 语言编程简介
介绍
‘C’是现代计算机世界中最流行的编程语言之一。C 编程语言由 Brian Kernighan 和 Dennis Ritchie 于 1972 年在贝尔研究实验室设计和创建。
“C” 是一种专门设计用来让程序员访问机器的几乎所有内部组件(寄存器、I/O 插槽和绝对地址)的语言。同时,“C”允许尽可能多的数据处理和编程文本模块化,以便能够有组织、及时地构建非常复杂的多编程项目。
尽管该语言最初打算在 UNIX 下运行,但人们对在 IBM PC 及其兼容机上的 MS-DOS 操作系统下运行该语言表现出浓厚的兴趣。由于其表达简单、代码紧凑、适用范围广泛,它是该环境的优秀语言。
此外,由于 C 编译器编写起来简单且容易,它通常是任何新计算机(包括微型计算机、小型计算机和大型机)上可用的第一个高级语言。
为什么在数据恢复编程中使用 C
在当今的计算机编程世界中,有许多高级语言可供使用。这些语言很好,因为它们具有很多适合大多数编程任务的特性。但是,有几个原因可以解释为什么 C 语言成为数据恢复编程、系统编程、设备编程或硬件编程的程序员的首选:
- C 是专业程序员首选的流行语言。因此,有各种各样的 C 编译器和有用的附件可供使用。
- C 是一种可移植语言。为一个计算机系统编写的 C 程序只需进行少量修改甚至不需要修改就可以在另一个系统上编译并运行。 C 语言的 ANSI 标准(一套针对 C 语言编译器的规则)提高了可移植性。
- C 允许在编程中广泛使用模块。C 代码可以写成称为函数的子程序。这些功能可以在其他应用程序或程序中重复使用。在编写新应用程序时,您无需付出额外的努力来创建与您之前在另一个应用程序中开发的相同的模块。
您可以在新程序中使用此功能,无需进行任何更改或只需进行一些小的更改。在数据恢复编程的情况下,当您需要在不同程序的不同应用程序中多次运行相同的功能时,您会发现这种品质非常有用。
- C 是一种强大且灵活的语言。这就是为什么 C 被用于诸如操作系统、文字处理器、图形、电子表格甚至其他语言的编译器等不同的项目。
- C 是一种少词语言,仅包含几个术语,称为关键字,这些术语是构建该语言功能的基础。这些关键字,也称为保留字,使其更加强大并提供了广泛的编程范围,并使程序员觉得有能力用 C 进行任何类型的编程。
我假设你对 C 一无所知。
我假设你对 C 编程一无所知,并且对编程一无所知。我将从 C 语言的最基本概念开始,带您了解高级 C 编程,包括通常令人生畏的指针、结构和动态内存分配概念。
你需要花费大量的时间和精力才能完全理解这些概念,因为它们并不容易理解,但它们是非常强大的工具。
在您可能需要使用汇编语言但希望其易于编写和维护的领域,C 编程是一笔巨大的财富。在这种情况下,使用 C 语言编码可以节省大量时间。
尽管 C 语言在将程序从一种实现移植到另一种实现时有着良好的记录,但是当您尝试使用另一个编译器时,您会发现编译器之间存在差异。
当您使用非标准扩展(例如在使用 MS-DOS 时调用 DOS BIOS)时,大多数差异都会变得明显,但即使是这些差异也可以通过仔细选择编程结构来最小化。
当 C 编程语言明显成为一种可在各种计算机上使用的非常流行的语言时,一群相关人士开会提出了一套使用 C 编程语言的标准规则。
该小组代表了软件行业的所有部门,经过多次会议和多次初步起草,他们最终为 C 语言制定了可接受的标准。它已被美国国家标准协会 (ANSI) 和国际标准组织 (ISO) 接受。
它不会强加于任何团体或用户,但由于它被广泛接受,因此对于任何拒绝遵守该标准的编译器编写者来说,都将是经济自杀。
本书中编写的程序主要用于 IBM-PC 或兼容计算机,但由于它与 ANSI 标准非常接近,因此也可以与任何 ANSI 标准编译器一起使用。
让我们开始吧
在使用任何语言进行任何操作并开始编程之前,您必须知道如何命名标识符。标识符用于任何变量、函数、数据定义等。在 C 编程语言中,标识符是字母数字字符的组合,第一个字符是字母表中的字母或下划线,其余字符是字母表中的任意字母、任意数字或下划线。
命名标识符时必须牢记两个规则。
- 字母的大小写很重要。C 是一种区分大小写的语言。这意味着 Recovery 不同于 recovery,rEcOveRY 也不同于前面提到的两者。
- 根据 ANSI-C 标准,至少可以使用 31 个有效字符,符合 ANSI-C 标准的编译器会将这些字符视为有效字符。如果使用超过 31 个字符,则任何给定编译器都可能会忽略第 31 个字符之后的所有字符。
关键词
在 C 语言中,有 32 个字被定义为关键字。这些字具有预定义的用途,不能在 C 程序中用于任何其他目的。它们被编译器用作编译程序的辅助手段。它们始终以小写形式书写。完整列表如下:
| 汽车 |
休息 |
案件 |
字符 |
| 常量 |
继续 |
默认 |
做 |
| 双倍的 |
别的 |
枚举 |
外部 |
| 漂浮 |
为了 |
转到 |
如果 |
| 整数 |
长的 |
登记 |
返回 |
| 短的 |
已签署 |
大小 |
静止的 |
| 结构 |
转变 |
类型定义 |
联盟 |
| 未签名 |
空白 |
易挥发的 |
尽管 |
这里我们可以看到 C 的魔力。仅32 个关键字的奇妙集合在不同应用中得到了广泛的应用。任何计算机程序都需要考虑两个实体,即数据和程序。它们高度相互依赖,对两者的精心规划可以产生一个精心规划和编写的程序。
让我们从一个简单的 C 程序开始:
/* 学习 C 语言的第一个程序 */
#包括 <stdio.h>
空主()
{
printf("这是一个 C 程序\n"); //打印一条消息
}
虽然这个程序很简单,但有几点值得注意。让我们检查一下上面的程序。/* 和 */ 内的所有内容都被视为注释,将被编译器忽略。您不应在其他注释中包含注释,因此不允许出现以下情况:
/* 这是注释内的/*注释*/,这是错误的*/
还有一种在一行内工作的文档方式。通过使用 //,我们可以在该行内添加小文档。
每个 C 程序都包含一个名为 main 的函数。这是程序的起点。每个函数都应返回一个值。在此程序中,函数 main 不返回任何返回值,因此我们将其写为 void main。我们也可以将此程序写为:
/* 学习 C 语言的第一个程序 */
#包括 <stdio.h>
主要的()
{
printf("这是一个 C 程序\n"); //打印一条消息
返回0;
}
两个程序都相同,执行相同的任务。两个程序的结果都会在屏幕上打印以下输出:
这是一个 C 程序
#include<stdio.h>允许程序与计算机的屏幕、键盘和文件系统进行交互。几乎每个 C 程序的开头都会出现它。
main()声明函数的开始,而两个花括号表示函数的开始和结束。C 中的花括号用于将语句组合在一起,例如在函数中或在循环体中。这种组合称为复合语句或块。
printf("This is a C program\n");在屏幕上打印单词。要打印的文本括在双引号中。文本末尾的 \n 告诉程序打印新行作为输出的一部分。printf() 函数用于监视器显示输出。
大多数 C 程序都是小写字母。大写字母通常用于预处理器定义(稍后将讨论),或作为字符串的一部分放在引号内。
编译程序
假设我们的程序名为 CPROG.C。要输入并编译 C 程序,请按照以下步骤操作:
- 创建 C 程序的活动目录并启动编辑器。为此,可以使用任何文本编辑器,但大多数 C 编译器(如 Borland 的 Turbo C++)都具有集成开发环境 (IDE),可让您在一个方便的设置中输入、编译和链接程序。
- 编写并保存源代码。您应该将文件命名为 CPROG.C。
- 编译并链接 CPROG.C。执行编译器手册中指定的相应命令。您应该会收到一条消息,表明没有错误或警告。
- 检查编译器消息。如果没有收到任何错误或警告,则一切正常。如果在输入程序时出现任何错误,编译器将捕获该错误并显示错误消息。更正错误消息中显示的错误。
- 现在您的第一个 C 程序应该已经编译完毕并可以运行了。如果您显示所有名为 CPROG 的文件的目录列表,您将获得四个具有不同扩展名的文件,如下所示:
- CPROG.C,源代码文件
- CPROG.BAK,您用编辑器创建的源文件的备份文件
- CPROG.OBJ,包含 CPROG.C 的目标代码
- CPROG.EXE,编译和链接 CPROG.C 时创建的可执行程序
- 要执行或运行 CPROG.EXE,只需输入 cprog。屏幕上会显示消息“这是一个 C 程序”。
现在让我们检查以下程序:
/* 学习 C 的第一个程序 */ // 1
// 2
#包括<stdio.h> // 3
// 4
主要() // 5
{
// 6
printf("这是一个 C 程序\n"); // 7
// 8
返回 0; // 9
} // 10
编译该程序时,编译器将显示类似以下内容的消息:
cprog.c(8):错误:预期为“;”
让我们把这个错误信息分成几部分。cprog.c 是发现错误的文件的名称。(8)是发现错误的行号。错误:';' 预期是错误的描述。
此消息非常有用,它告诉您,在 CPROG.C 的第 8 行中,编译器期望找到分号,但未找到。但是,您知道第 7 行实际上省略了分号,因此存在差异。
为什么编译器在第 8 行报告错误,而实际上第 7 行省略了一个分号。答案在于 C 并不关心行间换行之类的事情。printf() 语句后面的分号可以放在下一行,但实际上这样做是错误的编程。
只有在第 8 行遇到下一个命令(return)时,编译器才确定缺少分号。因此,编译器报告错误发生在第 8 行。
错误类型可能有很多种。让我们来讨论一下链接错误消息。链接器错误相对少见,通常是由于 C 库函数名称拼写错误造成的。在这种情况下,您会收到“Error: undefined symbol:”错误消息,后面跟着拼写错误的名称。一旦您纠正拼写,问题就会消失。
打印数字
让我们看下面的例子:
// 如何打印数字 //
#include<stdio.h>
空主()
{
int 数字 = 10;
printf(“ 该数字是 %d”, num);
}
程序的输出将在屏幕上显示如下:
数字是 10
% 符号用于指示多种不同类型变量的输出。% 符号后面的字符是 ad,它指示输出例程获取十进制值并输出。
使用变量
在 C 语言中,变量必须先声明才能使用。变量可以在任何代码块的开头声明,但大多数变量都位于每个函数的开头。大多数局部变量是在调用函数时创建的,并在从该函数返回时销毁。
要在 C 程序中使用变量,在 C 中给变量命名时必须了解以下规则:
- 名称可以包含字母、数字和下划线字符(_)。
- 名称的第一个字符必须是字母。下划线也是合法的第一个字符,但不建议使用。
- C 区分大小写,因此变量名 num 与 Num 不同。
- C 关键字不能用作变量名。关键字是 C 语言的一部分。
以下列表包含一些合法和非法的 C 变量名的示例:
| 变量名称 |
合法与否 |
| 在一个 |
合法的 |
| Ttpt2_t2p |
合法的 |
| 点 |
非法:不允许有空格 |
| _1990_税 |
合法但不建议 |
| Jack_phone# |
非法:包含非法字符# |
| 案件 |
非法:是 C 关键字 |
| 1本书 |
非法:第一个字符是数字 |
第一个引人注目的新内容是 main() 函数主体的第一行:
int 数字 = 10;
此行定义了一个名为“num”的 int 类型变量,并将其初始化为值 10。这也可以写成:
int num; /* 定义未初始化的变量 'num' */
/* 以及所有变量定义之后:*/
num = 10; /* 将值 10 分配给变量 'num' */
变量可以在块的开始处定义(在括号 {and} 之间),通常是在函数体的开始处,但也可以在另一个类型的块的开始处。
在块开头定义的变量默认为“自动”状态。这意味着它们仅在块执行期间存在。当函数执行开始时,将创建变量,但其内容将未定义。当函数返回时,变量将被销毁。定义也可以写成:
自动 int 数量 = 10;
由于带有或不带有auto关键字的定义是完全等效的,因此auto关键字显然是比较多余的。
然而,有时这并不是你想要的。假设你想让一个函数记录它被调用的次数。如果每次函数返回时变量都会被销毁,那么这是不可能的。
因此,可以赋予变量所谓的静态持续时间,这意味着它将在整个程序执行过程中保持不变。例如:
静态 int num = 10;
这会在程序执行开始时将变量 num 初始化为 10。从那时起,该值将保持不变;如果多次调用该函数,则不会重新初始化该变量。
有时,仅从一个函数访问变量是不够的,或者通过参数将值传递给所有需要它的其他函数可能不方便。
但是,如果您需要从整个源文件中的所有函数访问变量,也可以使用 static 关键字来实现,但要将定义放在所有函数之外。例如:
#包括 <stdio.h>
static int num = 10; /* 可从整个源文件访问 */
int main(空)
{
printf("该数字为:%d\n", num);
返回0;
}
还有一些情况需要从整个程序(可能由多个源文件组成)访问某个变量。这称为全局变量,在不需要时应避免使用它。
这也可以通过将定义放在所有函数之外来实现,但不使用 static 关键字:
#包括 <stdio.h>
int num = 10; /* 可从整个程序访问!*/
int main(空)
{
printf("该数字为:%d\n", num);
返回0;
}
还有 extern 关键字,用于访问其他模块中的全局变量。您还可以在变量定义中添加一些限定符。其中最重要的是 const。定义为 const 的变量不能被修改。
还有两个不太常用的修饰符。 volatile 和 register 修饰符。 volatile 修饰符要求编译器每次读取变量时都实际访问该变量。 它可能不会通过将变量放在寄存器中来优化变量。 这主要用于多线程和中断处理目的等。
register 修饰符要求编译器将变量优化到寄存器中。这只适用于自动变量,而且在许多情况下,编译器可以更好地选择要优化到寄存器中的变量,因此此关键字已过时。将变量设为寄存器的唯一直接后果是无法获取其地址。
下一页给出的变量表描述了五种存储类别的存储类别。
在表中,我们看到关键字 extern 被放在两行中。extern 关键字用于在函数中声明在其他地方定义的静态外部变量。
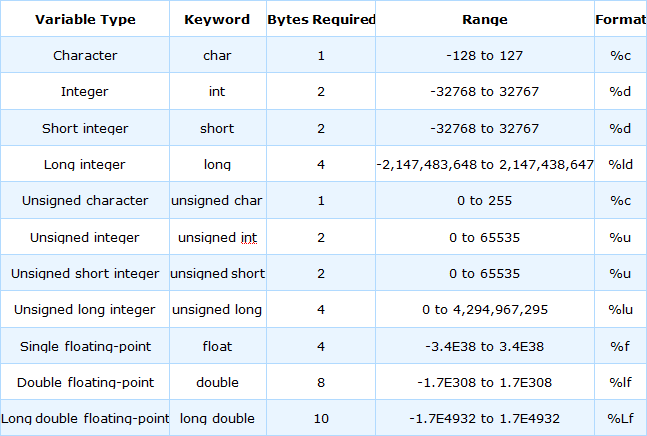
数值变量类型
C 提供了几种不同类型的数值变量,因为不同的数值具有不同的内存存储要求。这些数值类型在执行某些数学运算的难易程度上有所不同。
小整数需要较少的内存来存储,并且您的计算机可以非常快速地对此类数字执行数学运算。大整数和浮点值需要更多的存储空间和更多的数学运算时间。通过使用适当的变量类型,您可以确保您的程序尽可能高效地运行。
C 的数值变量主要分为以下两类:
每个类别中都有两种或多种特定变量类型。下表显示了保存每种类型的单个变量所需的内存量(以字节为单位)。
char 类型可能等同于signed char或unsigned char,但它始终是与这两种类型不同的类型。
在 C 语言中,将字符或其对应的数值存储在变量中没有区别,因此也不需要函数在字符和其数值之间进行转换,反之亦然。对于其他整数类型,如果省略signed或unsigned,则默认为signed,因此例如int和signed int是等效的。
int 类型必须大于或等于 short 类型,并且小于或等于 long 类型。如果您只需要存储一些不是特别大的值,使用 int 类型通常是一个好主意;它通常是处理器最容易处理的大小,因此也是最快的。
对于一些编译器来说,double 和 long double 是等价的。再加上大多数标准数学函数都使用 double 类型,所以如果您必须处理小数,那么始终使用 double 类型就是一个好理由。
下表是为了更好地描述变量类型:
常用的特殊用途类型:
| 变量类型 |
描述 |
| size_t |
无符号类型,用于以字节为单位存储对象的大小 |
| time_t |
用于存储 time() 函数的结果 |
| clock_t |
用于存储clock()函数的结果 |
| 文件 |
用于访问流(通常是文件或设备) |
| ptrdiff_t |
两个指针之间的有符号类型的差异 |
| div_t |
用于存储 div() 函数的结果 |
| ldiv_t |
用于存储ldiv()函数的结果 |
| 位置信息 |
用于保存文件位置信息 |
| will_list |
用于变量参数处理 |
| 字符型 |
宽字符类型(用于扩展字符集) |
| sig_atomic_t |
用于信号处理程序 |
| 跳转缓冲区 |
用于非本地跳跃 |
为了更好地理解这些变量,让我们举一个例子:
/* 程序用于告知 C 变量的范围和大小(以字节为单位) */
#包括 <stdio.h>
int 主要()
{
int a; /* 简单整数类型 */
long int b; /* 长整数类型 */
short int c; /*短整数类型*/
unsigned int d; /* 无符号整数类型 */
char e; /* 字符类型 */
float f; /* 浮点类型 */
double g; /*双精度浮点数*/
a=1023;
b=2222;
c=123;
d=1234;
e = ‘X’;
f=3.14159;
g=3.1415926535898;
printf( "\nA char 为 %d 字节", sizeof( char ));
printf( "\nAn int 为 %d 字节", sizeof( int ));
printf( "\nA short 为 %d 字节", sizeof( short ));
printf( "\nA long 为 %d 字节", sizeof( long ));
printf( "\n无符号字符占 %d 个字节",
sizeof(无符号字符));
printf( "\n无符号整数为 %d 字节",
sizeof(无符号整数));
printf( "\n无符号短整型为 %d 字节",
sizeof(无符号短整型));
printf( "\n无符号长整型为 %d 字节",
sizeof(无符号长整型));
printf( "\nA 浮点数为 %d 字节", sizeof( float ));
printf( "\nA double 为 %d 字节\n", sizeof( double ));
printf("a = %d\n", a); /*十进制输出*/
printf("a = %o\n", a); /* 八进制输出 */
printf("a = %x\n", a); /*十六进制输出 */
printf("b = %ld\n", b); /*十进制长输出*/
printf("c = %d\n", c); /*十进制短输出*/
printf("d = %u\n", d); /* 无符号输出 */
printf("e = %c\n", e); /*字符输出*/
printf("f = %f\n", f); /*浮点输出*/
printf("g = %f\n", g); /*双精度浮点输出*/
打印(“ \ n”);
printf("a = %d\n", a); /* 简单 int 输出 */
printf("a = %7d\n", a); /* 使用字段宽度 7 */
printf("a = %-7d\n", a); /* 左对齐
7 的字段 */
c=5;
d=8;
printf("a = %*d\n", c, a); /*使用 5 的字段宽度*/
printf("a = %*d\n", d, a); /* 使用 8 的字段宽度 */
打印(“ \ n”);
printf("f = %f\n", f); /*简单浮点输出*/
printf("f = %12f\n", f); /* 使用字段宽度 12 */
printf("f = %12.3f\n", f); /* 使用 3 位小数 */
printf("f = %12.5f\n", f); /* 使用 5 位小数 */
printf("f = %-12.5f\n", f); /* 在字段中左对齐 */
返回0;
}
程序执行后的结果将显示为:
一个字符占 1 个字节
int 占 2 个字节
short 占 2 个字节
long 占 4 个字节
无符号字符占 1 个字节
无符号整数占 2 个字节
无符号短整型占 2 个字节
无符号长整型为 4 个字节
浮点数为 4 个字节
双精度数为 8 个字节
a = 1023
a = 1777
a = 3ff
b = 2222
c = 123
d = 1234
e = X
f = 3.141590
g = 3.141593
a = 1023
a = 1023
a = 1023
a = 1023
a = 1023
f = 3.141590
f = 3.141590
f = 3.142
f = 3.14159
f = 3.14159 |
在 C 程序中使用变量之前,必须先声明它。变量声明会告诉编译器变量的名称和类型,并可选择将变量初始化为特定值。
如果程序尝试使用未声明的变量,编译器将生成错误消息。变量声明具有以下形式:
类型名称 变量名称;
typename 指定变量类型,必须是关键字之一。varname 是变量名。您可以在一行中声明多个相同类型的变量,变量名之间用逗号分隔:
int count, number, start; /* 三个整数变量 */
float percent, total; /* 两个浮点变量 */
typedef 关键字
typedef 关键字用于为现有数据类型创建新名称。实际上,typedef 创建了一个同义词。例如,语句
typedef int 整数;
这里我们看到 typedef 创建了 integer 作为 int 的同义词。然后可以使用 integer 定义 int 类型的变量,如下例所示:
整数计数;
因此 typedef 不会创建新的数据类型,它仅允许您对预定义的数据类型使用不同的名称。
初始化数值变量
当声明任何变量时,编译器都会被指示为该变量留出存储空间。但是,存储在该空间中的值(即变量的值)是未定义的。它可能是零,也可能是一些随机的“垃圾”值。在使用变量之前,您应该始终将其初始化为已知值。让我们来看这个例子:
int count; /* 为 count 留出存储空间 */
count = 0; /* 将 0 存储在 count 中 */
此语句使用等号 (=),这是 C 的赋值运算符。您还可以在声明变量时初始化它。为此,请在声明语句中的变量名称后加上等号和所需的初始值:
int 计数 = 0;
双倍率=0.01,复杂度=28.5;
注意不要使用超出允许范围的值初始化变量。以下是两个超出范围的初始化示例:
int 金额 = 100000;
无符号整数长度=-2500;
C 编译器不会捕获此类错误。您的程序可能编译并链接成功,但程序运行时可能会出现意外结果。
让我们通过以下示例来计算磁盘中的扇区总数:
// 计算磁盘扇区的模型程序 //
#include<stdio.h>
#定义每个侧扇区 63
#定义每个气缸的侧面 254
空主()
{
int气缸=0;
clrscr();
printf("请输入磁盘的柱面数\n\n\t");
scanf("%d",&cylinder); // 从用户处获取值 //
printf("\n\n\t 磁盘中的扇区总数 = %ld", (long)SECTOR_PER_SIDE*SIDE_PER_CYLINDER* 柱面);
获取();
}
该程序的输出如下:
输入磁盘的柱面数
1024
磁盘中的扇区总数 = 16386048
在这个例子中,我们看到了三个需要学习的新东西。#define 用于在程序中使用符号常量,或者在某些情况下通过用小符号定义长单词来节省时间。
这里我们将每侧扇区数 63 定义为 SECTOR_PER_SIDE,以使程序易于理解。#define SIDE_PER_CYLINDER 254 也是如此。scanf() 用于获取用户的输入。
这里我们将气缸数作为用户的输入。* 用于乘以两个或多个值,如示例所示。
getch() 函数基本上从键盘获取单个字符输入。通过键入 getch();,我们在这里停止屏幕,直到从键盘上按下任何键。
运算符
运算符是指示 C 对一个或多个操作数执行某些运算或操作的符号。操作数是运算符所作用的对象。在 C 中,所有操作数都是表达式。C 运算符有以下四类:
赋值运算符
赋值运算符是等号 (=)。等号在编程中的使用与在常规数学代数关系中的使用不同。如果你写
x = y;
在 C 程序中,它并不意味着“x 等于 y”。而是意味着“将 y 的值赋给 x”。在 C 赋值语句中,右侧可以是任何表达式,而左侧必须是变量名。因此,格式如下:
变量 = 表达式;
在执行过程中,对表达式进行求值,并将结果值分配给变量。
数学运算符
C 的数学运算符执行加法和减法等数学运算。C 有两个一元数学运算符和五个二元数学运算符。一元数学运算符之所以如此命名,是因为它们只接受一个操作数。C 有两个一元数学运算符。
增量和减量运算符只能用于变量,不能用于常量。执行的操作是将操作数加一或减一。换句话说,语句 ++x; 和 --y; 与以下语句等同:
x=x+1;
y = y-1;
二元数学运算符需要两个操作数。前四个二元运算符包括计算器上常见的数学运算(+、-、*、/),您对此并不陌生。第五个运算符 Modulus 返回第一个操作数除以第二个操作数后的余数。例如,11 模 4 等于 3(11 除以 4,乘以 2,余 3)。
关系运算符
C 的关系运算符用于比较表达式。包含关系运算符的表达式的计算结果为真 (1) 或假 (0)。C 有六个关系运算符。
逻辑运算符
C 的逻辑运算符可让您将两个或多个关系表达式组合成一个表达式,该表达式的计算结果为真或假。逻辑运算符的计算结果为真或假,具体取决于其操作数的真值或假值。
如果 x 是整数变量,则使用逻辑运算符的表达式可以按以下方式编写:
(x > 1)&&(x < 5)
(x >= 2)&&(x <= 4)
| 操作员 |
象征 |
描述 |
例子 |
| 赋值运算符 |
| 平等的 |
= |
将 y 的值赋给 x |
x = y |
| 数学运算符 |
| 增量 |
++ |
将操作数增加一 |
++x,x++ |
| 减少 |
-- |
将操作数减一 |
--x,x-- |
| 添加 |
+ |
添加两个操作数 |
x + y |
| 减法 |
- |
从第一个操作数中减去第二个操作数 |
x - y |
| 乘法 |
* |
将两个操作数相乘 |
x * y |
| 分配 |
/ |
将第一个操作数除以第二个操作数 |
x / y |
| 模量 |
% |
给出第一个操作数除以第二个操作数后的余数 |
x % 和 |
| 关系运算符 |
| 平等的 |
= = |
平等 |
x = = y |
| 大于 |
> |
大于 |
x > y |
| 少于 |
< |
少于 |
x < y |
| 大于或等于 |
>= |
大于或等于 |
x >= y |
| 小于或等于 |
<= |
小于或等于 |
x <= y |
| 不等于 |
!= |
不等于 |
x != y |
| 逻辑运算符 |
| 和 |
&& |
仅当exp1和exp2同时为真时,才为真 (1) ;否则为假 (0) |
表达式1 && 表达式2 |
| 或者 |
|| |
如果exp1或exp2有一个为真,则为真 (1) ;如果两个都为假,则为假 (0) |
表达式1 || 表达式2 |
| 不是 |
! |
如果exp1为真,则为假 (0) ;如果exp1为假,则为真 (1) |
!exp1 |
关于逻辑表达式需要记住的事情
| x * = y |
相同于 |
x = x * y |
| y-=z+1 |
相同于 |
y = y - z + 1 |
| a / = b |
相同于 |
a=a/b |
| x + = y / 8 |
相同于 |
x = x + y / 8 |
| 且 % = 3 |
相同于 |
y = y % 3 |
逗号运算符
逗号在 C 语言中经常用作简单的标点符号,用于分隔变量声明、函数参数等。在某些情况下,逗号充当运算符。
可以用逗号分隔两个子表达式来形成表达式。结果如下:
- 对两个表达式进行求值,首先求左边的表达式。
- 整个表达式的计算结果为正确表达式的值。
例如,以下语句将 b 的值赋给 x,然后增加 a,然后增加 b:x = (a++, b++);
C 运算符优先级(C 运算符摘要)
| 等级和结合性 |
运算符 |
| 1(从左到右) |
()[]->。 |
| 2(从右到左) |
!~++ -- * (间接) & (地址) (类型) sizeof + (一元) - (一元) |
| 3 (从左到右) |
* (乘法) /% |
| 4 (从左到右) |
+ - |
| 5 (从左到右) |
<< >> |
| 6 (从左到右) |
< <= > >= |
| 7 (从左到右) |
= = != |
| 8 (从左到右) |
& (按位与) |
| 9 (从左到右) |
^ |
| 10(从左到右) |
| |
| 11(从左到右) |
&& |
| 12(从左到右) |
|| |
| 13(从右到左) |
?: |
| 14(从右到左) |
= += -= *= /= %= &= ^= |= <<= >>= |
| 15(从左到右) |
, |
| ()是函数运算符;[]是数组运算符。 |
|
让我们举一个使用运算符的例子:
/* 操作符的使用 */
int 主要()
{
int x = 0,y = 2,z = 1025;
浮点数a = 0.0,b = 3.14159,c = -37.234;
/* 递增 */
x = x + 1; /* 这会使 x 增加 */
x++; /* 这会使 x 增加 */
++x; /* 这会使 x 增加 */
z = y++; /*z = 2,y = 3*/
z = ++y; /*z = 4,y = 4*/
/* 减少 */
y = y - 1; /* 这会使 y 减少 */
y--; /* 这会使 y 减少 */
--y; /* 这会使 y 减少 */
y=3;
z = y--; /*z = 3,y = 2*/
z = --y; /*z = 1,y = 1*/
/* 算术运算 */
a = a + 12; /*这将 a 加 12*/
a += 12; /*这会将 a 加 12 */
a *= 3.2; /* 将 a 乘以 3.2 */
a -= b; /* 从 a 中减去 b */
a /= 10.0; /* 将 a 除以 10.0 */
/* 条件表达式 */
a = (b >= 3.0 ? 2.0 : 10.5 ); /* 这个表达式 */
if (b >= 3.0) /* 并且这个表达式 */
a = 2.0; /* 相同,两者 */
else /* 也会导致同样的结果 */
a = 10.5; /*结果。*/
c = (a > b ? a : b); /* c 将具有 a 或 b 中的最大值 */
c = (a > b ? b : a); /* c 将具有 a 或 b 中的最小值 */
printf("x=%d,y=%d,z=%d\n", x, y, z);
printf("a=%f,b=%f,c=%f",a,b,c);
返回0;
}
该程序的运行结果将在屏幕上显示如下:
x=3,y=1,z=1
a=2.000000,b=3.141590,c=2.000000
有关 printf() 和 Scanf() 的更多信息
考虑以下两个 printf 语句
printf(“\t %d\n”,num);
printf(“%5.2f”,分数);
在第一个 printf 语句中, \t 请求屏幕上的制表符位移,参数 %d 告诉编译器 num 的值应该以十进制整数形式打印。\n 导致新的输出从新行开始。
在第二个 printf 语句中,%5.2f 告诉编译器输出必须是浮点数,总共有五位,小数点右边有两位。下表显示了有关反斜杠字符的更多信息:
| 持续的 |
意义 |
| '\一个' |
声音警报(铃声) |
| ‘\b’ |
退格键 |
| ‘\f’ |
换页 |
| ‘\n’ |
新行 |
| ‘\r’ |
回车符 |
| ‘\t’ |
水平标签 |
| ‘\v’ |
垂直标签 |
| ‘\’’ |
单引号 |
| “\”” |
双引号 |
| ‘\?’ |
问号 |
| ‘\\’ |
反斜杠 |
| ‘\0’ |
无效的 |
让我们考虑以下 scanf 语句
scanf(“%d”,&num);
scanf函数接收键盘的数据,上面的格式中,每个变量名前的&(&符号)是指定变量名地址的运算符。
这样,执行就会停止并等待输入变量 num 的值。当输入整数值并按下回车键时,计算机将继续执行下一个语句。scanf 和 printf 格式代码如下表所示:
| 代码 |
读... |
| %c |
单个字符 |
| %日 |
十进制整数 |
| %和 |
浮点值 |
| %f |
浮点值 |
| %克 |
浮点值 |
| %小时 |
短整数 |
| %我 |
十进制、十六进制或八进制整数 |
| %这 |
八进制整数 |
| %s |
细绳 |
| %在 |
无符号十进制整数 |
| %x |
十六进制整数 |
控制语句
程序由许多语句组成,这些语句通常按顺序执行。如果我们可以控制语句的运行顺序,程序的功能就会更加强大。
语句一般分为三类:
- 赋值,将值(通常是计算的结果)存储在变量中。
- 输入/输出,数据被读入或打印出。
- 控制,程序决定下一步做什么。
本节将讨论 C 语言中控制语句的使用。我们将展示如何使用它们来编写强大的程序;
- 重复程序的重要部分。
- 在程序的可选部分之间进行选择。
if else 语句
这用于决定是否在特殊点做某事,或在两种行动方案之间做出决定。
以下测试决定学生是否通过了 45 分的考试
if (结果 >= 45)
printf("通过\n");
别的
printf("失败\n");
可以只使用 if 部分而不使用 else。
如果(温度 < 0)
打印(“冻结\n”);
每个版本都包含一个测试,位于 if 后面的括号语句中。如果测试为真,则执行下一个语句。如果为假,则执行 else 后面的语句(如果存在)。此后,程序的其余部分照常继续。
如果我们希望在 if 或 else 后面有多个语句,则应将它们组合在花括号内。这样的组合称为复合语句或块。
if (结果 >= 45)
{ printf("已通过\n");
printf("恭喜\n");
}
别的
{ printf("失败\n");
printf("下次祝你好运\n");
}
有时我们希望根据多种条件做出多向决策。最常用的方法是使用 if 语句中的 else if 变体。
这是通过级联多个比较来实现的。一旦其中一个给出真结果,就会执行以下语句或块,并且不再执行其他比较。在下面的例子中,我们根据考试结果授予成绩。
if (结果 <= 100 && 结果 >= 75)
printf("通过:A级\n");
else if (结果 >= 60)
printf("通过:B级\n");
else if (结果 >= 45)
printf("通过:C 级\n");
别的
printf("失败\n");
在此示例中,所有比较都测试一个名为 result 的变量。在其他情况下,每个测试可能涉及不同的变量或一些测试组合。可以使用更多或更少的 else if 来使用相同的模式,并且可以省略最后的 else。
程序员需要为每个编程问题设计正确的结构。为了更好地理解 if else 的用法,让我们看一个例子
#包括 <stdio.h>
int 主要()
{
int 数字;
对于(数字 = 0;数字 < 10;数字 = 数字 + 1)
{
如果 (数字 == 2)
printf("num 现在等于 %d\n", num);
如果 (数字 < 5)
printf("num现在为%d,小于5\n",num);
别的
printf("num现在为%d,大于4\n",num);
} /* for 循环结束 */
返回0;
}
计划结果
num 现在为 0,小于 5
num 现在是 1,小于 5
num 现在等于 2
num 现在是 2,小于 5
num 现在是 3,小于 5
num 现在是 4,小于 5
num 现在是 5,大于 4
num 现在是 6,大于 4
num 现在是 7,大于 4
num 现在是 8,大于 4
num 现在是 9,大于 4
switch 语句
这是多路决策的另一种形式。它结构良好,但只能在某些情况下使用;
- 仅测试一个变量,所有分支必须依赖于该变量的值。变量必须是整数类型。(int、long、short 或 char)。
- 变量的每个可能值都可以控制单个分支。可以选择使用最终的、捕获所有情况的默认分支来捕获所有未指定的情况。
下面给出的例子将阐明这一点。这是一个将整数转换为模糊描述的函数。当我们只关心测量非常小的数量时,它很有用。
估计(数字)
整数;
/* 将数字估计为无、一、二、几个、很多 */
{ 开关(数字){
案例 0:
printf("无\n");
休息;
案例 1:
printf("一\n");
休息;
案例2:
printf("二\n");
休息;
案例3:
案例4:
案例5:
printf("几个\n");
休息;
默认 :
printf("许多\n");
休息;
}
}
每个有趣的案例都列出了相应的操作。 break 语句通过退出 switch 来阻止执行任何进一步的语句。由于 case 3 和 case 4 没有后续 break,因此它们继续允许对多个 number 值执行相同的操作。
if 和 switch 结构都允许程序员从多个可能的操作中进行选择。让我们看一个例子:
#包括 <stdio.h>
int 主要()
{
int 数字;
对于(数字 = 3;数字 < 13;数字 = 数字 + 1)
{
开关(数量)
{
案例3:
printf("值为三\n");
休息;
案例4:
printf("值为四\n");
休息;
案例5:
案例6:
案例7:
案例8:
printf("该值介于5至8之间\n");
休息;
案例11:
printf("值为 11\n");
休息;
默认 :
printf("它是未定义的值之一\n");
休息;
} /* 开关结束 */
} /* for 循环结束 */
返回0;
}
该程序的输出将是
值为三
值为 4
值介于 5 到 8 之间
值介于 5 到 8 之间
值介于 5 到 8 之间
值介于 5 到 8 之间
这是未定义的值之一
这是未定义的值之一
值为 11
这是未定义的值之一
break 语句
在讨论 switch 语句时,我们已经见过 break。它用于退出循环或 switch,将控制权传递给循环或 switch 之外的第一个语句。
对于循环,break 可用于强制提前退出循环,或实现带有测试的循环以在循环体中间退出。循环内的 break 应始终在 if 语句内进行保护,该语句提供测试来控制退出条件。
continue 语句
这与 break 类似,但不太常见。它只在循环内起作用,其效果是强制立即跳转到循环控制语句。
- 在while循环中,跳转到测试语句。
- 在 do while 循环中,跳转到测试语句。
- 在 for 循环中,跳转到测试,并执行迭代。
和 break 一样,continue 也应该用 if 语句保护。你不太可能经常使用它。为了更好地理解 break 和 continue 的用法,让我们检查以下程序:
#包括 <stdio.h>
int 主要()
{
int 值;
对于(值 = 5;值 < 15;值 = 值 + 1)
{
如果(值 == 8)
休息;
printf("在中断循环中,值现在是 %d\n", value);
}
对于(值 = 5;值 < 15;值 = 值 + 1)
{
如果(值 == 8)
继续;
printf("在继续循环中,值现在为 %d\n", value);
}
返回0;
}
该程序的输出如下:
在 break 循环中,值现在是 5
在 break 循环中,值现在是 6
在 break 循环中,值现在是 7
在继续循环中,值现在为 5
在继续循环中,值现在为 6
在继续循环中,值现在为 7
在继续循环中,值现在为 9
在继续循环中,值现在为 10
在继续循环中,值现在为 11
在继续循环中,值现在为 12
在继续循环中,值现在为 13
在继续循环中,值现在是 14
循环
另一种主要的控制语句是循环。循环允许重复一个语句或语句块。计算机非常擅长多次重复简单的任务。循环是 C 实现这一点的方式。
C 提供了三种循环类型供您选择:while、do-while 和 for。
- while 循环不断重复某个操作,直到相关测试返回 false。当程序员事先不知道循环将遍历多少次时,这很有用。
- do while 循环与之类似,但测试发生在循环体执行之后。这确保循环体至少运行一次。
- for 循环使用频率很高,通常用于循环遍历固定次数的情况。它非常灵活,新手程序员应注意不要滥用它提供的功能。
while 循环
while 循环重复一个语句,直到顶部的测试被证明为假。例如,这是一个返回字符串长度的函数。请记住,字符串表示为以空字符“\0”结尾的字符数组。
int string_length(char string[])
{ int i = 0;
while (string[i] != '\0')
我++;
返回(i);
}
字符串作为参数传递给函数。数组的大小未指定,函数适用于任何大小的字符串。
while 循环用于逐个查找字符串中的字符,直到找到空字符。然后退出循环并返回空字符的索引。
当字符不为空时,索引将递增并重复测试。稍后我们将深入研究数组。让我们看一个 while 循环的示例:
#包括 <stdio.h>
int 主要()
{
int 计数;
计数=0;
while (计数 < 6)
{
printf("count 的值为 %d\n", count);
计数=计数+1;
}
返回0;
}
结果显示如下:
count 的值为 0
count 的值为 1
count 的值为 2
count 的值为 3
count 的值为 4
count 的值为 5
do while 循环
这与 while 循环非常相似,只是测试发生在循环体的末尾。这保证了循环在继续之前至少执行一次。
此类设置经常用于读取数据。然后测试验证数据,如果不可接受,则循环返回再次读取。
做
{
printf("输入 1 表示是,输入 0 表示否:");
scanf("%d",&输入值);
} 当(输入值!= 1 && 输入值!= 0)
为了更好地理解 do while 循环,让我们看下面的例子:
#包括 <stdio.h>
int 主要()
{
int 我;
我=0;
做
{
printf("i 的值现在是 %d\n", i);
i=i+1;
} 虽然 (i < 5);
返回0;
}
程序运行结果显示如下:
i 的值现在是 0
i 的值现在是 1
i 的值现在是 2
i 的值现在是 3
i 的值现在是 4
for 循环
for 循环在循环开始前已知循环迭代次数的情况下效果很好。循环头由三部分组成,三部分之间用分号隔开。
- 第一个在进入循环之前运行。这通常是循环变量的初始化。
- 第二个是测试,当返回 false 时退出循环。
- 第三个是每次循环体完成时运行的语句。这通常是循环计数器的增量。
该示例是一个计算数组中存储的数字的平均值的函数。该函数以数组和元素数量作为参数。
浮点平均值(浮点数组[],整数计数)
{
浮点总数=0.0;
int 我;
对于(i = 0;i < 计数;i++)
总计 += 数组[i];
返回(总数/数量);
}
for 循环确保在计算平均值之前添加正确数量的数组元素。
for 循环开头的三个语句通常每个只执行一项操作,但是其中任何一个都可以留空。第一个或最后一个语句为空意味着没有初始化或运行增量。空白比较语句将始终被视为真。这将导致循环无限期运行,除非通过其他方式中断。这可能是 return 或 break 语句。
也可以将多个语句挤到第一个或第三个位置,用逗号分隔它们。这样就可以使用多个控制变量的循环。下面的示例说明了这种循环的定义,变量 hi 和 lo 分别从 100 和 0 开始并收敛。
for 循环提供了多种简写形式。请注意以下表达式,在此表达式中,单个循环包含两个 for 循环。这里 hi-- 与 hi = hi - 1 相同,lo++ 与 lo = lo + 1 相同,
对于(hi = 100,lo = 0;hi >= lo;hi--,lo++)
for 循环非常灵活,可以简单快速地指定多种类型的程序行为。让我们看一个 for 循环的例子
#包括 <stdio.h>
int 主要()
{
int索引;
对于(索引 = 0;索引 < 6;索引 = 索引 + 1)
printf("索引的值为 %d\n", index);
返回0;
}
程序运行结果显示如下:
索引的值为 0
索引的值为 1
该索引的值为 2
该指数的值为 3
该索引的值为 4
该指数的值为 5
goto 语句
C 语言有一个 goto 语句,允许进行非结构化跳转。要使用 goto 语句,只需使用保留字 goto,后跟要跳转到的符号名称。然后将名称放在程序中的任何位置,后跟冒号。您可以在函数内跳转到几乎任何地方,但不允许跳转到循环,尽管可以跳出循环。
这个特定的程序确实很乱,但它很好地说明了为什么软件编写者试图尽可能地消除 goto 语句的使用。在这个程序中,唯一合理使用 goto 的地方是程序一次跳出三个嵌套循环的地方。在这种情况下,设置一个变量并依次跳出三个嵌套循环会相当混乱,但一个 goto 语句可以非常简洁地让您跳出所有三个循环。
有些人说 goto 语句在任何情况下都不应该使用,但这是狭隘的想法。如果在某个地方 goto 显然比其他构造的控制流更简洁,那么请随意使用它,因为它在显示器上程序的其余部分中。让我们看一个例子:
#包括 <stdio.h>
int 主要()
{
int 狗,猫,猪;
转到real_start;
某处:
printf("这又是一行乱麻。\n");
转到停止;
/* 以下部分是唯一具有可用 goto 的部分 */
实际开始:
对于(狗 = 1 ; 狗 < 6 ; 狗 = 狗 + 1)
{
对于(cat = 1;cat < 6;cat = cat + 1)
{
对于(猪 = 1 ; 猪 < 4 ; 猪 = 猪 + 1)
{
printf("狗 = %d 猫 = %d 猪 = %d\n", 狗, 猫, 猪);
如果 ((狗 + 猫 + 猪) > 8) 则转到足够;
}
}
}
足够:printf(“这些动物现在已经足够了。\n”);
/* 这是本节的结尾,其中包含可用的 goto 语句 */
printf("\n这是代码的第一行。\n");
去那里;
在哪里:
printf("这是代码的第三行。\n");
去往某处;
那里:
printf("这是代码的第二行。\n");
去哪里;
停止:
printf("这是乱七八糟的最后一行。\n");
返回0;
}
让我们看看显示的结果
狗 = 1 猫 = 1 猪 = 1
狗 = 1 猫 = 1 猪 = 2
狗 = 1 猫 = 1 猪 = 3
狗 = 1 猫 = 2 猪 = 1
狗 = 1 猫 = 2 猪 = 2
狗 = 1 猫 = 2 猪 = 3
狗 = 1 猫 = 3 猪 = 1
狗 = 1 猫 = 3 猪 = 2
狗 = 1 猫 = 3 猪 = 3
狗 = 1 猫 = 4 猪 = 1
狗 = 1 猫 = 4 猪 = 2
狗 = 1 猫 = 4 猪 = 3
狗 = 1 猫 = 5 猪 = 1
狗 = 1 猫 = 5 猪 = 2
狗 = 1 猫 = 5 猪 = 3
现在这些动物已经足够了。
这是代码的第一行。
这是代码的第二行。
这是代码的第三行。
这又是一行乱麻。
这是这场混乱的最后一行。
指针
有时我们想知道变量在内存中的位置。指针包含具有特定值的变量的地址。声明指针时,在指针名称前立即放置一个星号。
通过在变量名前面放置一个“&”符号,可以找到存储变量的内存位置的地址。
int num; /* 普通整数变量 */
int *numPtr; /* 指向整型变量的指针 */
下面的示例打印变量值和该变量在内存中的地址。
printf("值 %d 存储在地址 %X\n", num, &num);
要将变量 num 的地址分配给指针 numPtr,请分配变量 num 的地址,如下例所示:
numPtr = #num;
要找出 numPtr 指向的地址中存储的内容,需要取消引用该变量。使用声明指针的星号可以实现取消引用。
printf("值 %d 存储在地址 %X\n", *numPtr, numPtr);
程序中的所有变量都驻留在内存中。下面的语句要求编译器在 32 位计算机上为浮点变量 x 保留 4 个字节的内存,然后将值 6.5 放入其中。
浮点数x;
x = 6.5;
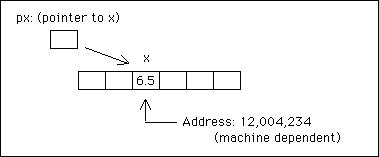
由于任何变量在内存中的地址位置都是通过在其名称前放置运算符 & 获得的,因此 &x 是 x 的地址。C 允许我们更进一步定义一个变量,称为指针,其中包含其他变量的地址。我们可以说指针指向其他变量。例如:
浮点数x;
浮动*像素;
x = 6.5;
像素 = &x;
将 px 定义为指向 float 类型对象的指针,并将其设置为 x 的地址。因此,*px 指的是 x 的值:
让我们来研究一下以下说法:
int var_x;
int*ptrX;
其中_x = 6;
ptrX = &var_x;
*ptrX = 12;
printf("x 的值:%d",var_x);
第一行让编译器在内存中为整数保留一个空间。第二行告诉编译器保留空间来存储指针。
指针是地址的存储位置。第三行应该让你想起 scanf 语句。地址“&”运算符告诉编译器转到它存储 var_x 的位置,然后将存储位置的地址提供给 ptrX。
变量前面的星号 * 告诉编译器取消引用指针,并转到内存。然后,您可以对存储在该位置的变量进行赋值。您可以引用变量并通过指针访问其数据。让我们看一个指针的例子:
/* 指针使用的说明 */
#包括 <stdio.h>
int 主要()
{
int 索引,*pt1,*pt2;
index = 39; /* 任意数值 */
pt1 = &index; /*索引的地址*/
pt2=pt1;
printf("值为 %d %d %d\n", index, *pt1, *pt2);
*pt1 = 13; /*这会改变索引的值*/
printf("值为 %d %d %d\n", index, *pt1, *pt2);
返回0;
}
程序的输出将显示如下:
该值为 39 39 39
该值为 13 13 13
让我们看另一个例子来更好地理解指针的使用:
#包括 <stdio.h>
#include <string.h>
int 主要()
{
char strg[40],*那里,一,二;
int *pt,列表[100],索引;
strcpy(strg, "这是一个字符串。");
/* 函数 strcpy() 用于将一个字符串复制到另一个字符串。我们稍后会在字符串部分阅读有关 strcpy() 函数的内容 */
one = strg[0]; /*one 和 two 相同 */
二 = *ctrl;
printf("第一个输出是 %c %c\n", one, two);
one = strg[8]; /*一和二相同*/
二 = *(ctrl+8);
printf("第二个输出是 %c %c\n", one, two);
那里=ctrl+10; /* strg+10 与 &strg[10] 相同 */
printf("第三个输出是%c\n", strg[10]);
printf("第四个输出是 %c\n", *there);
对于(索引 = 0;索引 < 100;索引++)
列表[索引] = 索引 + 100;
pt=列表+27;
printf("第五个输出为 %d\n", list[27]);
printf("第六个输出为%d\n", *pt);
返回0;
}
该程序的输出将会像这样:
第一个输出是TT
第二个输出是aa
第三个输出是c
第四个输出是c
第五个输出是127
第六个输出是127
数组
数组是同一类型变量的集合。单个数组元素由整数索引标识。在 C 语言中,索引从零开始,并且始终写在方括号内。
我们已经见过像这样声明的单维数组
int 结果[20];
数组可以有更多维度,在这种情况下,它们可以声明为
int 结果_2d[20][5];
int 结果_3d[20][5][3];
每个索引都有自己的一组方括号。数组在主函数中声明,通常包含维度的详细信息。可以使用另一种称为指针的类型代替数组。这意味着维度不是立即固定的,但可以根据需要分配空间。这是一种高级技术,仅在某些专门的程序中才需要。
举个例子,这里有一个简单的函数,用于将一维数组中的所有整数相加。
int add_array(int 数组[],int 大小)
{
int 我;
int总计=0;
对于(i = 0;i < 大小;i++)
总计 += 数组[i];
返回(总计);
}
接下来给出的程序将创建一个字符串,访问其中的一些数据,并将其打印出来。再次使用指针访问它,然后打印出字符串。它应该在不同的行上打印“Hi!”和“012345678”。让我们看看程序的代码:
#包括 <stdio.h>
#定义 STR_LENGTH 10
空主()
{
字符 Str[STR_LENGTH];
字符*pStr;
int 我;
Str[0] = 'H';
Str[1] = ‘我’;
Str[2] = '!';
Str[3] = '\0'; // 特殊字符串结束字符 NULL
printf("Str 中的字符串是:%s\n", Str);
pStr = &Str[0];
对于(i = 0;i < STR_LENGTH;i++)
{
*pStr = '0'+i;
Str++;
}
Str[STR_LENGTH-1] = '\0';
printf("Str 中的字符串是:%s\n", Str);
}
[](方括号)用于声明数组。程序 char Str[STR_LENGTH]; 行声明了一个包含十个字符的数组。这些是十个单独的字符,它们都放在内存中的同一个位置。它们都可以通过我们的变量名 Str 以及 [n] 来访问,其中 n 是元素编号。
讨论数组时应始终牢记,当 C 声明一个包含 10 个元素的数组时,可以访问的元素编号为 0 到 9。访问第一个元素相当于访问第 0 个元素。因此,对于数组,计数始终从 0 到数组大小 - 1。
接下来请注意,我们将字母“Hi!”放入数组中,但随后我们放入一个“\0”,您可能想知道这是什么。“\0”代表 NULL,表示字符串的结尾。所有字符串都需要以这个特殊字符“\0”结尾。如果不这样做,然后有人在字符串上调用 printf,则 printf 将从字符串的内存位置开始,并继续打印,直到它遇到“\0”,因此您将在字符串末尾得到一堆垃圾。因此,请确保正确终止字符串。
字符数组
字符串常量,例如
“我是一根绳子”
是一个字符数组。它在 C 语言内部用字符串中的 ASCII 字符表示,即“I”、空白、“a”、“m”……或上述字符串,并以特殊空字符“\0”结尾,以便程序可以找到字符串的结尾。
字符串常量通常用于使使用 printf 的代码输出更易于理解:
printf("你好,世界\n");
printf("a的值为:%f\n", a);
字符串常量可以与变量关联。C 提供字符类型变量,每次可包含一个字符(1 个字节)。字符串存储在字符类型数组中,每个位置一个 ASCII 字符。
永远不要忘记,由于字符串通常以空字符“\0”终止,因此我们需要数组中一个额外的存储位置。
C 不提供任何一次性操作整个字符串的运算符。字符串是通过指针或标准字符串库 string.h 中提供的特殊例程来操作的。
使用字符指针相对容易,因为数组的名称只是指向其第一个元素的指针。考虑下面给出的程序:
#include<stdio.h>
空主()
{
字符文本_1 [100],文本_2 [100],文本_3 [100];
字符 *ta,*tb;
int 我;
/* 将消息设置为数组 */
/* 字符;初始化它 */
/* 到常量字符串“...” */
/* 让编译器决定 */
/* 使用 [] 来调整大小 */
char message[] = “你好,我是一个字符串;什么是
你?”;
printf("原始消息:%s\n", message);
/* 将消息复制到 text_1 */
我=0;
当((text_1 [i] = 消息[i])!='\0')
我++;
printf("文本1: %s\n",文本1);
/* 使用显式指针算法 */
你的留言;
tb=文本_2;
当((* tb ++ = * ta ++)!='\0')
;
printf("文本2: %s\n",文本2);
}
该程序的输出如下:
原消息:你好,我是字符串;你是什么?
Text_1:你好,我是字符串;你是什么?
Text_2:你好,我是字符串;你是什么?
标准的“字符串”库包含许多操作字符串的有用函数,我们将在后面的字符串部分学习。
访问元素
要访问数组中的单个元素,索引号应位于方括号中的变量名称后面。然后,该变量可以像 C 中的任何其他变量一样处理。以下示例将值赋给数组中的第一个元素。
x[0] = 16;
下面的示例打印数组中第三个元素的值。
printf("%d\n", x[2]);
下面的示例使用 scanf 函数将键盘上的值读入一个包含十个元素的数组的最后一个元素中。
scanf("%d",&x[9]);
初始化数组元素
数组可以像任何其他变量一样通过赋值进行初始化。由于数组包含多个值,因此各个值放在花括号中,并用逗号分隔。以下示例使用三乘法表的前十个值初始化一个十维数组。
int x[10] = {3, 6, 9, 12, 15, 18, 21, 24, 27, 30};
这样就节省了单独分配值的步骤,如以下示例所示。
int x[10];
x[0] = 3;
x[1] = 6;
x[2] = 9;
x[3] = 12;
x[4] = 15;
x[5] = 18;
x[6] = 21;
x[7] = 24;
x[8] = 27;
x[9] = 30;
循环遍历数组
由于数组是按顺序索引的,我们可以使用 for 循环显示数组的所有值。以下示例显示数组的所有值:
#包括 <stdio.h>
int 主要()
{
int x[10];
int 计数器;
/* 随机化随机数生成器 */
srand((无符号)时间(NULL));
/* 为变量分配随机值 */
对于(计数器=0;计数器<10;计数器++)
x[计数器] = rand();
/*显示数组的内容*/
对于(计数器=0;计数器<10;计数器++)
printf("元素 %d 的值为 %d\n", counter, x[counter]);
返回0;
}
尽管输出每次都会打印不同的值,但结果将显示如下内容:
元素 0 的值为 17132
元素 1 的值为 24904
元素 2 的值为 13466
元素 3 的值为 3147
元素 4 的值为 22006
元素 5 的值为 10397
元素 6 的值为 28114
元素 7 的值为 19817
元素 8 的值为 27430
元素 9 的值为 22136
多维数组
数组可以有多个维度。允许数组有多个维度可以提供更大的灵活性。例如,电子表格建立在二维数组上;一个数组表示行,另一个数组表示列。
以下示例使用具有两行、每行包含五列的二维数组:
#包括 <stdio.h>
int 主要()
{
/* 声明一个 2 x 5 多维数组 */
int x[2][5] = { {1, 2, 3, 4, 5},
{2,4,6,8,10}};
int 行,列;
/* 显示行 */
对于(行=0;行<2;行++)
{
/* 显示列 */
对于(列=0;列<5;列++)
printf("%d\t", x[行][列]);
放置字符('\n');
}
返回0;
}
该程序的输出将显示如下:
1 2 3 4 5
2 4 6 8 10
字符串
字符串是一组字符,通常是字母表中的字母,为了格式化您的打印显示,使其看起来美观,具有有意义的名称和标题,并且对您和使用您的程序输出的人来说具有美感。
事实上,在前面的主题的例子中,你已经使用过字符串了。但这并不是对字符串的完整介绍。在编程中有很多可能的情况,使用格式化字符串可以帮助程序员避免程序中过多的复杂性,当然也避免过多的错误。
字符串的完整定义是一系列以空字符('\0')终止的字符类型数据。
当 C 要以某种方式使用一串数据时,无论是将其与另一个字符串进行比较、输出它、将其复制到另一个字符串还是其他什么,这些函数都会被设置为执行它们被调用要做的事情,直到检测到空值。
C 中没有字符串的基本数据类型,相反,C 中的字符串被实现为字符数组。例如,要存储名称,您可以声明一个足够大的字符数组来存储名称,然后使用适当的库函数来操作名称。
以下示例在屏幕上显示用户输入的字符串:
#包括 <stdio.h>
int 主要()
{
char name[80]; /*创建一个字符数组
被叫名称 */
printf("请输入您的姓名:");
获取(名称);
printf("您输入的名字是 %s\n", name);
返回0;
}
程序的执行将是:
输入您的姓名:Tarun Tyagi
您输入的姓名是Tarun Tyagi
一些常见的字符串函数
标准 string.h 库包含许多用于操作字符串的有用函数。这里列举了一些最有用的函数。
strlen 函数
strlen 函数用于确定字符串的长度。让我们通过示例来学习 strlen 的用法:
#包括 <stdio.h>
#include <string.h>
int 主要()
{
字符名称[80];
int长度;
printf("请输入您的姓名:");
获取(名称);
长度 = strlen(名称);
printf("您的名字有%d个字符\n", length);
返回0;
}
程序执行如下:
输入您的姓名:Tarun Subhash Tyagi
您的姓名有19 个字符
输入您的姓名:Preeti Tarun
您的姓名有12 个字符
strcpy 函数
strcpy 函数用于将一个字符串复制到另一个字符串。让我们通过示例来学习此函数的用法:
#包括 <stdio.h>
#include <string.h>
int 主要()
{
字符第一[80];
字符秒[80];
printf("请输入第一个字符串:");
得到(第一);
printf("输入第二个字符串:");
得到(第二);
printf("第一个:%s,第二个:%s 在 strcpy() 之前\n "
、第一、第二);
strcpy(第二,第一);
printf("第一个: %s,第二个: %s 在 strcpy() 之后\n",
第一,第二);
返回0;
}
程序的输出如下:
输入第一个字符串:Tarun
输入第二个字符串:Tyagi
首先:Tarun,然后:Tyagi在 strcpy() 之前
第一个:Tarun,第二个:Tarun在 strcpy() 之后
strcmp 函数
strcmp 函数用于比较两个字符串。数组的变量名指向该数组的基地址。因此,如果我们尝试使用以下方法比较两个字符串,我们将比较两个地址,这两个地址显然永远不会相同,因为不可能将两个值存储在同一个位置。
if (first == second) /* 永远无法比较字符串 */
下面的示例使用 strcmp 函数比较两个字符串:
#include <string.h>
int 主要()
{
字符第一[80],第二[80];
int;
对于(t = 1;t <= 2;t ++)
{
printf("\n请输入一个字符串: ");
得到(第一);
printf("请输入另一个字符串:");
得到(第二);
如果 (strcmp (第一,第二) == 0)
puts("两个字符串相等");
别的
puts("两个字符串不相等");
}
返回0;
}
程序执行如下:
输入一个字符串:Tarun
输入另一个字符串:tarun
两个字符串不相等
输入一个字符串:Tarun
输入另一个字符串:Tarun
两个字符串相等
strcat 函数
strcat 函数用于将一个字符串连接到另一个字符串。让我们看看如何操作?借助示例:
#include <string.h>
int 主要()
{
字符第一[80],第二[80];
printf("请输入一个字符串:");
得到(第一);
printf("请输入另一个字符串:");
得到(第二);
strcat(第一,第二);
printf("两个字符串连接在一起:%s\n",
第一的);
返回0;
}
程序执行如下:
输入一个字符串:Data
输入另一个字符串:Recovery
两个字符串连接在一起:DataRecovery
strtok 函数
strtok 函数用于查找字符串中的下一个标记。标记由可能的分隔符列表指定。
以下示例从文件中读取一行文本,并使用分隔符、空格、制表符和换行符确定单词。然后每个单词显示在单独的行上:
#包括 <stdio.h>
#include <string.h>
int 主要()
{
文件*在;
字符行[80];
char *分隔符 = " \t\n";
字符*标记;
如果((in = fopen(“C:\\text.txt”,“r”))== NULL)
{
puts("无法打开输入文件");
返回0;
}
/* 每次读取一行 */
while(!feof(in))
{
/* 获取一行 */
fgets(行,80,输入);
如果(!feof(in))
{
/* 将行拆分成单词 */
token = strtok(行号,分隔符);
当(标记!= NULL)
{
放入 (令牌);
/* 获取下一个单词 */
令牌 = strtok (NULL,分隔符);
}
}
}
fclose(在);
返回0;
}
上面的程序 in = fopen("C:\\text.txt", "r") 打开现有文件 C:\\text.txt。如果在指定路径中不存在或由于任何原因无法打开该文件,则屏幕上会显示一条错误消息。
请考虑以下使用其中一些函数的示例:
#包括 <stdio.h>
#include <string.h>
空主()
{
字符行[100],*sub_text;
/* 初始化字符串 */
strcpy(line,“你好,我是一个字符串;”);
printf("行: %s\n", line);
/* 添加到字符串末尾 */
strcat(line,“你是谁?”);
printf("行: %s\n", line);
/* 查找字符串的长度 */
/* strlen 返回 */
/* 长度为 size_t 类型 */
printf("行长度: %d\n", (int)strlen(line));
/* 查找子字符串的出现 */
如果((sub_text = strchr(line,'W'))!= NULL)
printf("以 \"W\" 开头的字符串 ->%s\n",
子文本);
如果((sub_text = strchr(line,'w'))!= NULL)
printf("以 \"w\" 开头的字符串 ->%s\n",
子文本);
如果((sub_text = strchr(sub_text,'u'))!= NULL)
printf("以 \"w\" 开头的字符串 ->%s\n",
子文本);
}
程序的输出将显示如下:
Line:你好,我是一根绳子;
Line:你好,我是字符串;你是什么?
线长:35
以“w”开头的字符串->你是什么?
以“w”开头的字符串->u?
功能
开发和维护大型程序的最佳方法是将其分成几个较小的部分,每个部分都更易于管理(有时称为分而治之的技术)。函数允许程序员将程序模块化。
函数可以将复杂的程序拆分成小块,每个块都更易于编写、阅读和维护。我们已经见过 main 函数,并使用了标准库中的 printf。我们当然可以创建自己的函数和头文件。函数的布局如下:
返回类型函数名(如果需要则提供参数列表)
{
当地声明;
註釋;
返回返回值;
}
如果省略返回类型,C 默认为 int。返回值必须是声明的类型。函数内声明的所有变量都称为局部变量,因为它们仅在定义它们的函数中为人所知。
有些函数有一个参数列表,它提供了函数与调用该函数的模块之间的通信方法。这些参数也是局部变量,因为它们在函数之外不可用。到目前为止介绍的程序都有 main,它是一个函数。
函数可以简单地执行任务而不返回任何值,在这种情况下它具有以下布局:
void 函数名称(如果需要,请提供参数列表)
{
当地声明;
註釋;
}
在 C 函数调用中,参数始终按值传递。这意味着参数值的本地副本将传递给例程。函数内部对参数所做的任何更改都只会影响参数的本地副本。
为了更改或定义参数列表中的参数,必须将该参数作为地址传递。如果函数不更改这些参数的值,则可以使用常规变量。如果函数更改这些参数的值,则必须使用指针。
让我们通过例子来学习:
#包括 <stdio.h>
无效交换(int *a,int *b)
{
int 温度;
温度=*a;
*a = *b;
*b = 温度;
printf(" 来自函数交换: ");
printf("a = %d, b = %d\n", *a, *b);
}
空主()
{
int a,b;
a=5;
b=7;
printf("来自主要内容: a = %d, b = %d\n", a, b);
交换(&a,&b);
printf("回到主程序:");
printf("a = %d, b = %d\n", a, b);
}
该程序的输出将显示如下:
来自主:a = 5,b = 7
从函数交换:a = 7,b = 5
回到主程序:a = 7,b = 5
让我们看另一个例子。下面的例子使用一个名为 square 的函数,它输出 1 到 10 之间的数字的平方。
#包括 <stdio.h>
int square(int x); /* 函数原型 */
int 主要()
{
int 计数器;
对于(计数器=1;计数器<=10;计数器++)
printf("%d 的平方是 %d\n", counter, square(counter));
返回0;
}
/* 定义函数‘square’ */
int 平方(int x)
{
返回 x * x;
}
该程序的输出将显示如下:
1 的平方是 1
2 的平方等于 4
3的平方是9
4的平方是16
5 的平方是 25
6 的平方是 36
7 的平方是 49
8 的平方是 64
9 的平方是 81
10 的平方是 100
函数原型 square 声明了一个接受整数参数并返回整数的函数。当编译器在主程序中到达对 square 的函数调用时,它能够根据函数的定义检查该函数调用。
当程序到达调用函数 square 的行时,程序会跳转到该函数并执行该函数,然后继续执行主程序。没有返回类型的程序应使用 void 声明。因此,函数的参数可以是按值传递或按引用传递。
递归函数是调用自身的函数。这个过程称为递归。
传递值函数
上例中的 square 函数的参数是按值传递的。这意味着只将变量的一个副本传递给了函数。对值的任何更改都不会反映回调用函数。
以下示例使用按值传递并更改传递参数的值,这对调用函数没有影响。函数 count_down 已被声明为 void,因为没有返回类型。
#包括 <stdio.h>
无效倒计时(int x);
int 主要()
{
int 计数器;
对于(计数器=1;计数器<=10;计数器++)
倒计时(计数器);
返回0;
}
无效倒计时(int x)
{
int 计数器;
对于(计数器 = x;计数器 > 0;计数器--)
{
printf("%d ", x);
十——;
}
放置字符('\n');
}
程序的输出将显示如下:
1
2 1
3 2 1
4 3 2 1
5 4 3 2 1
6 5 4 3 2 1
7 6 5 4 3 2 1
8 7 6 5 4 3 2 1
9 8 7 6 5 4 3 2 1
10 9 8 7 6 5 4 3 2 1
让我们看另一个 C 传递值示例以更好地理解它。以下示例将用户输入的 1 到 30,000 之间的数字转换为文字。
#包括 <stdio.h>
无效do_units(int num);
无效do_tens(int num);
void do_teens(int num);
int 主要()
{
int 数字,余数;
做
{
printf("请输入一个介于 1 和 30,000 之间的数字:");
scanf("%d",&num);
} 当 (数字 < 1 || 数字 > 30000);
余数 = 数字;
printf("%d 个单词 = ", num);
do_tens(残基/1000);
如果 (数字 >= 1000)
printf("千 ");
残留量%=1000;
做单位(残基/100);
if (残基 >= 100)
{
printf("百");
}
如果 (num > 100 && num%100 > 0)
printf("和 ");
残留量%=100;
do_tens(残差);
放置字符('\n');
返回0;
}
void do_units(int num)
{
开关(数字)
{
情况 1:
printf(“一”);
休息;
情况 2:
printf("二 ");
休息;
案例 3:
printf("三 ");
休息;
案例4:
printf("四 ");
休息;
案例5:
printf("五 ");
休息;
案例六:
printf("六 ");
休息;
案例7:
printf("七 ");
休息;
案例8:
printf("八 ");
休息;
案例9:
printf("九 ");
}
}
void do_tens(int num)
{
开关(数字/10)
{
情况 1:
do_teens(数字);
休息;
情况 2:
printf("二十 ");
休息;
案例 3:
printf("三十 ");
休息;
案例4:
printf("四十 ");
休息;
案例5:
printf("五十 ");
休息;
案例六:
printf("六十 ");
休息;
案例7:
printf("七十 ");
休息;
案例8:
printf("八十");
休息;
案例9:
printf("九十");
}
如果 (数字/10 != 1)
执行单位(num%10);
}
void do_teens(int num)
{
开关(数字)
{
案例10:
printf("十 ");
休息;
案例11:
printf("十一 ");
休息;
案例12:
printf("十二 ");
休息;
案例13:
printf("十三 ");
休息;
案例14:
printf("十四 ");
休息;
案例15:
printf("十五");
休息;
案例16:
printf("十六 ");
休息;
案例17:
printf("十七");
休息;
案例18:
printf("十八 ");
休息;
案例19:
printf("十九 ");
}
}
程序的输出如下:
输入 1 至 30,000 之间的数字:12345
12345大写 =一万二千三百四十五
引用调用
要使函数按引用调用,请传递变量的地址而不是传递变量本身。可以使用 & 运算符获取变量的地址。下面调用交换函数,传递变量的地址而不是实际值。
交换(&x,&y);
解除引用
我们现在遇到的问题是,函数 swap 传递的是地址而不是变量,因此我们需要取消引用变量,以便我们查看实际值而不是变量的地址来交换它们。
在 C 语言中,使用指针 (*) 符号可以实现解引用。简单来说,这意味着在使用每个变量之前,先在前面放置一个 *,以便它引用的是变量的值,而不是变量的地址。以下程序演示了如何通过引用来交换两个值。
#包括 <stdio.h>
无效交换(int *x,int *y);
int 主要()
{
int x=6,y=10;
printf("在函数 swap 之前,x = %d 和 y =
%d\n\n", x, y);
交换(&x,&y);
printf("函数 swap 后,x = %d 且 y =
%d\n\n", x, y);
返回0;
}
无效交换(int *x,int *y)
{
int 温度 = *x;
*x = *y;
*y = 温度;
}
让我们看看程序的输出:
在函数 swap 之前,x = 6 和 y = 10
经过函数交换后,x = 10 且 y = 6
函数可能是递归的,也就是说函数可以调用自身。每次调用自身都需要将函数的当前状态推送到堆栈上。记住这一事实很重要,因为很容易造成堆栈溢出,即堆栈已经没有空间来放置更多数据。
以下示例使用递归计算数字的阶乘。阶乘是将数字与其自身以下的每个其他整数相乘,直到 1。例如,数字 6 的阶乘为:
阶乘 6 = 6 * 5 * 4 * 3 * 2 * 1
因此 6 的阶乘为 720。从上面的例子可以看出,阶乘 6 = 6 * 阶乘 5。同样,阶乘 5 = 5 * 阶乘 4,依此类推。
以下是计算阶乘的一般规则。
阶乘(n)= n * 阶乘(n-1)
当 n = 1 时,上述规则终止,因为 1 的阶乘为 1。让我们借助示例来更好地理解它:
#包括 <stdio.h>
长整型阶乘(int num);
int 主要()
{
int 数字;
长整型f;
printf("请输入一个数字:");
scanf("%d",&num);
f = 阶乘(数字);
printf("%d 的阶乘是 %ld\n", num, f);
返回0;
}
长整型阶乘(整型数)
{
如果 (数字 == 1)
返回1;
别的
返回 num * 阶乘(num-1);
}
让我们看看这个程序执行的输出:
输入一个数字:7的
阶乘是5040
C 语言中的内存分配
C 编译器有一个内存分配库,定义在 malloc.h 中。使用 malloc 函数保留内存,并返回指向地址的指针。它需要一个参数,即所需内存的大小(以字节为单位)。
下面的示例为字符串“hello world”分配空间。
ptr = (char *)malloc(strlen("Hello world") + 1);
需要额外的一个字节来考虑字符串终止字符 '\0'。(char *) 称为强制类型转换,并强制返回类型为 char *。
由于数据类型具有不同的大小,并且 malloc 以字节为单位返回空间,因此出于可移植性的考虑,在指定要分配的大小时使用 sizeof 运算符是一种很好的做法。
下面的示例将字符串读入字符数组缓冲区,然后分配所需的精确内存量并将其复制到名为“ptr”的变量。
#include <string.h>
#包括 <malloc.h>
int 主要()
{
char *ptr,缓冲区[80];
printf("请输入一个字符串:");
获取(缓冲区);
ptr = (char *)malloc((strlen(缓冲区)+ 1)*
sizeof(字符));
strcpy(ptr,缓冲区);
printf("您输入的是:%s\n", ptr);
返回0;
}
该程序的输出如下:
输入字符串:印度是最好的
您输入的是:印度是最好的
重新分配内存
在编程过程中,您可能多次想要重新分配内存。这可以通过 realloc 函数完成。realloc 函数接受两个参数,即要调整大小的内存的基址和要保留的空间量,并返回指向基址的指针。
假设我们已经为名为 msg 的指针保留了空间,并且我们想要重新分配空间到它已经占用的空间量,再加上另一个字符串的长度,那么我们可以使用以下命令。
msg = (char *)realloc(msg,(strlen(msg)+ strlen(buffer)+ 1)*sizeof(char));
以下程序说明了 malloc、realloc 和 free 的使用。用户输入一系列连接在一起的字符串。当输入空字符串时,程序停止读取字符串。
#include <string.h>
#包括 <malloc.h>
int 主要()
{
字符缓冲区[80],*msg;
int 第一次时间=0;
做
{
printf("\n请输入一个句子:");
获取(缓冲区);
如果(!第一次)
{
msg = (char *)malloc((strlen(缓冲区)+ 1)*
sizeof(字符));
strcpy(msg,缓冲区);
第一次=1;
}
别的
{
msg = (char *)realloc(msg,(strlen(msg)+
strlen(缓冲区)+ 1)* sizeof(char));
strcat (消息,缓冲区);
}
放入(信息);
} while(strcmp(缓冲区,“”));
免费(味精);
返回0;
}
该程序的输出如下:
输入一个句子:从前从前
输入
一个句子:从前有一位国王
从前有一位国王
输入一个句子:这位国王
从前有一位国王这位国王
输入句子:
从前有一位国王
释放内存
使用完已分配的内存后,切勿忘记释放内存,因为这将释放资源并提高速度。要释放已分配的内存,请使用 free 函数。
释放(ptr);
结构
As well as the basic data types, C has a structure mechanism that allows you to group data items that are related to each other under a common name. This is commonly referred to as a User Defined Type.
The keyword struct starts the structure definition, and a tag gives the unique name to the structure. The data types and variable names added to the structure are members of the structure. The result is a structure template that may be used as a type specifier. The following is a structure with a tag of month.
struct month
{
char name[10];
char abbrev[4];
int days;
};
A structure type is usually defined near to the start of a file using a typedef statement. typedef defines and names a new type, allowing its use throughout the program. typedef usually occur just after the #define and #include statements in a file.
The typedef keyword may be used to define a word to refer to the structure rather than specifying the struct keyword with the name of the structure. It is usual to name the typedef in capital letters. Here are the examples of structure definition.
typedef struct {
char name[64];
char course[128];
int age;
int year;
} student; This defines a new type student variables of type student can be declared as follows.
student st_rec;
Notice how similar this is to declaring an int or float. The variable name is st_rec, it has members called name, course, age and year. Similarly,
typedef struct element
{
char data;
struct element *next;
} STACKELEMENT;
A variable of the user defined type struct element may now be declared as follows.
STACKELEMENT *stack;
Consider the following structure:
struct student
{
char *name;
int grade;
};
A pointer to struct student may be defined as follows.
struct student *hnc;
When accessing a pointer to a structure, the member pointer operator, -> is used instead of the dot operator. To add a grade to a structure,
s.grade = 50;
You could assign a grade to the structure as follows.
s->grade = 50;
As with the basic data types, if you want the changes made in a function to passed parameters to be persistent, you have to pass by reference (pass the address). The mechanism is exactly the same as the basic data types. Pass the address, and refer to the variable using pointer notation.
Having defined the structure, you can declare an instance of it and assign values to the members using the dot notation. The following example illustrates the use of the month structure.
#include <stdio.h>
#include <string.h>
struct month
{
char name[10];
char abbreviation[4];
int days;
};
int main()
{
struct month m;
strcpy(m.name, "January");
strcpy(m.缩写,“Jan”);
m.天=31;
printf("%s 缩写为 %s,共 %d 天\n", m.name, m.abbreviation, m.days);
返回0;
}
该程序的输出如下:
一月缩写为 Jan,有 31 天
所有 ANSI C 编译器都允许您将一个结构分配给另一个结构,从而执行逐个成员的复制。如果我们有名为 m1 和 m2 的月份结构,那么我们可以使用以下命令将 m1 中的值分配给 m2:
- 具有指针成员的结构。
- 结构初始化。
- 将结构传递给函数。
- 指针和结构。
C 语言中带有指针成员的结构
将字符串保存在固定大小的数组中会降低内存使用效率。更有效的方法是使用指针。指针在结构中的使用方式与在普通指针定义中的使用方式完全相同。让我们看一个例子:
#include <string.h>
#包括 <malloc.h>
结构月份
{
字符*名称;
char *缩写;
整数天数;
};
int 主要()
{
结构月份m;
m.name = (char *)malloc((strlen(“January”)+1)*
sizeof(字符));
strcpy(m.name, "一月");
m.缩写 = (char *)malloc((strlen(“Jan”)+1)*
sizeof(字符));
strcpy(m.缩写,“Jan”);
m.天=31;
printf("%s 缩写为 %s,有 %d 天\n",
m.名称,m.缩写,m.天数);
返回0;
}
该程序的输出如下:
一月缩写为 Jan,有 31 天
C 语言中的结构初始化器
为了给结构提供一组初始值,可以将 Initialisers 添加到声明语句中。由于月份从 1 开始,但 C 中的数组从零开始,因此在下面的示例中,在位置零处使用了一个名为 junk 的额外元素。
#包括 <stdio.h>
#include <string.h>
结构月份
{
字符*名称;
char *缩写;
整数天数;
} 月详细信息[] =
{
“垃圾”, “垃圾”, 0,
“一月”, “一月”, 31,
“二月”, “二月”, 28,
“三月”, “三月”, 31,
“四月”, “四月”, 30,
“五月”,“五月”,31,
“六月”,“Jun”,30,
"七月", "七月", 31,
“八月”,“八月”,31,
“九月”,“九月”,30,
“十月”,“十月”,31,
“十一月”, “十一月”, 30,
“十二月”,“十二月”,31
};
int 主要()
{
int 计数器;
对于(计数器=1;计数器<=12;计数器++)
printf("%s 缩写为 %s,有 %d 天\n",
month_details[计数器].名称,
month_details[计数器].缩写,
月详情[计数器].天数);
返回0;
}
输出结果如下:
一月缩写为 Jan,有 31 天
二月缩写为 Feb,有 28 天
三月缩写为 Mar,有 31 天
四月缩写为 Apr,有 30 天
五月缩写为May,有31天
六月缩写为Jun,有30天
七月缩写为 Jul,有 31 天
八月缩写为Aug,有31天
九月缩写为 Sep,有 30 天
十月缩写为 Oct,有 31 天
十一月缩写为 Nov,有 30 天
十二月缩写为 Dec,有 31 天
在 C 语言中将结构传递给函数
结构可以作为参数传递给函数,就像任何基本数据类型一样。以下示例使用名为 date 的结构,该结构已传递给 isLeapYear 函数来确定年份是否为闰年。
通常您只需传递日期值,但传递整个结构是为了说明将结构传递给函数。
#包括 <stdio.h>
#include <string.h>
结构月份
{
字符*名称;
char *缩写;
整数天数;
} 月详细信息[] =
{
“垃圾”, “垃圾”, 0,
“一月”, “一月”, 31,
“二月”, “二月”, 28,
“三月”, “三月”, 31,
“四月”, “四月”, 30,
“五月”,“五月”,31,
“六月”,“Jun”,30,
"七月", "七月", 31,
“八月”,“八月”,31,
“九月”,“九月”,30,
“十月”,“十月”,31,
“十一月”, “十一月”, 30,
“十二月”,“十二月”,31
};
结构日期
{
int 天;
int月份;
int年份;
};
int isLeapYear(结构日期d);
int 主要()
{
结构日期 d;
printf("输入日期(例如:1980/11/11):");
scanf("%d/%d/%d",&d.日,&d.月,&d.年);
printf("日期 %d %s %d 是 ", d.day,
month_details[d.month].name, d.year);
如果 (isLeapYear(d) == 0)
printf("不是 ");
puts("闰年");
返回0;
}
int isLeapYear(结构日期d)
{
如果 ((d.year%4==0&&d.year%100!=0)||
d.年%400 == 0)
返回1;
返回0;
}
程序执行如下:
输入日期(例如:11/11/1980):9/12/1980
1980 年 12 月 9 日是闰年
以下示例动态分配一个结构数组来存储学生姓名和成绩。然后以升序显示成绩给用户。
#include <string.h>
#包括 <malloc.h>
结构学生
{
字符*名称;
int 等级;
};
无效交换(结构学生* x,结构学生* y);
int 主要()
{
结构学生*组;
字符缓冲区[80];
int 虚假;
int 内部,外部;
int 计数器,学生人数;
printf("本组有多少名同学:");
scanf("%d",&numStudents);
组 = (结构学生 *)malloc(numStudents *
sizeof(结构学生));
对于(计数器=0;计数器<numStudents;计数器++)
{
虚假 = getchar();
printf("输入学生姓名:");
获取(缓冲区);
组[计数器].name = (char *)malloc((strlen(buffer)+1)* sizeof(char));
strcpy(组[计数器].名称,缓冲区);
printf("请输入成绩:");
scanf("%d",&group[counter].grade);
}
对于(外部=0;外部<numStudents;外部++)
对于(内部=0;内部<外部;内部++)
如果 (组[外部].等级<
组[内部].等级)
交换(&group [外部],&group [内部]);
puts("该组按成绩升序排列...");
对于(计数器=0;计数器<numStudents;计数器++)
printf("%s 取得了 %d 级成绩 \n",
组[计数器].名称,
组[计数器].等级);
返回0;
}
无效交换(结构学生* x,结构学生* y)
{
结构学生温度;
temp.name = (char *)malloc((strlen(x->name)+1) *
sizeof(字符));
strcpy(temp.name,x->name);
temp.grade = x->grade;
x->等级 = y->等级;
x->name = (char *)malloc((strlen(y->name)+1) *
sizeof(字符));
strcpy(x->名称,y->名称);
y->等级 = 温度.等级;
y->名称 = (char *)malloc((strlen(temp.名称)+1) *
sizeof(字符));
strcpy(y->name,temp.name);
}
执行后的输出如下:
小组中有多少名学生:4
输入学生姓名:Anuraaj
输入成绩:7
输入学生姓名:Honey
输入成绩:2
输入学生姓名:Meetushi
输入成绩:1
输入学生姓名:Deepti
输入成绩:4
该组按成绩从高到低排序……
Meetushi取得1级
Honey取得2级
Deepti取得4级
Anuraaj取得7级
联盟
联合允许您查看不同类型的相同数据,或使用不同名称的相同数据。联合类似于结构。联合的声明和使用方式与结构相同。
联合与结构的不同之处在于,联合中一次只能使用一个成员。原因很简单。联合的所有成员都占用相同的内存区域。它们相互叠加。
联合的定义和声明方式与结构相同。声明中唯一的区别是使用关键字 union 代替 struct。要定义一个字符变量和一个整数变量的简单联合,您可以编写以下内容:
联合共享 {
字符c;
int 我;
};
此共享联合可用于创建可保存字符值 c 或整数值 i 的联合实例。这是一个或条件。与保存两个值的结构不同,联合一次只能保存一个值。
联合可以在其声明时初始化。由于一次只能使用一个成员,因此只能初始化一个成员。为了避免混淆,只能初始化联合的第一个成员。以下代码显示了正在声明和初始化的共享联合的实例:
联合共享泛型变量 = {`@'};
请注意,generic_variable 联合的初始化方式与结构的第一个成员的初始化方式相同。
可以使用成员运算符 (.),以与结构成员相同的方式使用单个联合成员。但是,在访问联合成员时存在一个重要区别。
每次只能访问一个 union 成员。由于 union 将其成员存储在一起,因此每次只能访问一个成员非常重要。
union 关键字
联合标签 {
工会会员;
/* 此处可以放置附加语句 */
}实例;
union 关键字用于声明联合。联合是一个或多个变量(联合成员)的集合,这些变量被归类到同一个名称下。此外,每个联合成员都占用相同的内存区域。
关键字 union 标识联合定义的开始。它后面跟着一个标签,即联合的名称。标签后面是用括号括起来的联合成员。
还可以定义实例,即联合的实际声明。如果您定义结构而不定义实例,则它只是一个模板,稍后可以在程序中使用它来声明结构。以下是模板的格式:
联合标签 {
工会会员;
/* 此处可以放置附加语句 */
};
要使用模板,您可以使用以下格式:联合标签实例;
要使用这种格式,您必须先前声明具有给定标签的联合。
/* 声明一个名为 tag 的联合模板 */
联合标签 {
int 数字;
炭阿尔卑斯山;
}
/* 使用联合模板 */
联合标签混合变量;
/* 声明一个联合体并实例化 */
联合通用类型标签 {
字符c;
int 我;
浮点数f;
双 d;
} 通用的;
/* 初始化一个联合。 */
联合日期标签 {
char完整日期[9];
结构部分日期标签 {
字符月份[2];
字符 break_value1;
烧焦天[2];
字符 break_value2;
字符年[2];
} 部分日期;
}日期 = {“09/12/80”};
让我们借助示例来更好地理解它:
#包括 <stdio.h>
int 主要()
{
联盟
{
int 值;/*这是联合的第一部分*/
结构
{
char first; /*这两个值是它的第二部分*/
字符秒;
} 一半;
} 数字;
多头指数;
对于(索引 = 12;索引 < 300000L;索引 += 35231L)
{
数字.值 = 索引;
printf("%8x %6x %6x\n", 数字.值,
数字.一半.第一,
数字.半秒);
}
返回0;
}
程序的输出将显示如下:
抄送 0
89ab 工厂 ff89
134a 4a 13
9ce9 ffe9 ff9c
2688 ff88 26
b027 27 ffb0
39c6 ffc6 39
c365 65 ffc3
4d04 4 4d
联合在数据恢复中的实际用途
现在让我们看看 union 的一个实际用途是数据恢复编程。让我们举一个小例子。以下程序是软盘驱动器坏扇区扫描程序的小模型(a:),但它不是坏扇区扫描软件的完整模型。
让我们检查一下这个程序:
#include<dos.h>
#包括<conio.h>
int 主要()
{
int rp,磁头,磁道,扇区,状态;
字符 *buf;
工会 REGS 进出;
结构 SREGS s;
clrscr();
/* 重置磁盘系统以初始化磁盘 */
printf("\n 正在重置磁盘系统....");
对于(rp = 0;rp <= 2;rp ++)
{
英寸高程 = 0;
in.h.dl = 0x00;
int86(0x13,&输入,&输出);
}
printf("\n\n\n 现在正在测试磁盘是否有坏扇区....");
/* 扫描坏扇区 */
对于(轨道=0;轨道<=79;轨道++)
{
对于(头部=0;头部<=1;头部++)
{
对于(扇区=1;扇区<=18;扇区++)
{
in.h.ah = 0x04;
吸入量 = 1;
in.h.dl = 0x00;
in.h.ch = 轨道;
in.h.dh = 头部;
in.h.cl = 部门;
in.x.bx = FP_OFF(buf);
s.es = FP_SEG(缓冲区);
int86x(0x13,&in,&out,&s);
如果(out.x.cflag)
{
状态=out.h.ah;
printf("\n 磁道:%d 磁头:%d 扇区:%d 状态 ==0x%X",磁道,磁头,扇区,状态);
}
}
}
}
printf("\n\n\n完成");
返回0;
}
现在让我们看看如果软盘中有坏扇区,它的输出会是什么样子:
重置磁盘系统....
现在测试磁盘是否有坏扇区....
磁道:0 磁头:0 扇区:4 状态 ==0xA
磁道:0 磁头:0 扇区:5 状态 ==0xA
磁道:1 磁头:0 扇区:4 状态 ==0xA
磁道:1 磁头:0 扇区:5 状态 ==0xA
磁道:1 磁头:0 扇区:6 状态 ==0xA
磁道:1 磁头:0 扇区:7 状态 ==0xA
磁道:1 磁头:0 扇区:8 状态 ==0xA
磁道:1 磁头:0 扇区:11 状态 ==0xA
磁道:1 磁头:0 扇区:12 状态 ==0xA
磁道:1 磁头:0 扇区:13 状态 ==0xA
磁道:1 磁头:0 扇区:14 状态 ==0xA
磁道:1 磁头:0 扇区:15 状态 ==0xA
磁道:1 磁头:0 扇区:16 状态 ==0xA
磁道:1 磁头:0 扇区:17 状态 ==0xA
磁道:1 磁头:0 扇区:18 状态 ==0xA
磁道:1 磁头:1 扇区:5 状态 ==0xA
磁道:1 磁头:1 扇区:6 状态 ==0xA
磁道:1 磁头:1 扇区:7 状态 ==0xA
磁道:1 磁头:1 扇区:8 状态 ==0xA
磁道:1 磁头:1 扇区:9 状态 ==0xA
磁道:1 磁头:1 扇区:10 状态 ==0xA
磁道:1 磁头:1 扇区:11 状态 ==0xA
磁道:1 磁头:1 扇区:12 状态 ==0xA
磁道:1 磁头:1 扇区:13 状态 ==0xA
磁道:1 磁头:1 扇区:14 状态 ==0xA
磁道:1 磁头:1 扇区:15 状态 ==0xA
磁道:1 磁头:1 扇区:16 状态 ==0xA
磁道:1 磁头:1 扇区:17 状态 ==0xA
磁道:1 磁头:1 扇区:18 状态 ==0xA
磁道:2 磁头:0 扇区:4 状态 ==0xA
磁道:2 磁头:0 扇区:5 状态 ==0xA
磁道:14 磁头:0 扇区:6 状态 ==0xA
完毕
理解该程序中用于验证磁盘是否有坏扇区以及重置磁盘系统等的函数和中断可能会有点困难,但您不必担心,我们将在接下来的章节中的 BIOS 和中断编程部分中学习所有这些内容。
C 语言中的文件处理
在 C 中,文件访问是通过将流与文件关联来实现的。C 使用一种称为文件指针的新数据类型与文件通信。此类型在 stdio.h 中定义,并写为 FILE *。名为 output_file 的文件指针在以下语句中声明:
文件*输出文件;
fopen 函数的文件模式
程序必须先打开文件,然后才能访问它。这是使用 fopen 函数完成的,该函数返回所需的文件指针。如果由于任何原因无法打开文件,则将返回 NULL 值。您通常会按如下方式使用 fopen
如果 ((output_file = fopen("output_file", "w")) == NULL)
fprintf(stderr, “无法打开 %s\n”,
“输出文件”);
fopen 接受两个参数,都是字符串,第一个参数是要打开的文件的名称,第二个参数是访问字符,通常是 r、a 或 w 等之一。文件可以用多种模式打开,如下表所示。
| 文件模式 |
| r |
打开一个文本文件进行阅读。 |
| 在 |
创建一个用于写入的文本文件。如果该文件存在,则将其覆盖。 |
| 一个 |
以追加模式打开文本文件。文本将添加到文件末尾。 |
| rb |
打开一个二进制文件进行读取。 |
| 西伯利亚 |
创建用于写入的二进制文件。如果该文件存在,则将其覆盖。 |
| AB |
以追加模式打开二进制文件。数据将添加到文件末尾。 |
| r+ |
打开一个文本文件进行读写。 |
| 在+ |
创建一个用于读写的文本文件。如果文件存在,则将其覆盖。 |
| a+ |
最后打开一个文本文件以供读写。 |
| r+b 或 rb+ |
打开二进制文件进行读写。 |
| w+b 或 wb+ |
创建用于读写的二进制文件。如果文件存在,则将其覆盖。 |
| a+b 或 ab+ |
最后打开一个文本文件以供读写。 |
更新模式与 fseek、fsetpos 和 rewind 函数一起使用。fopen 函数返回文件指针,如果发生错误则返回 NULL。
以下示例以只读模式打开文件 tarun.txt。测试文件是否存在是良好的编程习惯。
如果((in = fopen("tarun.txt", "r"))==NULL)
{
puts("无法打开文件");
返回0;
}
关闭文件
使用 fclose 函数关闭文件。语法如下:
fclose(在);
读取文件
feof 函数用于测试文件是否结束。fgetc、fscanf 和 fgets 函数用于从文件中读取数据。
下面的示例在屏幕上列出文件的内容,使用 fgetc 每次读取一个字符。
#包括 <stdio.h>
int 主要()
{
文件*在;
int 键;
如果((in = fopen("tarun.txt", "r"))==NULL)
{
puts("无法打开文件");
返回0;
}
当(!feof(in))
{
键 = fgetc (输入);
/* 读取的最后一个字符是文件结束标记,因此不要打印它 */
如果(!feof(in))
放入字符(键);
}
fclose(在);
返回0;
}
fscanf 函数可用于从文件中读取不同类型的数据类型,如下例所示,前提是文件中的数据采用 fscanf 使用的格式字符串的格式。
fscanf(in, “%d/%d/%d”, &day, &month, &year);
fgets函数用于从文件中读取一定数量的字符。stdin是标准输入文件流,fgets函数可用于控制输入。
写入文件
可以使用 fputc 和 fprintf 将数据写入文件。以下示例使用 fgetc 和 fputc 函数复制文本文件。
#包括 <stdio.h>
int 主要()
{
文件*输入,*输出;
int 键;
如果((in = fopen("tarun.txt", "r"))==NULL)
{
puts("无法打开文件");
返回0;
}
out = fopen("复制.txt", "w");
当(!feof(in))
{
键 = fgetc (输入);
如果(!feof(in))
fputc (键,输出);
}
fclose(在);
fclose(输出);
返回0;
}
fprintf 函数可用于将格式化的数据写入文件。
fprintf(out, "日期: %02d/%02d/%02d\n",
日、月、年);
C 的命令行参数
声明 main() 函数的 ANSI C 定义如下:
int main() 或 int main(int argc, char **argv)
第二个版本允许从命令行传递参数。参数 argc 是一个参数计数器,包含从命令行传递的参数数量。参数 argv 是参数向量,它是一个指向表示实际传递的参数的字符串的指针数组。
以下示例允许从命令行传递任意数量的参数并打印出来。argv[0] 是实际程序。该程序必须从命令提示符运行。
#包括 <stdio.h>
int main(int argc,char **argv)
{
int 计数器;
puts("该程序的参数是:");
对于(计数器=0;计数器<argc;计数器++)
放入(argv[计数器]);
返回0;
}
如果程序名是count.c,则可以从命令行按如下方式调用它。
计数 3
或者
计数 7
或者
计数192等
下一个示例使用文件处理例程将文本文件复制到新文件。例如,命令行参数可以这样调用:
txtcpy 一.txt 二.txt
#包括 <stdio.h>
int main(int argc,char **argv)
{
文件*输入,*输出;
int 键;
如果 (argc < 3)
{
puts("用法:txtcpy 源目标\n");
puts("源必须是一个现有文件");
puts("如果目标文件存在,它将
已覆盖”);
返回0;
}
如果 ((in = fopen(argv[1], "r")) == NULL)
{
puts("无法打开要复制的文件");
返回0;
}
如果 ((out = fopen(argv[2], "w")) == NULL)
{
puts("无法打开输出文件");
返回0;
}
当(!feof(in))
{
键 = fgetc (输入);
如果(!feof(in))
fputc (键,输出);
}
fclose(在);
fclose(输出);
返回0;
}
按位操作符
在硬件层面,数据以二进制数表示。数字 59 的二进制表示形式为 111011。位 0 是最低有效位,在本例中位 5 是最高有效位。
每个位集都按 2 的位集幂进行计算。位运算符允许您在位级别操作整数变量。以下显示数字 59 的二进制表示。
| 数字 59 的二进制表示 |
| 位 5 4 3 2 1 0 |
| 2 次方 n 32 16 8 4 2 1 |
| 设置 1 1 1 0 1 1 |
使用三位可以表示数字 0 到 7。下表以二进制形式显示了数字 0 到 7。
| 二进制数字 |
| 000 |
0 |
| 001 |
1 |
| 010 |
2 |
| 011 |
3 |
| 100 |
4 |
| 101 |
5 |
| 110 |
6 |
| 111 |
7 |
下表列出了可用于操作二进制数的按位运算符。
| 二进制数字 |
| & |
按位与 |
| | |
按位或 |
| ^ |
按位异或 |
| ~ |
按位求补 |
| << |
按位左移 |
| >> |
按位右移 |
按位与
仅当两位均被设置时,按位与才为 True。以下示例显示了对数字 23 和 12 进行按位与的结果。
| 10111(23)
01100 (12) 且
____________________
00100(结果 = 4) |
您可以使用掩码值来检查某些位是否已设置。如果我们想检查位 1 和位 3 是否已设置,我们可以用 10(位 1 和位 3 的值)来掩码该数字,然后根据掩码测试结果。
#包括 <stdio.h>
int 主要()
{
int 数字,掩码 = 10;
printf("请输入一个数字:");
scanf("%d",&num);
如果((数字&掩码)==掩码)
puts("位 1 和 3 已设置");
别的
puts("位 1 和位 3 未设置");
返回0;
}
按位或
如果任一位被设置,则按位或运算为真。以下显示了对数字 23 和 12 进行按位或运算的结果。
| 10111(23)
01100(12)或
______________________
11111(结果 = 31) |
您可以使用掩码来确保已设置一个或多个位。以下示例确保已设置位 2。
#包括 <stdio.h>
int 主要()
{
int 数字,掩码 = 4;
printf("请输入一个数字:");
scanf("%d",&num);
数字| =面具;
printf("确保位 2 被设置后: %d\n", num);
返回0;
}
按位异或
如果任一位被设置,但不是同时设置,则按位异或为 True。以下显示了对数字 23 和 12 进行按位异或的结果。
| 10111(23)
01100(12) 排他或(XOR)
_____________________________
11011(结果 = 27) |
排他或有一些有趣的特性。如果你对一个数字本身进行排他或运算,它会将自己设置为零,因为零将保持为零,而一不能同时被设置,因此被设置为零。
因此,如果您将一个数字与另一个数字进行“排他或”运算,然后再次将结果与另一个数字进行“排他或”运算,结果就是原始数字。您可以用上例中使用的数字尝试此操作。
23 或 12 = 27
27 或 12 = 23
27 或 23 = 12
此特性可用于加密。下面的程序使用加密密钥 23 来说明用户输入的数字的属性。
#包括 <stdio.h>
int 主要()
{
int 数字, 键 = 23;
printf("请输入一个数字:");
scanf("%d",&num);
数字^=键;
printf("与 %d 进行排他或得出 %d\n", key, num);
数字^=键;
printf("与 %d 进行排他或得出 %d\n", key, num);
返回0;
}
按位补码
按位补码是一个二进制补码运算符,用于打开或关闭位。如果位为 1,则将其设置为 0;如果位为 0,则将其设置为 1。
#包括 <stdio.h>
int 主要()
{
int 数字 = 0xFFFF;
printf("%X 的补数是 %X\n", num, ~num);
返回0;
}
按位左移
按位左移运算符将数字左移。数字左移时,最高有效位会丢失,而空出的最低有效位为零。以下是 43 的二进制表示。
0101011(十进制 43)
通过将位向左移动,我们会丢失最高有效位(在本例中为零),并在最低有效位处用零填充数字。以下是结果数字。
1010110(十进制 86)
按位右移
按位右移运算符将数字向右移动。空出的最高有效位将替换为零,而空出的最低有效位将丢失。以下显示了数字 43 的二进制表示。
0101011(十进制 43)
通过向右移动位,我们会丢失最低有效位(在本例中为 1),并在最高有效位处用零填充数字。以下是结果数字。
0010101(十进制 21)
以下程序使用按位右移和按位与将数字显示为 16 位二进制数。该数字从 16 依次右移到零,并与 1 进行按位与运算以查看该位是否已设置。另一种方法是使用按位或运算符的连续掩码。
#包括 <stdio.h>
int 主要()
{
int 计数器,数字;
printf("请输入一个数字:");
scanf("%d",&num);
printf("%d 是二进制: ", num);
对于(计数器=15;计数器>=0;计数器--)
printf("%d", (num >> counter) & 1);
放置字符('\n');
返回0;
}
二进制 – 十进制转换函数
接下来给出的两个函数用于二进制到十进制和十进制到二进制的转换。接下来给出的将十进制数转换为相应的二进制数的函数最多支持 32 位二进制数。您可以根据需要使用此函数或之前给出的程序进行转换。
十进制到二进制的转换函数:
void Decimal_to_Binary(void)
{
int输入=0;
int 我;
int 计数 = 0;
int binary [32]; /* 32 位,最多 32 个元素 */
printf("输入要转换成的十进制数
二进制:”);
scanf ("%d",&输入);
做
{
i = 输入%2; /* MOD 2 得到 1 或 0*/
binary[count] = i; /* 将元素加载到二进制数组中 */
输入 = 输入/2; /* 将输入除以 2,通过二进制减少 */
count++; /* 计算需要多少个元素 */
}while (输入 > 0);
/* 反转并输出二进制数字 */
printf ("二进制表示形式为:");
做
{
printf ("%d",二进制[count-1]);
数数 - ;
} 当 (计数 > 0);
printf(“\n”);
}
二进制到十进制转换函数:
以下函数是将任何二进制数转换为其对应的十进制数:
void 二进制转十进制(void)
{
char二进制保持[512];
字符*二进制;
int i=0;
int dec = 0;
int z;
printf ("请输入二进制数字。\n");
printf ("二进制数字只能是 0 或 1 ");
printf ("二进制条目: ");
二进制 = 获取(二进制保持);
i=strlen(二进制);
对于 (z=0; z<i; ++z)
{
dec=dec*2+(binary[z]=='1'? 1:0); /* 如果 Binary[z] 是
等于 1,
然后 1 否则 0 */
}
printf(“\n”);
printf ("%s 的十进制值为 %d",
二进制,十进制);
printf(“\n”);
}
调试和测试
语法错误
语法是指语句中元素的语法、结构和顺序。当我们违反规则时,就会发生语法错误,例如忘记用分号结束语句。编译程序时,编译器会生成可能遇到的任何语法错误的列表。
好的编译器会输出错误描述列表,并可能提供可能的解决方案。修复错误可能会导致重新编译时显示更多错误。原因是先前的错误改变了程序的结构,这意味着在原始编译期间抑制了更多错误。
同样,一个错误可能会导致多个错误。尝试在一个编译和运行正确的程序的主函数末尾添加一个分号。当你重新编译它时,你会得到一大堆错误,而这仅仅是一个放错位置的分号。
除了语法错误,编译器还可能发出警告。警告不是错误,但可能会在程序执行过程中导致问题。例如,将双精度浮点数分配给单精度浮点数可能会导致精度损失。这不是语法错误,但可能会导致问题。在这个特定的例子中,您可以通过将变量转换为适当的数据类型来显示意图。
考虑以下示例,其中 x 是单精度浮点数,y 是双精度浮点数。在赋值期间,y 被明确转换为浮点数,这将消除任何编译器警告。
x = (浮点)y;
逻辑错误
逻辑错误是指逻辑中存在错误。例如,您可以测试某个数字是否小于 4 且大于 8。这不可能是真的,但如果语法正确,程序将成功编译。请考虑以下示例:
如果 (x < 4 && x > 8)
放入(“永远不会发生!”)
语法是正确的,因此程序可以编译,但是 puts 语句永远不会被打印,因为 x 的值不可能同时小于四和大于八。
大多数逻辑错误都是在程序的初始测试中发现的。当程序的行为不符合预期时,你会更仔细地检查逻辑语句并进行纠正。这仅适用于明显的逻辑错误。程序越大,通过的路径越多,验证程序是否按预期运行就越困难。
测试
在软件开发过程中,错误可能在开发的任何阶段出现。这是因为软件开发早期阶段的验证方法是手动的。因此,除了在编码活动期间引入的错误之外,在编码活动期间开发的代码可能还存在一些需求错误和设计错误。在测试期间,将使用一组测试用例执行要测试的程序,并评估测试用例的程序输出以确定编程是否符合预期。
因此,测试是分析软件项目以检测现有条件与所需条件之间的差异(即错误)并评估软件项目功能的过程。因此,测试是分析程序以查找错误的过程。
一些测试原则
- 测试无法表明缺陷的不存在,只能表明缺陷的存在。
- 错误发生得越早,代价就越大。
- 错误发现得越晚,代价就越大。
现在让我们讨论一些测试技术:
白盒测试
白盒测试是一种使用所有可能值测试程序所有路径的技术。这种方法需要了解程序的行为方式。例如,如果您的程序接受 1 到 50 之间的整数值,白盒测试将使用所有 50 个值测试程序以确保每个值都正确,然后测试整数可能采用的所有其他可能值并测试其行为是否符合预期。考虑到典型程序可能具有的数据项数量,可能的排列使得大型程序的白盒测试极其困难。
白盒测试可以应用于大型程序的安全关键功能,其余大部分功能则使用黑盒测试进行测试,如下所述。由于排列数量众多,白盒测试通常使用测试工具进行,其中值的范围通过特殊程序快速输入到程序中,记录与预期行为不符的异常。白盒测试有时被称为结构、清晰或开盒测试。
黑盒测试
黑盒测试与白盒测试类似,不同之处在于黑盒测试只测试选定的值,而不是测试所有可能的值。在这种类型的测试中,测试人员知道输入和预期结果,但不一定知道程序如何得出这些结果。黑盒测试有时被称为功能测试。
黑盒测试的测试用例通常在程序规范完成后立即开发。测试用例基于等价类。
等价类
对于每个输入,等价类定义有效和无效状态。定义等价类时通常需要规划三种情况。
如果输入数据指定了范围或特定值,则会定义一个有效状态和两个无效状态。例如如果一个数字必须在1到20之间,那么有效状态就会在1到20之间,小于1的值就会有无效状态,大于20的值就会有无效状态。
如果输入数据排除某个范围或特定值,则将定义两个有效状态和一个无效状态。例如,如果数字不能介于 1 和 20 之间,则有效状态将小于 1 且大于 20,而无效状态将介于 1 和 20 之间。
如果输入指定布尔值,则只有两种状态:一个有效,一个无效。
边界值分析
边界值分析仅考虑输入数据边界处的值。例如,对于 1 到 20 之间的数字,测试用例可能是 1、20、0 和 21。其想法是,如果程序使用这些值按预期工作,则其他值也将按预期工作。
下表概述了您可能想要定义的典型边界。
| 测试范围 |
| 输入类型 |
测试值 |
| 范围 |
- x[下限]-1
- x[下限]
- x[上限]
- x[上限]+1
|
| 布尔值 |
|
制定测试计划
定义等价类并确定每个类的边界。一旦你为类定义了边界,就写出边界上可接受和不可接受的值的列表,以及预期的行为应该是什么。然后,测试人员可以使用边界值运行程序,并指出当根据所需结果测试边界值时发生的情况。
下面是用于验证输入年龄的典型测试计划,其中可接受的值范围是 10 到 110。
| 等价类 |
| 有效的 |
错误 |
| 10 至 110 之间 |
> 110 |
|
< 10 |
确定了等价类后,我们现在可以制定年龄测试计划。
| 测试计划 |
| 价值 |
状态 |
预期结果 |
实际结果 |
| 10 |
有效的 |
继续执行获取名称 |
|
| 110 |
有效的 |
继续执行获取名称 |
|
| 9 |
错误 |
再次询问年龄 |
|
| 111 |
错误 |
再次询问年龄 |
|
“实际结果”栏留空,因为它将在测试期间填写。如果结果符合预期,则会检查该列。如果没有,您应该输入评论说明发生了什么。