第5章
Cプログラミング入門
導入
「C」は現代のコンピュータの世界で最も人気のあるプログラミング言語の1つです。C プログラミング言語は、1972 年にベル研究所のブライアン・カーニハンとデニス・リッチーによって設計および作成されました。
「C」は、レジスタ、I/O スロット、絶対アドレスなど、マシンのほぼすべての内部コンポーネントにプログラマーがアクセスできるように特別に設計された言語です。同時に、「C」では、必要なだけデータ処理とプログラムされたテキストのモジュール化が可能であるため、非常に複雑なマルチプログラミング プロジェクトを組織的かつタイムリーに構築できます。
この言語はもともと UNIX 上で実行することを目的としていましたが、IBM PC および互換機上の MS-DOS オペレーティング システム上で実行することに大きな関心が寄せられました。表現がシンプルで、コードがコンパクトで、適用範囲が広いため、この環境に最適な言語です。
さらに、C コンパイラは記述がシンプルで簡単なため、マイクロコンピュータ、ミニコンピュータ、メインフレームなどの新しいコンピュータで最初に使用できる高級言語になることがよくあります。
データ復旧プログラミングにCを使用する理由
今日のコンピュータプログラミングの世界では、多くの高級言語が利用可能です。これらの言語は、ほとんどのプログラミングタスクに適した多くの機能を備えているため優れています。ただし、データ回復プログラミング、システム プログラミング、デバイス プログラミング、またはハードウェア プログラミングを行うプログラマーにとって C が第一の選択肢となる理由はいくつかあります。
- C はプロのプログラマーに好まれる人気の言語です。その結果、幅広い C コンパイラと便利なアクセサリが利用可能になりました。
- C は移植可能な言語です。あるコンピュータ システム用に作成された C プログラムは、ほとんどまたはまったく変更せずに別のシステムでコンパイルして実行できます。 C コンパイラのルールセットである C の ANSI 標準によって移植性が向上します。
- C では、プログラミングにおいてモジュールを広範囲に使用できます。C コードは関数と呼ばれるサブルーチンで記述できます。これらの関数は他のアプリケーションやプログラムで再利用できます。以前に別のアプリケーションで開発したのと同じモジュールを作成するために、新しいアプリケーションをプログラミングするときに余分な労力をかける必要はありません。
この機能は、変更なしで、または若干の変更を加えて新しいプログラムで使用できます。データ復旧プログラミングの場合、異なるプログラムの異なるアプリケーションで同じ機能を複数回実行する必要がある場合に、この特性が非常に役立ちます。
- C は強力かつ柔軟な言語です。このため、C は、オペレーティング システム、ワード プロセッサ、グラフィックス、スプレッドシート、さらには他の言語のコンパイラなど、さまざまなプロジェクトに使用されています。
- C は、言語の機能を構築する基盤として機能するキーワードと呼ばれるいくつかの用語のみを含む、数語の言語です。これらのキーワードは予約語とも呼ばれ、より強力になり、プログラミングの範囲が広がり、プログラマーは C であらゆる種類のプログラミングを実行できると感じられるようになります。
C について何も知らないと仮定します。
あなたは C プログラミングについて何も知らず、プログラミングについて何も知らないと想定しています。まず、C 言語の最も基本的な概念から始めて、ポインタ、構造体、動的メモリ割り当てといった、通常は難解な概念を含む高レベルの C プログラミングについて説明します。
これらの概念は理解するのが簡単ではないため、完全に理解するには多くの時間と労力がかかりますが、非常に強力なツールです。
C プログラミングは、アセンブリ言語を使用する必要があるが、記述と保守をシンプルにしておきたい分野で非常に役立ちます。このような場合、C でコーディングすることで節約できる時間は膨大になります。
C 言語は、プログラムをある実装から別の実装に移行する際の優れた記録を誇っていますが、別のコンパイラを使用しようとすると、コンパイラ間の違いが見つかります。
ほとんどの違いは、MS-DOS の使用時に DOS BIOS の呼び出しなどの非標準拡張機能を使用すると明らかになりますが、プログラミング構造を慎重に選択することで、これらの違いも最小限に抑えることができます。
C プログラミング言語が幅広い種類のコンピュータで利用できる非常に人気のある言語になりつつあることが明らかになったため、関係者のグループが集まり、C プログラミング言語の使用に関する標準的なルールを提案しました。
このグループはソフトウェア業界のすべての部門を代表しており、多くの会議と多くの予備草案を経て、最終的に C 言語の許容可能な標準を作成しました。この標準は、米国規格協会 (ANSI) と国際標準化機構 (ISO) によって承認されています。
これは、いかなるグループやユーザーにも強制されるものではありませんが、非常に広く受け入れられているため、コンパイラ作成者が標準への準拠を拒否することは、経済的に自殺行為となります。
この本で書かれたプログラムは、主に IBM-PC または互換コンピュータで使用するためのものですが、ANSI 標準に非常に厳密に準拠しているため、どの ANSI 標準コンパイラでも使用できます。
始めましょう
どの言語でもプログラミングを始める前に、識別子の命名方法を知っておく必要があります。識別子は、変数、関数、データ定義などに使用されます。C プログラミング言語では、識別子は英数字の組み合わせで、最初の文字はアルファベットの文字または下線で、残りの文字は任意のアルファベットの文字、任意の数字、または下線です。
識別子に名前を付けるときには、2 つのルールに留意する必要があります。
- アルファベットの大文字と小文字は区別されます。C は大文字と小文字を区別する言語です。つまり、Recovery は recovery とは異なり、rEcOveRY は前述の両方とは異なります。
- ANSI-C 標準によれば、少なくとも 31 個の重要な文字を使用でき、準拠する ANSI-C コンパイラによって重要な文字とみなされます。31 個を超える文字が使用される場合、31 個目を超える文字はすべて、特定のコンパイラによって無視される可能性があります。
キーワード
C ではキーワードとして 32 個の単語が定義されています。これらは用途があらかじめ定義されており、C プログラムでは他の目的には使用できません。これらはコンパイラによってプログラムのコンパイルを補助するために使用されます。キーワードは常に小文字で記述されます。完全なリストは次のとおりです。
| 自動車 |
壊す |
場合 |
文字 |
| 定数 |
続く |
デフォルト |
する |
| ダブル |
それ以外 |
列挙型 |
外部 |
| フロート |
のために |
行く |
もし |
| 整数 |
長さ |
登録する |
戻る |
| 短い |
署名済み |
サイズ |
静的 |
| 構造体 |
スイッチ |
型定義 |
連合 |
| 署名なし |
空所 |
不安定な |
その間 |
ここで、C の魔法がわかります。わずか32 個のキーワードというすばらしいコレクションは、さまざまなアプリケーションで幅広く使用できます。どのコンピュータ プログラムでも、データとプログラムという 2 つのエンティティを考慮する必要があります。これらは互いに大きく依存しており、両方を慎重に計画することで、よく計画され、よく書かれたプログラムが生まれます。
簡単な C プログラムから始めましょう。
/* Cを学ぶための最初のプログラム */
#include <stdio.h>
void main()
{
printf("これはCプログラムです\n"); // メッセージを出力
}
プログラムは非常にシンプルですが、注目すべき点がいくつかあります。上記のプログラムを調べてみましょう。/* と */ の内側にあるものはすべてコメントとみなされ、コンパイラによって無視されます。コメント内に他のコメントを含めるべきではないため、次のようなものは許可されません。
/* これはコメント内の /* コメント */ であり、これは間違っています */
1 行内で機能するドキュメント化の方法もあります。// を使用すると、その行内に小さなドキュメントを追加できます。
すべての C プログラムには、main という関数が含まれています。これがプログラムの開始点です。すべての関数は値を返す必要があります。このプログラムでは、関数 main は戻り値を返さないため、void main と記述しています。このプログラムは次のように記述することもできます。
/* Cを学ぶための最初のプログラム */
#include <stdio.h>
主要()
{
printf("これはCプログラムです\n"); // メッセージを出力
0を返します。
}
どちらのプログラムも同じで、同じタスクを実行します。両方のプログラムの結果は、画面に次の出力を表示します。
これはCプログラムです
#include<stdio.h>により、プログラムはコンピュータの画面、キーボード、ファイル システムと対話できるようになります。これは、ほぼすべての C プログラムの先頭にあります。
main() は関数の開始を宣言し、2 つの中括弧は関数の開始と終了を示します。C 言語の中括弧は、関数内やループ本体内でステートメントをグループ化するために使用されます。このようなグループ化は、複合ステートメントまたはブロックと呼ばれます。
printf("これは C プログラムです\n"); は、画面に単語を出力します。 印刷するテキストは二重引用符で囲みます。 テキストの末尾の \n は、出力の一部として新しい行を印刷するようにプログラムに指示します。 printf() 関数は、出力のモニター表示に使用されます。
C プログラムのほとんどは小文字で書かれています。大文字は、後で説明するプリプロセッサ定義や、文字列の一部として引用符内で使用されていることがよくあります。
プログラムのコンパイル
プログラムの名前を CPROG.C とします。C プログラムを入力してコンパイルするには、次の手順に従います。
- C プログラムのアクティブ ディレクトリを作成し、エディターを起動します。このために任意のテキスト エディターを使用できますが、Borland の Turbo C++ などのほとんどの C コンパイラには、プログラムの入力、コンパイル、リンクを 1 つの便利な設定で実行できる統合開発環境 (IDE) があります。
- ソース コードを記述して保存します。ファイルの名前は CPROG.C にする必要があります。
- CPROG.C をコンパイルしてリンクします。コンパイラのマニュアルで指定されている適切なコマンドを実行します。エラーや警告がないことを示すメッセージが表示されます。
- コンパイラのメッセージを確認します。エラーや警告が表示されない場合は、すべて正常です。プログラムの入力にエラーがある場合は、コンパイラがそれを検出し、エラー メッセージを表示します。エラー メッセージに表示されたエラーを修正します。
- 最初の C プログラムがコンパイルされ、実行できる状態になりました。CPROG という名前のすべてのファイルのディレクトリ リストを表示すると、次のように異なる拡張子を持つ 4 つのファイルが表示されます。
- CPROG.C、ソースコードファイル
- CPROG.BAK、エディタで作成したソースファイルのバックアップファイル
- CPROG.OBJにはCPROG.Cのオブジェクトコードが含まれています。
- CPROG.EXE、CPROG.C をコンパイルしてリンクしたときに作成される実行可能プログラム
- CPROG.EXE を実行するには、単に cprog と入力します。画面に「これは C プログラムです」というメッセージが表示されます。
それでは次のプログラムを調べてみましょう。
/* Cを学ぶための最初のプログラム */ // 1
// 2
#include <stdio.h> // 3
// 4
メイン() // 5
{
// 6
printf("これはCプログラムです\n"); // 7
// 8
0を返す; // 9
} // 10
このプログラムをコンパイルすると、コンパイラは次のようなメッセージを表示します。
cprog.c(8) : エラー: `;' が必要です
このエラー メッセージをいくつかの部分に分解してみましょう。cprog.c はエラーが見つかったファイルの名前です。(8) はエラーが見つかった行番号です。エラー: `;' が必要です はエラーの説明です。
このメッセージは非常に有益で、CPROG.C の 8 行目にコンパイラがセミコロンがあると予想したが、見つからなかったことを伝えます。ただし、実際には 7 行目からセミコロンが省略されているため、矛盾が生じています。
実際には 7 行目からセミコロンが省略されているのに、なぜコンパイラは 8 行目でエラーを報告するのでしょうか。その答えは、C では行間の区切りなどは考慮されないという事実にあります。printf() ステートメントの後のセミコロンは次の行に置くこともできますが、そうすると実際にはプログラミングとして不適切になります。
8 行目で次のコマンド (return) に遭遇して初めて、コンパイラーはセミコロンが欠落していることを確信します。したがって、コンパイラーはエラーが 8 行目にあることを報告します。
さまざまなタイプのエラーが発生する可能性が多数あります。リンク エラー メッセージについて説明します。リンカー エラーは比較的まれで、通常は C ライブラリ関数の名前のスペルミスが原因で発生します。この場合、「Error: undefined symbol:」というエラー メッセージが出力され、その後にスペルミスした名前が表示されます。スペルを修正すると、問題は解消されます。
数字の印刷
次の例を見てみましょう。
// 数字を印刷する方法 //
#include<stdio.h>
void main()
{
整数 = 10;
printf(“ 数は %d です”, num);
}
プログラムの出力は次のように画面に表示されます。
数字は10
% 記号は、さまざまなタイプの変数の出力を通知するために使用されます。% 記号の後の文字は ad で、出力ルーチンに 10 進数値を取得して出力するように通知します。
変数の使用
C では、変数は使用する前に宣言する必要があります。変数は任意のコード ブロックの先頭で宣言できますが、ほとんどの変数は各関数の先頭にあります。ほとんどのローカル変数は関数が呼び出されたときに作成され、その関数から戻ると破棄されます。
C プログラムで変数を使用するには、C で変数に名前を付けるときに次の規則を知っておく必要があります。
- 名前には、文字、数字、アンダースコア文字 (_) を含めることができます。
- 名前の最初の文字は文字でなければなりません。アンダースコアも最初の文字として有効ですが、使用はお勧めしません。
- C は大文字と小文字を区別するため、変数名 num は Num とは異なります。
- C キーワードは変数名として使用できません。キーワードは C 言語の一部である単語です。
次のリストには、有効な C 変数名と無効な C 変数名の例がいくつか含まれています。
| 変数名 |
合法か否か |
| で |
法律上の |
| 翻訳: |
法律上の |
| ttpt |
違法: スペースは許可されていません |
| _1990_税 |
合法だが推奨されない |
| ジャックフォン# |
不正: 不正な文字 # が含まれています |
| 場合 |
不正: Cのキーワードです |
| 1冊 |
不正: 最初の文字が数字です |
最初に目立つ新しい点は、main() の本体の最初の行です。
整数 = 10;
この行は、int 型の 'num' という名前の変数を定義し、それを値 10 で初期化します。これは次のように記述することもできます。
int num; /* 初期化されていない変数 'num' を定義する */
/* すべての変数定義の後: */
num = 10; /* 変数 'num' に値 10 を割り当てます */
変数はブロックの先頭(中括弧 { と } の間)で定義できます。通常は関数本体の先頭ですが、別の種類のブロックの先頭でも定義できます。
ブロックの先頭で定義された変数は、デフォルトで「自動」ステータスになります。つまり、ブロックの実行中にのみ存在します。関数の実行が開始されると、変数は作成されますが、その内容は未定義になります。関数が戻ると、変数は破棄されます。定義は次のように記述することもできます。
自動整数数値 = 10;
auto キーワードの有無にかかわらず定義は完全に同等であるため、 auto キーワードは明らかに冗長です。
しかし、これが望ましくない場合もあります。関数が呼び出された回数をカウントしたいとします。関数が戻るたびに変数が破棄されると、これは不可能になります。
したがって、変数に静的持続時間と呼ばれるものを与えることが可能であり、これはプログラムの実行全体を通じて変数がそのまま残ることを意味します。例:
静的整数 = 10;
これにより、プログラム実行の開始時に変数 num が 10 に初期化されます。それ以降、値は変更されません。関数が複数回呼び出されても、変数は再初期化されません。
場合によっては、変数に 1 つの関数からのみアクセスできるだけでは不十分であったり、それを必要とする他のすべての関数にパラメータを介して値を渡すことが不便な場合があります。
しかし、ソース ファイル全体のすべての関数から変数にアクセスする必要がある場合は、static キーワードを使用して、定義をすべての関数の外側に配置することでこれを行うこともできます。例:
#include <stdio.h>
static int num = 10; /* ソースファイル全体からアクセス可能 */
int メイン(void)
{
printf("数は: %d\n", num);
0を返します。
}
また、複数のソース ファイルで構成されるプログラム全体から変数にアクセスできるようにする必要がある場合もあります。これはグローバル変数と呼ばれ、必要がない場合は使用を避ける必要があります。
これは、static キーワードを使用せずに、すべての関数の外側に定義を配置することによっても実行されます。
#include <stdio.h>
int num = 10; /* プログラム全体からアクセス可能になります! */
int メイン(void)
{
printf("数は: %d\n", num);
0を返します。
}
また、他のモジュールのグローバル変数にアクセスするために使用される extern キーワードもあります。変数定義に追加できる修飾子もいくつかあります。その中で最も重要なのは const です。const として定義された変数は変更できません。
あまり一般的に使用されない修飾子があと 2 つあります。 volatile 修飾子と register 修飾子です。 volatile 修飾子では、コンパイラは変数が読み取られるたびに実際に変数にアクセスする必要があります。 変数をレジスタなどに配置することで最適化されない場合があります。 これは主に、マルチスレッドや割り込み処理などの目的で使用されます。
レジスタ修飾子は、変数をレジスタに最適化するようにコンパイラに要求します。これは自動変数でのみ可能であり、多くの場合、コンパイラはレジスタに最適化する変数をより適切に選択できるため、このキーワードは廃止されています。変数をレジスタにすることによる唯一の直接的な影響は、そのアドレスを取得できないことです。
次のページに示す変数の表では、5 種類のストレージ クラスのストレージ クラスについて説明します。
表では、キーワード extern が 2 行に配置されています。extern キーワードは、関数内で、他の場所で定義されている静的な外部変数を宣言するために使用されます。
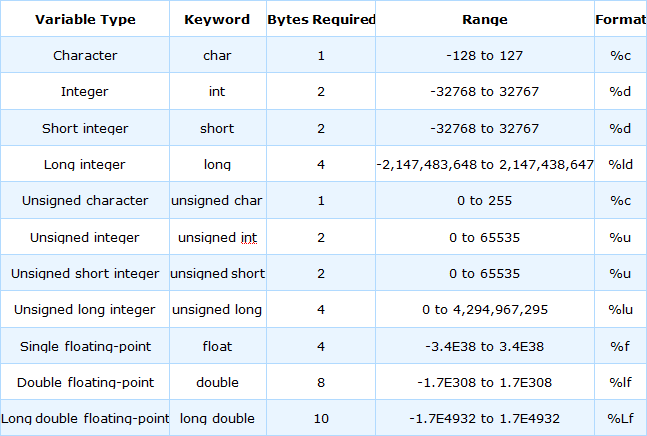
数値変数の型
C では、数値によってメモリ ストレージ要件が異なるため、いくつかの異なるタイプの数値変数が用意されています。これらの数値タイプは、特定の数学演算を実行する際の容易さが異なります。
小さな整数は保存に必要なメモリが少なく、コンピュータはそのような数値を使用して非常に高速に数学演算を実行できます。大きな整数と浮動小数点値には、より多くのストレージ スペースと数学演算に必要な時間がより多く必要です。適切な変数型を使用することで、プログラムが可能な限り効率的に実行されるようになります。
C の数値変数は、次の 2 つの主なカテゴリに分類されます。
これらの各カテゴリには、2 つ以上の特定の変数タイプがあります。次の表は、各タイプの単一の変数を保持するために必要なメモリの量 (バイト単位) を示しています。
char 型は signed char または unsigned char のいずれかと同等である可能性がありますが、常にこれらのいずれかとは別の型です。
C では、変数に文字を格納するか、それに対応する数値を格納するかに違いはありません。そのため、文字と数値の間、またはその逆の変換を行う関数も必要ありません。その他の整数型の場合、signed または unsigned を省略すると、デフォルトで signed になります。つまり、たとえば int と signed int は同等です。
int 型は short 型以上で、long 型以下である必要があります。非常に大きくない値を保存するだけの場合は、int 型を使用するのが得策です。通常、このサイズはプロセッサが最も簡単に処理できるため、最も高速です。
いくつかのコンパイラでは、double と long double は同等です。ほとんどの標準的な数学関数が double 型で動作するという事実と合わせて、小数を扱う必要がある場合は常に double 型を使用するのが妥当です。
次の表は、変数の種類をより詳しく説明したものです。
一般的に使用される特殊用途タイプ:
| 変数タイプ |
説明 |
| サイズ |
オブジェクトのサイズをバイト単位で保存するために使用される符号なし型 |
| 時間_t |
time() 関数の結果を保存するために使用される |
| 時計t |
clock() 関数の結果を保存するために使用される |
| ファイル |
ストリーム(通常はファイルまたはデバイス)にアクセスするために使用される |
| ptrdiff_t |
2つのポインタの差の符号付き型 |
| div_t |
div() 関数の結果を保存するために使用される |
| 翻訳: |
ldiv() 関数の結果を格納するために使用されます |
| 位置_t |
ファイルの位置情報を保持するために使用される |
| ウィルリスト |
可変引数処理で使用される |
| char_t型 |
ワイド文字タイプ(拡張文字セットに使用) |
| sig_atomic_t |
シグナルハンドラで使用される |
| ジャンプバッファ |
非局所ジャンプに使用される |
これらの変数をよりよく理解するために、例を見てみましょう。
/* C 変数の範囲とサイズをバイト単位で示すプログラム */
#include <stdio.h>
int メイン()
{
int a; /* 単純な整数型 */
long int b; /* 長整数型 */
short int c; /* 短整数型 */
unsigned int d; /* 符号なし整数型 */
char e; /* 文字型 */
float f; /* 浮動小数点型 */
double g; /* 倍精度浮動小数点数 */
= 1023;
2222;
123;
d = 1234;
e = 'X';
f = 3.14159;
グラム = 3.1415926535898;
printf( "\n文字は%dバイトです", sizeof( char ));
printf( "\nint は %d バイトです", sizeof( int ));
printf( "\nshort は %d バイトです", sizeof( short ));
printf( "\nlong は %d バイトです", sizeof( long ));
printf( "\nunsigned char は %d バイトです",
sizeof(符号なしchar));
printf( "\n符号なし整数は%dバイトです",
sizeof(符号なし整数));
printf( "\nunsigned short は %d バイトです",
sizeof(符号なしショート));
printf( "\nunsigned long は %d バイトです",
sizeof(符号なしlong));
printf( "\nfloat は %d バイトです", sizeof( float ));
printf( "\ndouble は %d バイトです\n", sizeof( double ));
printf("a = %d\n", a); /* 10進数出力 */
printf("a = %o\n", a); /* 8進数出力 */
printf("a = %x\n", a); /* 16進数出力 */
printf("b = %ld\n", b); /* 10進数のlong出力 */
printf("c = %d\n", c); /* 10進数の短い出力 */
printf("d = %u\n", d); /* 符号なし出力 */
printf("e = %c\n", e); /* 文字出力 */
printf("f = %f\n", f); /* 浮動小数点出力 */
printf("g = %f\n", g); /* 倍精度浮動小数点出力 */
printf("\n");
printf("a = %d\n", a); /* 単純な int 出力 */
printf("a = %7d\n", a); /* フィールド幅 7 を使用します */
printf("a = %-7d\n", a); /* 左揃え
7のフィールド*/
5;
d = 8;
printf("a = %*d\n", c, a); /* フィールド幅を 5 にする*/
printf("a = %*d\n", d, a); /* フィールド幅を 8 にする */
printf("\n");
printf("f = %f\n", f); /* 単純な浮動小数点出力 */
printf("f = %12f\n", f); /* フィールド幅 12 を使用する */
printf("f = %12.3f\n", f); /* 小数点以下3桁を使用 */
printf("f = %12.5f\n", f); /* 小数点以下5桁を使用 */
printf("f = %-12.5f\n", f); /* フィールド内で左揃え */
0を返します。
}
実行後のプログラムの結果は次のように表示されます。
文字は1バイトです
intは2バイトです
ショートは2バイト
longは4バイトです
符号なし文字は1バイトです
符号なし整数は2バイトです
符号なしショートは2バイトです
符号なしlongは4バイトです
浮動小数点は4バイト
doubleは8バイトです
a = 1023
a = 1777
a = 3ff
2222 です
123 です
d = 1234
e = X
3.141590 の
グラム = 3.141593
a = 1023
a = 1023
a = 1023
a = 1023
a = 1023
3.141590 の
3.141590 の
3.142 の
3.14159 の
3.14159 の |
C プログラムで変数を使用するには、その前に宣言する必要があります。変数宣言は、変数の名前と型をコンパイラーに伝え、オプションで変数を特定の値に初期化します。
プログラムが宣言されていない変数を使用しようとすると、コンパイラはエラー メッセージを生成します。変数宣言の形式は次のとおりです。
型名 変数名;
typename は変数の型を指定し、キーワードの 1 つである必要があります。varname は変数名です。変数名をコンマで区切ることで、1 行に同じ型の複数の変数を宣言できます。
int count, number, start; /* 3つの整数変数 */
float percent, total; /* 2つのfloat変数 */
typedef キーワード
typedefキーワードは、既存のデータ型に新しい名前を作成するために使用されます。実際には、typedefはシノニムを作成します。たとえば、次の文は
typedef int 整数;
ここで、typedef は int の同義語として integer を作成します。次に、次の例のように、integer を使用して int 型の変数を定義できます。
整数カウント;
したがって、typedef は新しいデータ型を作成するのではなく、定義済みのデータ型に別の名前を使用できるようにするだけです。
数値変数の初期化
変数が宣言されると、コンパイラは変数用の記憶領域を確保するように指示されます。ただし、その領域に格納される値、つまり変数の値は定義されていません。ゼロになる場合もあれば、ランダムな「ガベージ」値になる場合もあります。変数を使用する前に、必ず既知の値に初期化する必要があります。次の例を見てみましょう。
int count; /* count 用の記憶領域を確保します */
count = 0; /* countに0を格納 */
このステートメントでは、C の代入演算子である等号 (=) を使用します。変数は宣言時に初期化することもできます。そのためには、宣言ステートメントの変数名の後に等号と希望する初期値を続けてください。
整数カウント = 0;
倍数率 = 0.01、複雑度 = 28.5;
許容範囲外の値で変数を初期化しないように注意してください。範囲外の初期化の例を 2 つ示します。
整数量 = 100000;
符号なし整数の長さ = -2500;
C コンパイラはこのようなエラーを検出しません。プログラムはコンパイルおよびリンクできますが、プログラムを実行すると予期しない結果が生じる可能性があります。
次の例を使用して、ディスク内のセクターの合計数を計算してみましょう。
// ディスクのセクターを計算するモデル プログラム //
#include<stdio.h>
#SECTOR_PER_SIDE 63 を定義する
#define SIDE_PER_CYLINDER 254
void main()
{
シリンダー=0;
clrscr();
printf("ディスクのシリンダー数を入力してください\n\n\t");
scanf("%d",&cylinder); // ユーザーから値を取得します //
printf("\n\n\t ディスク内のセクターの総数 = %ld", (long)SECTOR_PER_SIDE*SIDE_PER_CYLINDER* シリンダー);
getch();
}
プログラムの出力は次のようになります。
ディスク内のシリンダーの数を入力してください
1024
ディスク内のセクターの総数 = 16386048
この例では、学ぶべき新しいことが 3 つあります。#define は、プログラム内で記号定数を使用するために使用します。また、長い単語を小さな記号で定義して時間を節約する場合もあります。
ここでは、プログラムを理解しやすくするために、片面あたりのセクター数 63 を SECTOR_PER_SIDE として定義しています。#define SIDE_PER_CYLINDER 254 の場合も同様です。ユーザーからの入力を取得するには scanf() を使用します。
ここでは、シリンダーの数をユーザーからの入力として取得します。例に示すように、* は 2 つ以上の値を乗算するために使用されます。
getch() 関数は基本的にキーボードから 1 文字の入力を取得します。ここで getch(); と入力すると、キーボードから任意のキーが押されるまで画面が停止します。
オペレーター
演算子は、1 つ以上のオペランドに対して何らかの操作またはアクションを実行するように C に指示する記号です。オペランドは、演算子が作用する対象です。C では、すべてのオペランドは式です。C の演算子は、次の 4 つのカテゴリに分類されます。
代入演算子
代入演算子は等号(=)です。プログラミングにおける等号の使い方は、通常の数学的代数関係における等号の使い方とは異なります。
y = 0 です。
C プログラムでは、これは「x は y に等しい」という意味ではありません。代わりに、「y の値を x に割り当てる」という意味になります。C の代入文では、右側には任意の式を指定でき、左側には変数名を指定する必要があります。したがって、形式は次のようになります。
変数 = 式;
実行中に式が評価され、結果の値が変数に割り当てられます。
数学演算子
C の数学演算子は、加算や減算などの数学演算を実行します。C には、2 つの単項数学演算子と 5 つの二項数学演算子があります。単項数学演算子は、単一のオペランドを取るため、このように呼ばれています。C には、2 つの単項数学演算子があります。
インクリメント演算子とデクリメント演算子は、定数ではなく変数でのみ使用できます。実行される演算は、オペランドに 1 を加算するか、オペランドから 1 を減算することです。つまり、ステートメント ++x; と --y; は、次のステートメントと同等です。
x = x + 1;
y = y - 1;
二項演算子は 2 つのオペランドを取ります。最初の 4 つの二項演算子には、計算機でよく使われる数学演算 (+、-、、/) が含まれており、よく知られています。5 番目の演算子 Modulus は、最初のオペランドを 2 番目のオペランドで割った余りを返します。たとえば、11 を 4 で割ると 3 になります (11 を 4 で割ると 2 回で 3 余ります)。
関係演算子
C の関係演算子は式を比較するために使用されます。関係演算子を含む式は、真 (1) または偽 (0) のいずれかに評価されます。C には 6 つの関係演算子があります。
論理演算子
C の論理演算子を使用すると、2 つ以上の関係式を、true または false のいずれかに評価される単一の式に結合できます。論理演算子は、オペランドの true または false の値に応じて、true または false のいずれかに評価されます。
x が整数変数の場合、論理演算子を使用する式は次のように記述できます。
(x > 1) && (x < 5)
(x >= 2) && (x <= 4)
| オペレーター |
シンボル |
説明 |
例 |
| 代入演算子 |
| 等しい |
= |
yの値をxに割り当てる |
x = y |
| 数学演算子 |
| インクリメント |
++ |
オペランドを1つ増やす |
++x、x++ |
| デクリメント |
-- |
オペランドを1つ減らす |
--x、x-- |
| 追加 |
+ |
2つのオペランドを加算する |
x + y |
| 減算 |
- |
2番目のオペランドを最初のオペランドから減算します |
x - y |
| 乗算 |
* |
2つのオペランドを乗算します |
x * y |
| 分割 |
/ |
最初のオペランドを2番目のオペランドで割ります |
x / y |
| 係数 |
% |
最初のオペランドを2番目のオペランドで割った余りを返します |
x % と |
| 関係演算子 |
| 等しい |
= = |
平等 |
x = = y |
| より大きい |
> |
より大きい |
x > y |
| 未満 |
< |
未満 |
x < y |
| より大きいか等しい |
>= |
より大きいか等しい |
x >= y |
| 以下 |
<= |
以下 |
x <= y |
| 等しくない |
!= |
等しくない |
x != y |
| 論理演算子 |
| そして |
&& |
exp1とexp2の両方が真の場合にのみ真(1)、それ以外の場合は偽(0) |
exp1 && exp2 |
| または |
|| |
exp1またはexp2 のいずれかが真の場合は真 (1) 、両方が偽の場合のみ偽 (0) |
exp1 || exp2 |
| ない |
! |
exp1が真の場合は偽(0) 、偽の場合は真(1) |
!exp1 |
論理式について覚えておくべきこと
| x * = y |
と同じです |
x = x * y |
| y - = z + 1 |
と同じです |
y = y - z + 1 |
| a / = b |
と同じです |
a = a / b |
| x + = y / 8 |
と同じです |
x = x + y / 8 |
| そして % = 3 |
と同じです |
y = y % 3 |
カンマ演算子
C では、カンマは変数宣言や関数の引数などを区切るための単純な句読点として頻繁に使用されます。特定の状況では、カンマは演算子として機能します。
2 つのサブ式をコンマで区切って式を作成できます。結果は次のようになります。
- 両方の式が評価され、左の式が最初に評価されます。
- 式全体は右側の式の値に評価されます。
たとえば、次のステートメントは、b の値を x に割り当て、次に a を増分し、次に b を増分します: x = (a++, b++);
C 演算子の優先順位 (C 演算子の概要)
| 順位と関連性 |
オペレーター |
| 1 (左から右) |
() [] -> . |
| 2(右から左) |
! ~ ++ -- * (間接) & (アドレス) (型) sizeof + (単項) - (単項) |
| 3 (左から右) |
* (乗算) / % |
| 4 (左から右) |
+ - |
| 5 (左から右) |
<< >> |
| 6 (左から右) |
< <= > >= |
| 7 (左から右) |
= = != |
| 8 (左から右) |
& (ビットAND ) |
| 9 (左から右) |
^ |
| 10(左から右) |
| |
| 11 (左から右) |
&& |
| 12(左から右) |
|| |
| 13 (右から左) |
?: |
| 14(右から左へ) |
= += -= *= /= %= &= ^= |= <<= >>= |
| 15(左から右) |
、 |
| ()は関数演算子、[]は配列演算子です。 |
|
演算子の使用例を見てみましょう。
/* 演算子の使用 */
int メイン()
{
整数x = 0、y = 2、z = 1025;
浮動小数点数 a = 0.0、b = 3.14159、c = -37.234;
/* 増加 */
x = x + 1; /* これは x を増分します */
x++; /* x を増分します */
++x; /* これは x を増分します */
z = y++; /* z = 2、y = 3 */
z = ++y; /* z = 4, y = 4 */
/* 減算 */
y = y - 1; /* これはyを減算します */
y--; /* y を減算します */
--y; /* y を減算します */
y = 3;
z = y--; /* z = 3, y = 2 */
z = --y; /* z = 1、y = 1 */
/* 算術演算 */
a = a + 12; /* これは a に 12 を加えます */
a += 12; /* これは a にさらに 12 を加えます */
a *= 3.2; /* これは a を 3.2 倍します */
a -= b; /* これはaからbを減算します */
a /= 10.0; /* これは a を 10.0 で割ります */
/* 条件式 */
a = (b >= 3.0 ? 2.0 : 10.5 ); /* この式 */
if (b >= 3.0) /* そしてこの式 */
a = 2.0; /* 両方とも同一です */
そうでなければ /* 同じ結果になる */
a = 10.5; /* 結果 */
c = (a > b ? a : b); /* c は a または b の最大値を持ちます */
c = (a > b ? b : a); /* c は a または b の最小値を持ちます */
printf("x=%d, y=%d, z= %d\n", x, y, z);
printf("a=%f, b=%f, c= %f", a, b, c);
0を返します。
}
このプログラムの結果は次のように画面に表示されます。
x=3、y=1、z=1
a=2.000000、b=3.141590、c=2.000000
printf() と Scanf() についてもう少し
次の2つのprintf文を考えてみましょう
printf(“\t %d\n”, 数値);
printf(“%5.2f”, フラクト);
最初の printf ステートメント \t は画面上のタブの変位を要求し、引数 %d は num の値を 10 進整数として印刷するようにコンパイラに指示します。\n により、新しい出力が新しい行から始まります。
2 番目の printf ステートメント %5.2f は、出力が全部で 5 桁、小数点の右側に 2 桁の浮動小数点数でなければならないことをコンパイラに伝えます。バックスラッシュ文字の詳細については、次の表を参照してください。
| 絶え間ない |
意味 |
| '\a' |
警報音(ベル) |
| '\b' |
バックスペース |
| '\f' |
フォームフィード |
| '\n' |
改行 |
| '\r' |
キャリッジリターン |
| '\t' |
水平タブ |
| '\v' |
垂直タブ |
| '\'' |
一重引用符 |
| '\”' |
二重引用符 |
| '\?' |
疑問符 |
| '\\' |
バックスラッシュ |
| '\0' |
ヌル |
次のscanf文を考えてみましょう
scanf(“%d”, &num);
キーボードからのデータは scanf 関数で受信します。上記フォーマットにおいて、各変数名の前の & (アンパサンド) 記号は、変数名のアドレスを指定する演算子です。
こうすることで、実行が停止し、変数 num の値が入力されるのを待ちます。整数値が入力されてリターン キーが押されると、コンピューターは次のステートメントに進みます。scanf および printf のフォーマット コードを次の表に示します。
| コード |
読み取り... |
| %c |
単一文字 |
| %d |
10進整数 |
| %そして |
浮動小数点値 |
| %f |
浮動小数点値 |
| %g |
浮動小数点値 |
| %h |
短整数 |
| %私 |
10進数、16進数、8進数の整数 |
| %の |
8進整数 |
| %s |
弦 |
| %で |
符号なし10進整数 |
| %x |
16進整数 |
制御文
プログラムは、通常、順番に実行される多数のステートメントで構成されます。ステートメントの実行順序を制御できれば、プログラムはより強力になります。
ステートメントは、一般的に次の 3 つのタイプに分類されます。
- 代入では、値(通常は計算結果)が変数に格納されます。
- 入出力、データが読み込まれたり、印刷されたりします。
- 制御では、プログラムが次に何を行うかを決定します。
このセクションでは、C における制御文の使用について説明します。制御文を使用して、次のような強力なプログラムを作成する方法を説明します。
- プログラムの重要なセクションを繰り返します。
- プログラムのオプションセクションを選択します。
if else 文
これは、特別な時点で何かを実行するかどうかを決定する場合、または 2 つの行動方針のどちらかを決定する場合に使用されます。
次のテストは、学生が45点以上の合格点で試験に合格したかどうかを判定します。
(結果 >= 45)の場合
printf("合格\n");
それ以外
printf("失敗\n");
else なしで if 部分を使用することも可能です。
(温度<0)の場合
print("凍結\n");
各バージョンは、if に続く括弧内のステートメント内のテストで構成されます。テストが true の場合、次のステートメントに従います。テストが false の場合、else に続くステートメントがあればそれに従います。その後、プログラムの残りの部分は通常どおり続行されます。
if または else の後に複数のステートメントを続ける場合は、それらを中括弧でグループ化する必要があります。このようなグループ化は複合ステートメントまたはブロックと呼ばれます。
(結果 >= 45)の場合
{ printf("合格\n");
printf("おめでとうございます\n");
}
それ以外
{ printf("失敗しました\n");
printf("次回はもっと幸運を祈ります\n");
}
場合によっては、複数の条件に基づいて多角的な決定を下したいことがあります。これを行う最も一般的な方法は、if ステートメントで else if バリアントを使用することです。
これは、複数の比較をカスケードすることで機能します。これらの比較の 1 つが true の結果を出すとすぐに、次のステートメントまたはブロックが実行され、それ以上の比較は実行されません。次の例では、試験の結果に応じて成績を授与しています。
(結果 <= 100 && 結果 >= 75) の場合
printf("合格: 評価A\n");
そうでない場合 (結果 >= 60)
printf("合格: 評価B\n");
そうでない場合 (結果 >= 45)
printf("合格: 評価C\n");
それ以外
printf("失敗しました\n");
この例では、すべての比較は result という単一の変数をテストします。他の場合には、各テストに異なる変数またはいくつかのテストの組み合わせが含まれる場合があります。同じパターンを、else if の数を増やしたり減らしたりして使用したり、最後の else だけを省略したりすることもできます。
それぞれのプログラミング問題に対して正しい構造を考案するのはプログラマーの責任です。if elseの使い方をよりよく理解するために、例を見てみましょう。
#include <stdio.h>
int メイン()
{
整数 数値;
(num = 0 ; num < 10 ; num = num + 1) の場合
{
(数値 == 2)の場合
printf("num は現在 %d に等しくなります\n", num);
(数値<5)の場合
printf("num は現在 %d で、5 未満です\n", num);
それ以外
printf("num は現在 %d で、4 より大きいです\n", num);
} /* forループの終了 */
0を返します。
}
プログラムの結果
numは現在0で、5未満です
numは現在1で、5未満です
num は 2 になりました
numは現在2で、5未満です
numは現在3で、5未満です
numは現在4で、5未満です
numは現在5で、4より大きいです
numは現在6で、4より大きいです
numは現在7で、4より大きいです
numは現在8で、4より大きいです
numは現在9で、4より大きいです
switch ステートメント
これは、マルチウェイ決定の別の形式です。適切に構造化されていますが、次のような特定の場合にのみ使用できます。
- テストされる変数は 1 つだけであり、すべてのブランチはその変数の値に依存する必要があります。変数は整数型である必要があります。(int、long、short、または char)。
- 変数の可能な値ごとに、単一のブランチを制御できます。最後に、すべてをキャッチするデフォルトのブランチをオプションで使用して、指定されていないすべてのケースをトラップすることもできます。
以下に示す例を見れば、状況が明らかになるでしょう。これは、整数を漠然とした説明に変換する関数です。非常に小さい量の測定のみに関心がある場合に便利です。
推定(数値)
int 数値;
/* 数を 0、1、2、複数、多数 と推定します */
{ スイッチ(数値) {
ケース0:
printf("なし\n");
壊す;
ケース1:
printf("1\n");
壊す;
ケース2:
printf("2\n");
壊す;
ケース3:
ケース4:
ケース5:
printf("いくつか\n");
壊す;
デフォルト :
printf("多数\n");
壊す;
}
}
それぞれの興味深いケースは、対応するアクションとともにリストされます。break ステートメントは、switch を終了してそれ以上のステートメントが実行されないようにします。case 3 と case 4 には後続の break がないため、複数の number 値に対して同じアクションを許可して続行します。
if と switch の両方の構文により、プログラマーはいくつかの可能なアクションから選択を行うことができます。例を見てみましょう。
#include <stdio.h>
int メイン()
{
整数 数値;
(num = 3 ; num < 13 ; num = num + 1) の場合
{
スイッチ(数字)
{
ケース3:
printf("値は3です\n");
壊す;
ケース4:
printf("値は4です\n");
壊す;
ケース5:
ケース6:
ケース7:
ケース8:
printf("値は5から8の間です\n");
壊す;
ケース11:
printf("値は11です\n");
壊す;
デフォルト :
printf("未定義の値の1つです\n");
壊す;
} /* スイッチの終了 */
} /* forループの終了 */
0を返します。
}
プログラムの出力は次のようになります
値は3です
値は4です
値は5から8の間です
値は5から8の間です
値は5から8の間です
値は5から8の間です
これは未定義の値の1つです
これは未定義の値の1つです
値は11です
これは未定義の値の1つです
break ステートメント
We have already met break in the discussion of the switch statement. It is used to exit from a loop or a switch, control passing to the first statement beyond the loop or a switch.
With loops, break can be used to force an early exit from the loop, or to implement a loop with a test to exit in the middle of the loop body. A break within a loop should always be protected within an if statement which provides the test to control the exit condition.
The continue Statement
This is similar to break but is encountered less frequently. It only works within loops where its effect is to force an immediate jump to the loop control statement.
- In a while loop, jump to the test statement.
- In a do while loop, jump to the test statement.
- In a for loop, jump to the test, and perform the iteration.
Like a break, continue should be protected by an if statement. You are unlikely to use it very often. To better understand the use of break and continue let us examine the following program:
#include <stdio.h>
int main()
{
int value;
for(value = 5 ; value < 15 ; value = value + 1)
{
if (value == 8)
break;
printf("In the break loop, value is now %d\n", value);
}
for(value = 5 ; value < 15 ; value = value + 1)
{
if (value == 8)
continue;
printf("In the continue loop, value is now %d\n", value);
}
return 0;
}
The output of the program will be as follows:
In the break loop, value is now 5
In the break loop, value is now 6
In the break loop, value is now 7
In the continue loop, value is now 5
In the continue loop, value is now 6
In the continue loop, value is now 7
In the continue loop, value is now 9
In the continue loop, value is now 10
In the continue loop, value is now 11
In the continue loop, value is now 12
In the continue loop, value is now 13
In the continue loop, value is now 14
Loops
The other main type of control statement is the loop. Loops allow a statement, or block of statements, to be repeated. Computers are very good at repeating simple tasks many times. The loop is C's way of achieving this.
C gives you a choice of three types of loop, while, do-while and for.
- The while loop keeps repeating an action until an associated test returns false. This is useful where the programmer does not know in advance how many times the loop will be traversed.
- The do while loops is similar, but the test occurs after the loop body is executed. This ensures that the loop body is run at least once.
- The for loop is frequently used, usually where the loop will be traversed a fixed number of times. It is very flexible, and novice programmers should take care not to abuse the power it offers.
The while Loop
while ループは、先頭のテストが偽であると判明するまでステートメントを繰り返します。例として、文字列の長さを返す関数を次に示します。文字列は、ヌル文字 '\0' で終了する文字の配列として表されることに注意してください。
int 文字列の長さ(char 文字列[])
{ int i = 0;
while (文字列[i] != '\0')
私は++;
戻り値:
}
文字列は引数として関数に渡されます。配列のサイズは指定されていないため、関数は任意のサイズの文字列に対して機能します。
while ループは、ヌル文字が見つかるまで文字列内の文字を 1 つずつ調べるために使用されます。その後、ループが終了し、ヌルのインデックスが返されます。
文字が null でない限り、インデックスが増分され、テストが繰り返されます。配列については後で詳しく説明します。while ループの例を見てみましょう。
#include <stdio.h>
int メイン()
{
整数カウント;
カウント = 0;
(カウント < 6)
{
printf("countの値は%dです\n", count);
カウント = カウント + 1;
}
0を返します。
}
結果は次のように表示されます。
countの値は0です
countの値は1です
countの値は2です
countの値は3です
countの値は4です
countの値は5です
do whileループ
これは while ループと非常によく似ていますが、テストがループ本体の最後に行われる点が異なります。これにより、続行する前にループが少なくとも 1 回実行されることが保証されます。
このような設定は、データを読み取る場合によく使用されます。テストではデータを検証し、許容できない場合は再度読み取りに戻ります。
する
{
printf("はいの場合は1、いいえの場合は0を入力してください:");
scanf("%d", &入力値);
} while (入力値 != 1 && 入力値 != 0)
do while ループをよりよく理解するために、次の例を見てみましょう。
#include <stdio.h>
int メイン()
{
整数 i;
私 = 0;
する
{
printf("i の値は現在 %d です\n", i);
i = i + 1;
} i < 5 の間;
0を返します。
}
プログラムの結果は次のように表示されます。
iの値は0になりました
iの値は1です
iの値は2です
iの値は3です
iの値は4です
for ループ
for ループは、ループに入る前にループの反復回数がわかっている場合にうまく機能します。ループの先頭は、セミコロンで区切られた 3 つの部分で構成されます。
- 最初のものはループに入る前に実行されます。これは通常、ループ変数の初期化です。
- 2 番目はテストで、これが false を返すとループが終了します。
- 3 番目は、ループ本体が完了するたびに実行されるステートメントです。これは通常、ループ カウンターの増分です。
この例は、配列に格納されている数値の平均を計算する関数です。この関数は、配列と要素の数を引数として受け取ります。
float 平均(float 配列[], int カウント)
{
浮動小数点合計 = 0.0;
整数 i;
(i = 0; i < count; i++) の場合
合計 += 配列[i];
return(合計 / カウント);
}
for ループは、平均を計算する前に正しい数の配列要素が加算されることを保証します。
for ループの先頭にある 3 つのステートメントは、通常、それぞれ 1 つの処理だけを実行しますが、いずれも空白のままにすることができます。最初または最後のステートメントが空白の場合、初期化や実行中の増分は行われません。比較ステートメントが空白の場合、常に true として扱われます。これにより、他の手段で中断されない限り、ループは無期限に実行されます。中断されるのは、return ステートメントまたは break ステートメントです。
複数のステートメントをコンマで区切って、最初の位置または 3 番目の位置に押し込むこともできます。これにより、複数の制御変数を持つループが可能になります。以下の例は、変数 hi と lo がそれぞれ 100 と 0 から始まり、収束するこのようなループの定義を示しています。
for ループには、さまざまな省略形が用意されています。次の式に注目してください。この式では、1 つのループに 2 つの for ループが含まれています。ここで、hi-- は hi = hi - 1 と同じで、lo++ は lo = lo + 1 と同じです。
for(hi = 100, lo = 0; hi >= lo; hi--, lo++)
forループは非常に柔軟性が高く、多くの種類のプログラム動作を簡単かつ迅速に指定できます。forループの例を見てみましょう。
#include <stdio.h>
int メイン()
{
整数インデックス;
for(インデックス = 0 ; インデックス < 6 ; インデックス = インデックス + 1)
printf("インデックスの値は%dです\n", index);
0を返します。
}
プログラムの結果は次のように表示されます。
インデックスの値は0です
インデックスの値は1です
インデックスの値は2です
インデックスの値は3です
インデックスの値は4です
インデックスの値は5です
goto ステートメント
C には、構造化されていないジャンプを許可する goto ステートメントがあります。goto ステートメントを使用するには、予約語 goto の後にジャンプ先のシンボル名を続けるだけです。名前はプログラム内の任意の場所に配置され、その後にコロンが続きます。関数内のほぼ任意の場所にジャンプできますが、ループ内にジャンプすることはできません。ただし、ループからジャンプすることはできます。
このプログラムは本当に混乱していますが、ソフトウェア作成者が goto ステートメントの使用をできるだけ排除しようとしている理由を示す良い例です。このプログラムで goto を使用するのが妥当な唯一の場所は、プログラムが 1 回のジャンプで 3 つのネストされたループからジャンプする場所です。この場合、変数を設定して 3 つのネストされたループのそれぞれから連続してジャンプするのはかなり面倒ですが、1 つの goto ステートメントで 3 つすべてから非常に簡潔に抜けることができます。
いかなる状況でも goto ステートメントは使用すべきではないと言う人もいますが、これは偏狭な考え方です。goto が他の構文よりも明らかにすっきりした制御フローを実現する場所がある場合は、モニター上のプログラムの残りの部分と同じように、goto を自由に使用してください。例を見てみましょう。
#include <stdio.h>
int メイン()
{
int 犬、猫、豚;
real_start に移動します。
どこか:
printf("これは混乱のもう一つの行です。\n");
stop_it に移動します。
/* 次のセクションは、使用可能な goto を持つ唯一のセクションです */
実際のスタート:
(犬 = 1 ; 犬 < 6 ; 犬 = 犬 + 1)
{
(cat = 1 ; cat < 6 ; cat = cat + 1) の場合
{
for(豚 = 1 ; 豚 < 4 ; 豚 = 豚 + 1)
{
printf("犬 = %d 猫 = %d 豚 = %d\n", 犬、猫、豚);
if ((dog + cat + pig) > 8 ) goto enough;
}
}
}
enough: printf("今のところ動物はこれで十分です。\n");
/* これは使用可能な goto ステートメントを含むセクションの終わりです */
printf("\nこれはコードの最初の行です。\n");
そこへ行く;
どこ:
printf("これはコードの3行目です。\n");
どこかへ行きます;
そこには:
printf("これはコードの 2 行目です。\n");
どこへ行く;
やめて:
printf("これがこの混乱の最後の行です。\n");
0を返します。
}
表示された結果を見てみましょう
犬 = 1 猫 = 1 豚 = 1
犬 = 1 猫 = 1 豚 = 2
犬 = 1 猫 = 1 豚 = 3
犬 = 1 猫 = 2 豚 = 1
犬 = 1 猫 = 2 豚 = 2
犬 = 1 猫 = 2 豚 = 3
犬 = 1 猫 = 3 豚 = 1
犬 = 1 猫 = 3 豚 = 2
犬 = 1 猫 = 3 豚 = 3
犬 = 1 猫 = 4 豚 = 1
犬 = 1 猫 = 4 豚 = 2
犬 = 1 猫 = 4 豚 = 3
犬 = 1 猫 = 5 豚 = 1
犬 = 1 猫 = 5 豚 = 2
犬 = 1 猫 = 5 豚 = 3
今のところ動物はこれで十分です。
これはコードの最初の行です。
これはコードの2行目です。
これはコードの3行目です。
これは混乱のもう一つのラインです。
これがこの混乱の最後の行です。
ポインタ
変数がメモリ内のどこに存在するかを知りたい場合があります。ポインターには、特定の値を持つ変数のアドレスが含まれます。ポインターを宣言するときは、ポインター名の直前にアスタリスクを配置します。
変数が格納されているメモリ位置のアドレスは、変数名の前にアンパサンドを置くことで見つけることができます。
int num; /* 通常の整数変数 */
int *numPtr; /* 整数変数へのポインタ */
次の例では、変数の値とその変数のメモリ内のアドレスを出力します。
printf("値%dはアドレス%Xに格納されています\n", num, &num);
変数 num のアドレスをポインター numPtr に割り当てるには、次の例のように変数 num のアドレスを割り当てます。
numPtr = #
numPtr が指すアドレスに何が格納されているかを調べるには、変数を逆参照する必要があります。逆参照は、ポインターが宣言されたアスタリスクを使用して実行されます。
printf("値%dはアドレス%Xに格納されています\n", *numPtr, numPtr);
プログラム内のすべての変数はメモリ内に存在します。以下のステートメントは、コンパイラが 32 ビット コンピュータ上で浮動小数点変数 x 用に 4 バイトのメモリを予約し、そこに値 6.5 を格納するように要求します。
浮動小数点数x;
x = 6.5;
変数のメモリ内のアドレス位置は、その名前の前に演算子 & を置くことで取得されるため、&x は x のアドレスです。C では、さらに 1 段階進んで、他の変数のアドレスを含むポインタと呼ばれる変数を定義できます。むしろ、ポインタは他の変数を指していると言えます。例:
浮動小数点数x;
浮動小数点* px;
x = 6.5;
px = &x;
px を float 型のオブジェクトへのポインターとして定義し、それを x のアドレスと等しく設定します。したがって、*px は x の値を参照します。
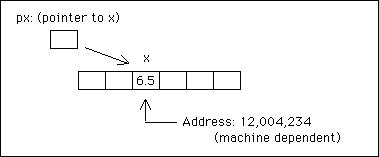
次の記述を検討してみましょう。
var_x の整数値。
int*ptrX;
ここで_x = 6;
ptrX = &var_x;
*ptrX = 12;
printf("xの値: %d", var_x);
最初の行は、コンパイラに整数用のメモリ領域を予約させます。 2 行目は、ポインターを格納するための領域を予約するようにコンパイラに指示します。
ポインタは、アドレスの保存場所です。3 行目は scanf ステートメントを思い出させます。アドレス "&" 演算子は、コンパイラに var_x を保存した場所に移動し、保存場所のアドレスを ptrX に渡すように指示します。
変数の前のアスタリスク * は、コンパイラにポインタを逆参照してメモリに移動するように指示します。その後、その場所に格納されている変数に代入を行うことができます。ポインタを介して変数を参照し、そのデータにアクセスできます。ポインタの例を見てみましょう。
/* ポインタの使用例 */
#include <stdio.h>
int メイン()
{
int インデックス、*pt1、*pt2;
index = 39; /* 任意の数値 */
pt1 = &index; /* インデックスのアドレス */
pt2 = pt1;
printf("値は%d %d %dです\n", index, *pt1, *pt2);
*pt1 = 13; /* これによりインデックスの値が変更されます */
printf("値は%d %d %dです\n", index, *pt1, *pt2);
0を返します。
}
プログラムの出力は次のように表示されます。
値は39 39 39です
値は13 13 13です
ポインターの使用をよりよく理解するために、別の例を見てみましょう。
#include <stdio.h>
#include <文字列.h>
int メイン()
{
char strg[40], *そこに、1つ、2つ;
int *pt、リスト[100]、インデックス;
strcpy(strg, "これは文字列です。");
/* strcpy() 関数は、ある文字列を別の文字列にコピーします。strcpy() 関数については、後で文字列セクションで説明します */
one = strg[0]; /* oneとtwoは同じです */
2 = *ctrl;
printf("最初の出力は%c %c\n", one, two);
one = strg[8]; /* oneとtwoは同じです */
2 = *(ctrl+8);
printf("2番目の出力は%c %c\n", one, two);
そこ = ctrl+10; /* strg+10は&strg[10]と同じです */
printf("3番目の出力は%c\n", strg[10]);
printf("4番目の出力は%c\nです", *there);
(インデックス = 0 ; インデックス < 100 ; インデックス++)
リスト[インデックス] = インデックス + 100;
pt = リスト + 27;
printf("5番目の出力は%dです\n", list[27]);
printf("6番目の出力は%dです\n", *pt);
0を返します。
}
プログラムの出力は次のようになります。
最初の出力はTTです。2
番目の出力はaaです。3
番目の出力はcです。4
番目の出力はcです。5
番目の出力は127です。6
番目の出力は127です。
配列
配列は同じ型の変数の集合です。個々の配列要素は整数インデックスによって識別されます。C ではインデックスは 0 から始まり、常に角括弧で囲まれて記述されます。
我々はすでにこのように宣言される1次元配列を見てきました。
int 結果[20];
配列はより多くの次元を持つことができ、その場合は次のように宣言される。
整数結果_2d[20][5];
整数結果_3d[20][5][3];
各インデックスには、独自の角括弧のセットがあります。配列はメイン関数で宣言され、通常は次元の詳細が含まれます。配列の代わりに、ポインターと呼ばれる別の型を使用することもできます。つまり、次元はすぐには固定されませんが、必要に応じてスペースを割り当てることができます。これは、特定の特殊なプログラムでのみ必要な高度なテクニックです。
例として、単一次元配列内のすべての整数を合計する簡単な関数を次に示します。
int add_array(int 配列[], int サイズ)
{
整数 i;
整数合計 = 0;
(i = 0; i < サイズ; i++) の場合
合計 += 配列[i];
戻り値(合計);
}
次に示すプログラムは、文字列を作成し、その中のいくつかのデータにアクセスして、それを出力します。ポインタを使用して再度アクセスし、文字列を出力します。異なる行に「Hi!」と「012345678」が出力されるはずです。プログラムのコーディングを見てみましょう。
#include <stdio.h>
#STR_LENGTH 10 を定義します
void main()
{
char Str[STR_LENGTH];
char* pStr;
整数 i;
Str[0] = 'H';
Str[1] = 'i';
Str[2] = '!';
Str[3] = '\0'; // 特殊な文字列終了文字 NULL
printf("Str の文字列は : %s\n", Str);
pStr = &Str[0];
(i = 0; i < STR_LENGTH; i++) の場合
{
*pStr = '0'+i;
pStr++;
}
Str[STR_LENGTH-1] = '\0';
printf("Str の文字列は : %s\n", Str);
}
[] (角括弧) は配列を宣言するために使用されます。プログラムの char Str[STR_LENGTH]; の行は、10 文字の配列を宣言します。これらは 10 個の個別の文字であり、すべてメモリ内の同じ場所にまとめられます。これらはすべて、変数名 Str と [n] (n は要素番号) を介してアクセスできます。
配列について話すときは、C が 10 個の配列を宣言する場合、アクセスできる要素には 0 から 9 の番号が付けられていることを常に念頭に置く必要があります。最初の要素にアクセスすることは、0 番目の要素にアクセスすることに相当します。したがって、配列の場合は、常に 0 から配列のサイズ - 1 までカウントします。
次に、配列に「Hi!」という文字を入れていますが、その後に「\0」を入れていることに注目してください。これは何なのか疑問に思われるかもしれません。「\0」は NULL を表し、文字列の終わりを表します。すべての文字列は、この特殊文字「\0」で終わる必要があります。そうでない場合、誰かが文字列に対して printf を呼び出すと、printf は文字列のメモリ位置から開始し、「\0」に遭遇すると出力を続行します。そのため、文字列の末尾に大量のゴミが残ります。したがって、文字列を適切に終了するようにしてください。
文字配列
文字列定数、例えば
「私はひもです」
文字の配列です。C では、文字列内の ASCII 文字、つまり「I」、「空白」、「a」、「m」、…または上記の文字列で内部的に表現され、プログラムが文字列の末尾を見つけられるように特殊なヌル文字「\0」で終了します。
文字列定数は、printf を使用してコードの出力をわかりやすくするためによく使用されます。
printf("こんにちは、世界\n");
printf("a の値は: %f\n", a);
文字列定数は変数に関連付けることができます。C では、一度に 1 文字 (1 バイト) を格納できる文字型変数が提供されています。文字列は、文字型の配列に格納され、1 つの場所に 1 つの ASCII 文字が格納されます。
文字列は慣例的にヌル文字「\0」で終了するため、配列内に追加の保存場所が 1 つ必要になることを忘れないでください。
C では、文字列全体を一度に操作する演算子は提供されていません。文字列は、ポインターまたは標準文字列ライブラリ string.h から利用できる特別なルーチンを介して操作されます。
配列の名前は最初の要素へのポインターにすぎないため、文字ポインターの使用は比較的簡単です。次のプログラムを検討してください。
#include<stdio.h>
void main()
{
文字text_1[100]、text_2[100]、text_3[100];
文字 *ta、*tb;
整数 i;
/* メッセージを配列として設定する */
/* 文字数; 初期化します */
/* 定数文字列 "..." に */
/* コンパイラに決定させる */
/* [] を使ってサイズを指定します */
char message[] = "こんにちは、私は文字列です。
あなた?";
printf("元のメッセージ: %s\n", message);
/* メッセージをtext_1にコピーします */
私=0;
( (text_1[i] = message[i]) != '\0' ) の間
私は++;
printf("Text_1: %s\n", text_1);
/* 明示的なポインタ演算を使用する */
あなたの=メッセージ;
テキスト
( ( *tb++ = *ta++ ) != '\0' ) の間
;
printf("Text_2: %s\n", text_2);
}
プログラムの出力は次のようになります。
元のメッセージ: こんにちは、私は文字列です。あなたは何ですか?
Text_1: こんにちは、私は文字列です。あなたは何ですか?
Text_2: こんにちは、私は文字列です。あなたは何ですか?
標準の「文字列」ライブラリには、文字列を操作するための便利な関数が多数含まれています。これについては、後ほど文字列セクションで説明します。
要素へのアクセス
配列内の個々の要素にアクセスするには、インデックス番号を角括弧で囲んだ変数名に続けます。その後、変数は C の他の変数と同じように扱うことができます。次の例では、配列の最初の要素に値を割り当てます。
0 = 16;
次の例では、配列の 3 番目の要素の値を出力します。
printf("%d\n", x[2]);
次の例では、scanf 関数を使用して、キーボードから値を読み取り、10 個の要素を持つ配列の最後の要素に格納します。
scanf("%d", &x[9]);
配列要素の初期化
配列は、他の変数と同様に代入によって初期化できます。配列には複数の値が含まれるため、個々の値は中括弧で囲まれ、コンマで区切られます。次の例では、3 の倍数表の最初の 10 個の値で 10 次元配列を初期化します。
int x[10] = {3, 6, 9, 12, 15, 18, 21, 24, 27, 30};
これにより、次の例のように値を個別に割り当てる必要がなくなります。
整数x[10];
0 = 3;
x[1] = 6;
x[2] = 9;
x[3] = 12;
x[4] = 15;
x[5] = 18;
x[6] = 21;
x[7] = 24;
x[8] = 27;
x[9] = 30;
配列をループする
配列は順番にインデックス付けされるため、 for ループを使用して配列のすべての値を表示できます。次の例では、配列のすべての値を表示します。
#include <stdio.h>
int メイン()
{
整数x[10];
整数カウンター;
/* 乱数ジェネレータをランダム化する */
srand((unsigned)time(NULL));
/* 変数にランダムな値を割り当てる */
(カウンター=0; カウンター<10; カウンター++)
x[カウンター] = rand();
/* 配列の内容を表示します */
(カウンター=0; カウンター<10; カウンター++)
printf("要素 %d の値は %d です\n", counter, x[counter]);
0を返します。
}
出力には毎回異なる値が印刷されますが、結果は次のように表示されます。
要素0の値は17132です
要素1の値は24904です
要素2の値は13466です
要素3の値は3147です。
要素4の値は22006です
要素5の値は10397です。
要素6の値は28114です。
要素7の値は19817です。
要素8の値は27430です
要素9の値は22136です。
多次元配列
配列は複数の次元を持つことができます。配列に複数の次元を持たせることで、柔軟性が高まります。たとえば、スプレッドシートは 2 次元配列、つまり行用の配列と列用の配列に基づいて構築されます。
次の例では、各行に 5 つの列が含まれる 2 次元配列を使用します。
#include <stdio.h>
int メイン()
{
/* 2 x 5 多次元配列を宣言します */
int x[2][5] = { {1, 2, 3, 4, 5},
{2、4、6、8、10} };
int 行、列;
/* 行を表示する */
(行=0; 行<2; 行++) の場合
{
/* 列を表示する */
(列=0; 列<5; 列++)の場合
printf("%d\t", x[行][列]);
'\n' を putchar('\n') に格納します。
}
0を返します。
}
このプログラムの出力は次のように表示されます。
1 2 3 4 5
2 4 6 8 10
文字列
文字列は、通常はアルファベットの文字のグループです。文字列は、印刷表示を、見栄えがよく、意味のある名前とタイトルを持ち、自分やプログラムの出力を使用する人々にとって美的に満足のいくようにフォーマットするためのものです。
実際、前のトピックの例ではすでに文字列を使用しています。しかし、これは文字列の完全な導入ではありません。プログラミングでは、フォーマットされた文字列を使用すると、プログラマーがプログラムの複雑さやバグを回避できるケースが数多くあります。
文字列の完全な定義は、ヌル文字 ('\0') で終了する一連の文字型データです。
C がデータの文字列を何らかの方法で使用する場合 (別の文字列と比較したり、出力したり、別の文字列にコピーしたりするなど)、関数は、null が検出されるまで、呼び出された操作を実行するように設定されます。
C には文字列の基本データ型はありません。代わりに、C の文字列は文字の配列として実装されます。たとえば、名前を格納するには、名前を格納するのに十分な大きさの文字配列を宣言し、適切なライブラリ関数を使用して名前を操作します。
次の例では、ユーザーが入力した文字列を画面に表示します。
#include <stdio.h>
int メイン()
{
char name[80]; /* 文字配列を作成する
呼ばれた名前 */
printf("名前を入力してください: ");
取得(名前);
printf("入力した名前は%sです\n", name);
0を返します。
}
プログラムの実行は次のようになります。
名前を入力してください: Tarun Tyagi
入力した名前はTarun Tyagiです
一般的な文字列関数
標準の string.h ライブラリには、文字列を操作するための便利な関数が多数含まれています。ここでは、最も便利な関数のいくつかの例を示します。
strlen関数
strlen 関数は文字列の長さを決定するために使用されます。例を使って strlen の使い方を学びましょう。
#include <stdio.h>
#include <文字列.h>
int メイン()
{
文字名[80];
長さ;
printf("名前を入力してください: ");
取得(名前);
長さ = strlen(名前);
printf("あなたの名前は%d文字です\n", length);
0を返します。
}
プログラムの実行は次のようになります。
名前を入力してください: Tarun Subhash Tyagi
あなたの名前は19文字です
名前を入力してください: Preeti Tarun
あなたの名前は12文字です
strcpy関数
strcpy 関数は、ある文字列を別の文字列にコピーするために使用されます。例を使ってこの関数の使い方を学びましょう。
#include <stdio.h>
#include <文字列.h>
int メイン()
{
char first[80];
文字秒[80];
printf("最初の文字列を入力してください: ");
取得(最初);
printf("2番目の文字列を入力してください: ");
取得(秒);
printf("最初: %s、2番目: %s strcpy() の前\n "
、1番目、2番目);
strcpy(2番目、1番目);
printf("最初: %s、2番目: %s strcpy() 後\n",
1番目、2番目);
0を返します。
}
プログラムの出力は次のようになります。
最初の文字列を入力してください: Tarun
2番目の文字列を入力してください: Tyagi
最初: Tarun、2番目: Tyagi strcpy() の前
最初: Tarun、2番目: Tarun strcpy() 後
strcmp 関数
strcmp 関数は、2 つの文字列を比較するために使用されます。配列の変数名は、その配列のベース アドレスを指します。したがって、次のように 2 つの文字列を比較しようとすると、2 つのアドレスを比較することになりますが、2 つの値を同じ場所に格納することはできないため、明らかに同じにはなりません。
if (first == second) /* 文字列を比較することはできません */
次の例では、strcmp 関数を使用して 2 つの文字列を比較します。
#include <文字列.h>
int メイン()
{
char 最初[80]、2番目[80];
整数t;
(t=1;t<=2;t++) の場合
{
printf("\n文字列を入力してください: ");
取得(最初);
printf("別の文字列を入力してください: ");
取得(秒);
(strcmp(first, second) == 0)の場合
puts("2つの文字列は等しい");
それ以外
puts("2つの文字列は等しくありません");
}
0を返します。
}
プログラムの実行は次のようになります。
文字列を入力してください: Tarun
別の文字列を入力してください: tarun
2つの文字列は等しくありません
文字列を入力してください: Tarun
別の文字列を入力してください: Tarun
2つの文字列は等しい
strcat 関数
strcat 関数は、1 つの文字列を別の文字列に結合するために使用されます。どのように行うか見てみましょう。例を使って説明します。
#include <文字列.h>
int メイン()
{
char 最初[80]、2番目[80];
printf("文字列を入力してください: ");
取得(最初);
printf("別の文字列を入力してください: ");
取得(秒);
strcat(最初、2番目);
printf("結合された 2 つの文字列: %s\n",
初め);
0を返します。
}
プログラムの実行は次のようになります。
文字列を入力: Data
別の文字列を入力: Recovery
2 つの文字列を結合: DataRecovery
strtok 関数
strtok 関数は、文字列内の次のトークンを検索するために使用されます。トークンは、可能な区切り文字のリストによって指定されます。
次の例では、ファイルからテキストの行を読み取り、区切り文字、スペース、タブ、および改行を使用して単語を決定します。各単語は、別々の行に表示されます。
#include <stdio.h>
#include <文字列.h>
int メイン()
{
ファイル *in;
char行[80];
char *delimiters = " \t\n";
char *トークン;
((in = fopen("C:\\text.txt", "r")) == NULLの場合)
{
puts("入力ファイルを開けません");
0を返します。
}
/* 一度に 1 行ずつ読み取ります */
while(!feof(in))
{
/* 1行取得 */
fgets(行, 80, in);
もし(!feof(in))
{
/* 行を単語に分割します */
トークン = strtok(行、区切り文字);
while (トークン != NULL)
{
puts(トークン);
/* 次の単語を取得します */
トークン = strtok(NULL, 区切り文字);
}
}
}
fclose(in);
0を返します。
}
上記のプログラムでは、 in = fopen("C:\\text.txt", "r") で、既存のファイル C:\\text.txt を開きます。指定されたパスにファイルが存在しない場合、または何らかの理由でファイルを開けなかった場合は、画面にエラー メッセージが表示されます。
これらの関数のいくつかを使用する次の例を考えてみましょう。
#include <stdio.h>
#include <文字列.h>
void main()
{
文字行[100]、*サブテキスト;
/* 文字列を初期化する */
strcpy(line,"hello, 私は文字列です;");
printf("行: %s\n", line);
/* 文字列の末尾に追加 */
strcat(行、「あなたは何ですか?」);
printf("行: %s\n", line);
/* 文字列の長さを調べる */
/* strlen は戻ります */
/* 長さは size_t 型として */
printf("行の長さ: %d\n", (int)strlen(line));
/* 部分文字列の出現を検索 */
if ( (sub_text = strchr ( line, 'W' ) )!= NULL )
printf("\"W\"で始まる文字列 ->%s\n",
サブテキスト);
if ( ( サブテキスト = strchr ( 行、 'w' ) )!= NULL )
printf("\"w\"で始まる文字列 ->%s\n",
サブテキスト);
if ( ( サブテキスト = strchr ( サブテキスト、 'u' ) )!= NULL )
printf("\"w\"で始まる文字列 ->%s\n",
サブテキスト);
}
プログラムの出力は次のように表示されます。
行: こんにちは、私は文字列です。
ライン: こんにちは、私は文字列です。あなたは何ですか?
行の長さ: 35
「w」で始まる文字列 -> あなたは何ですか?
「w」で始まる文字列 ->u?
機能
大規模なプログラムを開発および保守する最善の方法は、管理しやすい小さな部分からプログラムを構築することです (分割統治法と呼ばれることもあります)。関数を使用すると、プログラマーはプログラムをモジュール化できます。
関数を使用すると、複雑なプログラムを小さなブロックに分割することができ、各ブロックの記述、読み取り、保守が容易になります。すでに main 関数について説明し、標準ライブラリの printf を使用しました。もちろん、独自の関数やヘッダー ファイルを作成することもできます。関数のレイアウトは次のようになります。
戻り値の型 関数名 ( 必要であれば引数リスト )
{
ローカル宣言;
ステートメント;
戻り値を返す;
}
戻り値の型が省略された場合、C はデフォルトで int になります。戻り値は宣言された型である必要があります。関数内で宣言されたすべての変数は、定義されている関数内でのみ認識されるという点で、ローカル変数と呼ばれます。
一部の関数には、関数と関数を呼び出したモジュール間の通信方法を提供するパラメータ リストがあります。パラメータはローカル変数でもあり、関数の外部では使用できません。これまでに説明したプログラムにはすべて関数である main があります。
関数は値を返さずに単にタスクを実行することもあります。その場合のレイアウトは次のようになります。
void 関数名 ( 必要であれば引数リスト )
{
ローカル宣言;
声明;
}
C 関数呼び出しでは、引数は常に値で渡されます。つまり、引数の値のローカル コピーがルーチンに渡されます。関数内で引数に対して内部的に行われた変更は、引数のローカル コピーに対してのみ行われます。
引数リスト内の引数を変更または定義するには、この引数をアドレスとして渡す必要があります。関数がそれらの引数の値を変更しない場合は、通常の変数を使用します。関数がそれらの引数の値を変更する場合は、ポインタを使用する必要があります。
例を使って学んでみましょう:
#include <stdio.h>
void 交換 ( int *a, int *b )
{
整数 温度;
温度 = *a;
*a = *b;
*b = 温度;
printf(" 関数交換から: ");
printf("a = %d, b = %d\n", *a, *b);
}
void main()
{
整数a、b;
a = 5;
7;
printf("main から: a = %d、b = %d\n", a, b);
交換(&a, &b);
printf("メインに戻る: ");
printf("a = %d, b = %d\n", a, b);
}
このプログラムの出力は次のように表示されます。
メインから: a = 5、b = 7
関数の交換から: a = 7、b = 5
メインに戻る: a = 7、b = 5
別の例を見てみましょう。次の例では、1 から 10 までの数字の二乗を書き込む square という関数を使用しています。
#include <stdio.h>
int square(int x); /* 関数プロトタイプ */
int メイン()
{
整数カウンター;
(カウンタ=1; カウンタ<=10; カウンタ++)
printf("%d の 2 乗は %d です\n", counter, square(counter));
0を返します。
}
/* 関数 'square' を定義する */
整数平方(整数x)
{
x * x を返します。
}
このプログラムの出力は次のように表示されます。
1の2乗は1です
2の2乗は4です
3の2乗は9です
4の2乗は16です
5の2乗は25です
6の2乗は36です
7の2乗は49です
8の2乗は64です
9の2乗は81です
10の2乗は100です
関数プロトタイプ square は、整数パラメータを受け取り、整数を返す関数を宣言します。コンパイラがメイン プログラムで square への関数呼び出しに到達すると、関数呼び出しを関数の定義と照合することができます。
プログラムが関数 square を呼び出す行に到達すると、プログラムは関数にジャンプし、その関数を実行してからメイン プログラムへのパスを再開します。戻り値の型を持たないプログラムは、void を使用して宣言する必要があります。したがって、関数へのパラメーターは、値渡しまたは参照渡しになります。
再帰関数は、自分自身を呼び出す関数です。このプロセスは再帰と呼ばれます。
値渡し関数
前の例の square 関数のパラメータは値渡しされます。つまり、変数のコピーのみが関数に渡されます。値の変更は呼び出し元の関数に反映されません。
次の例では、値渡しを使用して渡されたパラメータの値を変更しますが、呼び出し元の関数には影響しません。関数 count_down は戻り値の型がないため、void として宣言されています。
#include <stdio.h>
void count_down(int x);
int メイン()
{
整数カウンター;
(カウンタ=1; カウンタ<=10; カウンタ++)
count_down(カウンター);
0を返します。
}
void count_down(int x)
{
整数カウンター;
(カウンター = x; カウンター > 0; カウンター--)
{
printf("%d ", x);
x--;
}
'\n' を putchar('\n') に格納します。
}
プログラムの出力は次のように表示されます。
1
2 1
3 2 1
4 3 2 1
5 4 3 2 1
6 5 4 3 2 1
7 6 5 4 3 2 1
8 7 6 5 4 3 2 1
9 8 7 6 5 4 3 2 1
10 9 8 7 6 5 4 3 2 1
より理解を深めるために、別の C 値渡しの例を見てみましょう。次の例では、ユーザーが入力した 1 ~ 30,000 の数字を単語に変換します。
#include <stdio.h>
void do_units(int num);
void do_tens(int num);
void do_teens(int num);
int メイン()
{
int 数値、残り;
する
{
printf("1から30,000までの数字を入力してください: ");
scanf("%d", &num);
} num < 1 || num > 30000 の間;
残り = 数;
printf("%d 語 = ", num);
do_tens(残差/1000);
(数値 >= 1000)の場合
printf("千");
残留%= 1000;
do_units(残余/100);
(残差 >= 100)の場合
{
printf("百 ");
}
(数値 > 100 && 数値%100 > 0) の場合
printf("および ");
残留%=100;
do_tens(残差);
'\n' を putchar('\n') に格納します。
0を返します。
}
void do_units(int num)
{
スイッチ(数値)
{
ケース1:
printf("1");
壊す;
ケース2:
printf("2");
壊す;
ケース3:
printf("3 ");
壊す;
ケース4:
printf("4");
壊す;
ケース5:
printf("5 ");
壊す;
ケース6:
printf("6");
壊す;
ケース7:
printf("7");
壊す;
ケース8:
printf("8");
壊す;
ケース9:
printf("9");
}
}
void do_tens(int num)
{
スイッチ(数値/10)
{
ケース1:
do_teens(数値);
壊す;
ケース2:
printf("20 ");
壊す;
ケース3:
printf("30 ");
壊す;
ケース4:
printf("40 ");
壊す;
ケース5:
printf("50 ");
壊す;
ケース6:
printf("60 ");
壊す;
ケース7:
printf("70 ");
壊す;
ケース8:
printf("80 ");
壊す;
ケース9:
printf("90 ");
}
(数値/10 != 1) の場合
do_units(数値%10);
}
void do_teens(int num)
{
スイッチ(数値)
{
ケース10:
printf("10 ");
壊す;
ケース11:
printf("11 ");
壊す;
ケース12:
printf("12 ");
壊す;
ケース13:
printf("13 ");
壊す;
ケース14:
printf("14 ");
壊す;
ケース15:
printf("15 ");
壊す;
ケース16:
printf("16 ");
壊す;
ケース17:
printf("17 ");
壊す;
ケース18:
printf("18 ");
壊す;
ケース19:
printf("19 ");
}
}
プログラムの出力は次のようになります。
1から30,000までの数字を入力してください: 12345
12345を単語で表すと12,345になります
参照呼び出し
関数を参照渡しするには、変数自体を渡す代わりに、変数のアドレスを渡します。変数のアドレスは & 演算子を使用して取得できます。次の例では、実際の値ではなく変数のアドレスを渡して swap 関数を呼び出します。
スワップ(&x, &y);
逆参照
ここで問題となるのは、関数 swap に変数ではなくアドレスが渡されているため、変数を逆参照して、変数のアドレスではなく実際の値を確認してスワップする必要があることです。
C では、ポインタ (*) 表記を使用して逆参照が行われます。簡単に言うと、これは各変数を使用する前にその前に * を配置して、変数のアドレスではなく値を参照することを意味します。次のプログラムは、2 つの値を交換する参照渡しを示しています。
#include <stdio.h>
void swap(int *x, int *y);
int メイン()
{
整数x=6、y=10;
printf("関数スワップ前は、x = %d、y =
%d\n\n", x, y);
スワップ(&x, &y);
printf("関数スワップ後、x = %d、y =
%d\n\n", x, y);
0を返します。
}
void swap(int *x, int *y)
{
整数 temp = *x;
*x = *y;
*y = 温度;
}
プログラムの出力を見てみましょう:
関数スワップ前は、x = 6、y = 10
関数の交換後、x = 10、y = 6
関数は再帰的になる可能性があり、つまり関数が自分自身を呼び出す可能性があります。自分自身を呼び出すたびに、関数の現在の状態がスタックにプッシュされる必要があります。スタック オーバーフロー (つまり、スタックにそれ以上データを配置するスペースがなくなる) は簡単に発生するため、この事実を覚えておくことが重要です。
次の例では、再帰を使用して数値の階乗を計算します。階乗とは、1 まで、その数値より小さいすべての整数を乗算した数値です。たとえば、数値 6 の階乗は次のようになります。
6 の階乗 = 6 * 5 * 4 * 3 * 2 * 1
したがって、6 の階乗は 720 です。上記の例から、階乗 6 = 6 * 階乗 5 であることがわかります。同様に、階乗 5 = 5 * 階乗 4 などとなります。
以下は階乗を計算するための一般的な規則です。
階乗(n) = n * 階乗(n-1)
上記の規則は、1 の階乗が 1 であるため、n = 1 のときに終了します。例を使用して、これをよりよく理解してみましょう。
#include <stdio.h>
long int 階乗(int num);
int メイン()
{
整数 数値;
長い整数f;
printf("数字を入力してください: ");
scanf("%d", &num);
f = 階乗(数値);
printf("%d の階乗は %ld です\n", num, f);
0を返します。
}
長い int 階乗(int 数値)
{
(数値 == 1)の場合
1 を返します。
それ以外
num * 階乗(num-1)を返します。
}
このプログラムの実行出力を見てみましょう。
数字を入力してください: 7の7の
階乗は5040です
C でのメモリ割り当て
C コンパイラには、malloc.h で定義されたメモリ割り当てライブラリがあります。メモリは malloc 関数を使用して予約され、アドレスへのポインタを返します。この関数は、必要なメモリのサイズ (バイト単位) を 1 つのパラメータとして受け取ります。
次の例では、文字列「hello world」にスペースを割り当てます。
ptr = (char *)malloc(strlen("Hello world") + 1);
文字列終了文字 '\0' を考慮するには、追加の 1 バイトが必要です。 (char *) はキャストと呼ばれ、戻り値の型を char * に強制します。
データ型にはさまざまなサイズがあり、malloc はスペースをバイト単位で返すため、移植性の観点から、割り当てるサイズを指定するときに sizeof 演算子を使用することをお勧めします。
次の例では、文字列を文字配列バッファに読み込み、必要なメモリ量を正確に割り当てて、それを「ptr」という変数にコピーします。
#include <文字列.h>
#include <malloc.h>
int メイン()
{
char *ptr、バッファ[80];
printf("文字列を入力してください: ");
バッファを取得します。
ptr = (char *)malloc((strlen(バッファ) + 1) *
sizeof(文字));
strcpy(ptr, バッファ);
printf("入力しました: %s\n", ptr);
0を返します。
}
プログラムの出力は次のようになります。
文字列を入力してください:インドは最高です
入力した文字列:インドは最高です
メモリの再割り当て
プログラミング中に、メモリの再割り当てが必要になることは何度もあります。これは、realloc 関数を使用して行います。realloc 関数は、サイズを変更するメモリのベース アドレスと、確保するスペースの量という 2 つのパラメータを取り、ベース アドレスへのポインタを返します。
msg というポインター用にスペースを予約していて、そのポインターがすでに占有しているスペースの量と別の文字列の長さを加えてスペースを再割り当てしたい場合は、次のように使用できます。
msg = (char *)realloc(msg, (strlen(msg) + strlen(buffer) + 1)*sizeof(char));
次のプログラムは、malloc、realloc、free の使用方法を示しています。ユーザーは、結合された一連の文字列を入力します。空の文字列が入力されると、プログラムは文字列の読み取りを停止します。
#include <文字列.h>
#include <malloc.h>
int メイン()
{
charバッファ[80]、*msg;
整数 firstTime=0;
する
{
printf("\n文を入力してください: ");
バッファを取得します。
if (!firstTime)
{
メッセージ = (char *)malloc((strlen(バッファ) + 1) *
sizeof(文字));
strcpy(メッセージ、バッファ);
初回 = 1;
}
それ以外
{
メッセージ = (char *)realloc(メッセージ, (strlen(メッセージ) +
strlen(バッファ) + 1) * sizeof(文字));
strcat(メッセージ、バッファ);
}
メッセージを格納します。
} while(strcmp(バッファ、""));
無料(メッセージ);
0を返します。
}
プログラムの出力は次のようになります。
文章を入力してください:昔々
昔々
文章を入力してください:王様がいました
昔々昔々王様がいました
文章を入力してください:王様は
昔々昔々王様がいました王様は
文を入力してください:
昔々、王様がいました王様は
記憶を解放する
割り当てられたメモリの使用が終了したら、必ずメモリを解放してください。メモリを解放するとリソースが解放され、速度が向上します。割り当てられたメモリを解放するには、free 関数を使用します。
解放(ptr);
構造
C には、基本的なデータ型の他に、相互に関連するデータ項目を共通の名前でグループ化できる構造メカニズムがあります。これは一般に、ユーザー定義型と呼ばれます。
キーワード struct は構造体の定義を開始し、タグは構造体に一意の名前を付けます。構造体に追加されたデータ型と変数名は構造体のメンバーです。結果は、型指定子として使用できる構造体テンプレートです。次は、タグが month である構造体です。
構造体月
{
文字名[10];
char 略語[4];
int 日数;
};
構造体型は通常、typedef ステートメントを使用してファイルの先頭近くで定義されます。typedef は新しい型を定義して名前を付け、プログラム全体で使用できるようにします。typedef は通常、ファイル内の #define および #include ステートメントの直後に発生します。
typedef キーワードは、構造体の名前で struct キーワードを指定する代わりに、構造体を参照する単語を定義するために使用できます。typedef の名前は大文字で付けるのが一般的です。次に構造体定義の例を示します。
typedef構造体{
文字名[64];
チャーコース[128]
年齢;
整数年;
} 学生; これは新しい型 student を定義します。型 student の変数は次のように宣言できます。
学生 st_rec;
これはintやfloatの宣言と非常に似ていることに注意してください。変数名はst_recで、name、course、age、yearというメンバーがあります。同様に、
typedef 構造体要素
{
文字データ;
構造体要素 *next;
} スタック要素;
ユーザー定義型構造体要素の変数は、次のように宣言できるようになりました。
スタック要素 *スタック;
次の構造を考えてみましょう。
構造体学生
{
char *名前;
int グレード;
};
struct student へのポインターは次のように定義できます。
構造体学生*hnc;
構造体へのポインタにアクセスする場合、ドット演算子の代わりにメンバーポインタ演算子 -> が使用されます。構造体にグレードを追加するには、
s.グレード = 50;
次のようにして構造にグレードを割り当てることができます。
s->グレード = 50;
基本データ型と同様に、関数内で渡されたパラメータに加えられた変更を永続的に保持したい場合は、参照渡し (アドレスを渡す) する必要があります。メカニズムは基本データ型とまったく同じです。アドレスを渡し、ポインタ表記を使用して変数を参照します。
構造体を定義したら、そのインスタンスを宣言し、ドット表記を使用してメンバーに値を割り当てることができます。次の例は、月構造体の使用法を示しています。
#include <stdio.h>
#include <文字列.h>
構造体月
{
文字名[10];
char略語[4];
int 日数;
};
int メイン()
{
構造体月m;
strcpy(m.name, "1月");
strcpy(m.abbreviation, "Jan");
m.days = 31;
printf("%s は %s と省略され、%d 日あります\n", m.name, m.abbreviation, m.days);
0を返します。
}
プログラムの出力は次のようになります。
1月はJanと略され、31日間あります。
すべての ANSI C コンパイラでは、メンバー単位のコピーを実行して、ある構造体を別の構造体に割り当てることができます。m1 と m2 という月構造体がある場合、次のようにして m1 から m2 に値を割り当てることができます。
- ポインター メンバーを持つ構造体。
- 構造体を初期化します。
- 構造体を関数に渡す。
- ポインタと構造体。
C におけるポインタ メンバーを持つ構造体
固定サイズの配列に文字列を保持するのは、メモリの非効率的な使用です。より効率的な方法は、ポインタを使用することです。ポインタは、通常のポインタ定義で使用されるのとまったく同じ方法で構造体で使用されます。例を見てみましょう。
#include <文字列.h>
#include <malloc.h>
構造体月
{
char *名前;
char *略語;
int 日数;
};
int メイン()
{
構造体月m;
m.name = (char *)malloc((strlen("1月")+1) *
sizeof(文字));
strcpy(m.name, "1月");
m.abbreviation = (char *)malloc((strlen("Jan")+1) *
sizeof(文字));
strcpy(m.abbreviation, "Jan");
m.days = 31;
printf("%s は %s と省略され、%d 日あります\n",
m.name、m.abbreviation、m.days);
0を返します。
}
プログラムの出力は次のようになります。
1月はJanと略され、31日間あります。
C の構造体初期化子
構造体の初期値のセットを提供するには、宣言ステートメントに初期化子を追加できます。C では月は 1 から始まりますが、配列は 0 から始まります。次の例では、位置 0 にある junk と呼ばれる追加要素が使用されています。
#include <stdio.h>
#include <文字列.h>
構造体月
{
char *名前;
char *略語;
int 日数;
} 月の詳細[] =
{
「ジャンク」、「ジャンク」、0、
「1月」、「1月」、31、
「2月」、「2月」、28日、
「3月」、「3月」、31、
「4月」、「4月」、30、
「5月」、「5月」、31、
「6月」、「6月」、30、
「7月」、「7月」、31、
「8月」、「8月」、31日、
「9月」、「9月」、30、
「10月」、「10月」、31日、
「11月」、「11月」、30日、
「12月」、「12月」、31
};
int メイン()
{
整数カウンター;
(カウンタ=1; カウンタ<=12; カウンタ++)
printf("%s は %s と省略され、%d 日あります\n",
month_details[カウンター].name、
month_details[カウンター].略語、
month_details[カウンター].days);
0を返します。
}
出力は次のように表示されます。
1月はJanと略され、31日間あります。
2月はFebと略され、28日間あります。
3月はMarと略され、31日間あります。
4月はAprと略され、30日間あります
5月はMayと略され、31日間あります
6月はJunと略され、30日間あります
7月はJulと略され、31日間あります。
8月はAugと略され、31日間あります。
9月はSepと略され、30日間あります
10月はOctと略され、31日間あります。
11月はNovと略され、30日間あります
12月はDecと略され、31日間あります。
C で構造体を関数に渡す
構造体は、他の基本データ型と同様に、関数にパラメータとして渡すことができます。次の例では、date という構造体を isLeapYear 関数に渡して、その年がうるう年かどうかを判断します。
通常は日付の値のみを渡しますが、構造体を関数に渡す方法を示すために構造体全体が渡されます。
#include <stdio.h>
#include <文字列.h>
構造体月
{
char *名前;
char *略語;
int 日数;
} 月の詳細[] =
{
「ジャンク」、「ジャンク」、0、
「1月」、「1月」、31、
「2月」、「2月」、28日、
「3月」、「3月」、31、
「4月」、「4月」、30、
「5月」、「5月」、31、
「6月」、「6月」、30、
「7月」、「7月」、31、
「8月」、「8月」、31日、
「9月」、「9月」、30、
「10月」、「10月」、31日、
「11月」、「11月」、30日、
「12月」、「12月」、31
};
構造体の日付
{
int 日;
整数 月;
整数年;
};
int isLeapYear(構造体 date d);
int メイン()
{
構造体日付d;
printf("日付を入力してください (例: 1980/11/11): ");
scanf("%d/%d/%d", &d.day, &d.month, &d.year);
printf("日付 %d %s %d は ", d.day,
month_details[d.month].name, d.year);
(isLeapYear(d) == 0)の場合
printf("not ");
puts("うるう年");
0を返します。
}
int 閏年(構造体日付d)
{
((d.year % 4 == 0 && d.year % 100 != 0) の場合 ||
d.年%400 == 0)
1 を返します。
0を返します。
}
プログラムの実行は次のようになります。
日付を入力してください(例:1980/11/11):1980/9/12
1980年12月9日は閏年です
次の例では、学生の名前と成績を格納するための構造体の配列を動的に割り当てます。成績は昇順でユーザーに表示されます。
#include <文字列.h>
#include <malloc.h>
構造体学生
{
char *名前;
int グレード;
};
void swap(構造体学生 *x、構造体学生 *y);
int メイン()
{
構造体学生*グループ;
charバッファ[80];
int 偽;
int 内側、外側;
int カウンター、numStudents;
printf("グループには何人の生徒がいますか: ");
scanf("%d", &numStudents);
グループ = (構造体学生 *)malloc(numStudents *
sizeof(構造体学生));
(counter=0; counter<numStudents; counter++) の場合
{
偽 = getchar();
printf("生徒の名前を入力してください: ");
バッファを取得します。
グループ[カウンター].name = (char *)malloc((strlen(バッファ)+1) * sizeof(char));
strcpy(グループ[カウンター].name, バッファ);
printf("成績を入力してください: ");
scanf("%d", &group[counter].grade);
}
(外側=0; 外側<numStudents; 外側++)
(内側=0; 内側<外側; 内側++)
if (group[outer].grade <
グループ[内部].グレード)
swap(&group[外側], &group[内側]);
puts("成績の昇順のグループ...");
(counter=0; counter<numStudents; counter++) の場合
printf("%s はグレード %d を達成しました \n",
グループ[カウンター].名前、
グループ[カウンター].grade);
0を返します。
}
void swap(構造体学生 *x、構造体学生 *y)
{
構造体学生テンポ;
temp.name = (char *)malloc((strlen(x->name)+1) *
sizeof(文字));
strcpy(temp.name, x->name);
temp.grade = x->grade;
x->グレード = y->グレード;
x->name = (char *)malloc((strlen(y->name)+1) *
sizeof(文字));
strcpy(x->名前, y->名前);
y->grade = temp.grade;
y->name = (char *)malloc((strlen(temp.name)+1) *
sizeof(文字));
strcpy(y->name, temp.name);
}
出力の実行は次のようになります。
グループには何人の生徒がいますか: 4
生徒の名前を入力してください: Anuraaj
学年を入力してください: 7
生徒の名前を入力してください: Honey
学年を入力してください: 2
生徒の名前を入力してください: Meetushi
学年を入力してください: 1
生徒の名前を入力してください: Deepti
学年を入力してください: 4
成績順に並べたグループです。
ミーツシはグレード1を達成
ハニーはグレード2を達成
ディープティはグレード4を達成
アヌラージはグレード7 を達成
連合
ユニオンを使用すると、同じデータを異なる型で表示したり、同じデータを異なる名前で使用したりすることができます。ユニオンは構造体に似ています。ユニオンは構造体と同じ方法で宣言および使用されます。
共用体は、一度に 1 つのメンバーしか使用できないという点で構造体と異なります。その理由は簡単です。共用体のすべてのメンバーは、同じメモリ領域を占有します。メンバーは互いに重なり合って配置されます。
共用体は、構造体と同じ方法で定義および宣言されます。宣言の唯一の違いは、キーワード union が struct の代わりに使用されることです。char 変数と整数変数の単純な共用体を定義するには、次のように記述します。
ユニオン共有{
文字 c;
整数 i;
};
この共用体は共有されており、文字値 c または整数値 i のいずれかを保持できる共用体のインスタンスを作成するために使用できます。これは OR 条件です。両方の値を保持する構造体とは異なり、共用体は一度に 1 つの値しか保持できません。
共用体は宣言時に初期化できます。一度に使用できるメンバーは 1 つだけであり、初期化できるメンバーは 1 つだけであるためです。混乱を避けるため、共用体の最初のメンバーのみを初期化できます。次のコードは、共有共用体のインスタンスを宣言して初期化する例を示しています。
共用体共有汎用変数 = {`@'};
generic_variable ユニオンは、構造体の最初のメンバーが初期化されるのと同じように初期化されていることに注意してください。
個々の共用体メンバーは、メンバー演算子 (.) を使用して構造体メンバーを使用するのと同じ方法で使用できます。ただし、共用体メンバーへのアクセスには重要な違いがあります。
一度にアクセス可能なユニオン メンバーは 1 つだけです。ユニオンはメンバーを互いに重ねて格納するため、一度にアクセス可能なメンバーは 1 つだけであることが重要です。
ユニオンキーワード
ユニオンタグ {
組合員(複数可);
/* 追加のステートメントがここに記述される場合があります */
}実例;
union キーワードは、共用体の宣言に使用されます。共用体とは、1 つの名前でグループ化された 1 つ以上の変数 (union_members) の集合です。さらに、これらの共用体メンバーはそれぞれ同じメモリ領域を占有します。
キーワード union は、共用体定義の開始を識別します。その後に、共用体に付けられた名前であるタグが続きます。タグの後には、中括弧で囲まれた共用体メンバーが続きます。
インスタンス、つまり共用体の実際の宣言も定義できます。インスタンスなしで構造体を定義すると、それはプログラム内で構造体を宣言するために後で使用できる単なるテンプレートになります。以下はテンプレートの形式です。
ユニオンタグ {
組合員(複数可);
/* 追加のステートメントがここに記述される場合があります */
};
テンプレートを使用するには、次の形式を使用します: union tag instance;
この形式を使用するには、指定されたタグを使用して事前にユニオンを宣言しておく必要があります。
/* tag という共用体テンプレートを宣言します */
ユニオンタグ {
整数 数値;
チャーアルプス;
}
/* ユニオンテンプレートを使用する */
ユニオンタグ mixed_variable;
/* ユニオンとインスタンスを一緒に宣言する */
ユニオンジェネリック型タグ {
文字 c;
整数 i;
フロートf;
ダブルd;
} ジェネリック;
/* 共用体を初期化します。 */
ユニオン日付タグ {
char フル日付[9];
構造体part_date_tag{
char月[2];
char break_value1;
チャーの日[2]
char break_value2;
char年[2];
} パート日付;
}日付 = {"09/12/80"};
例を参考にして、よりよく理解してみましょう。
#include <stdio.h>
int メイン()
{
連合
{
int value; /* これは共用体の最初の部分です */
構造体
{
char first; /* これら 2 つの値は 2 番目の部分です */
char 秒;
} 半分;
} 番号;
長いインデックス。
(インデックス = 12 ; インデックス < 300000L ; インデックス += 35231L)
{
数値.値 = インデックス;
printf("%8x %6x %6x\n", 数値.値,
数字.半分.最初、
数値.半秒);
}
0を返します。
}
プログラムの出力は次のように表示されます。
cc 0
89ab ファブ ff89
134a 4a 13
9ce9 ffe9 ff9c
2688 FF88 26
b027 27 ffb0
39c6 ffc6 39
c365 65 ffc3
4d04 4 4d
データ復旧におけるユニオンの実用的使用
ここで、データ回復プログラミングにおける union の実際の使用法を見てみましょう。小さな例を見てみましょう。次のプログラムは、フロッピー ディスク ドライブ (a: ) の不良セクター スキャン プログラムの小さなモデルですが、不良セクター スキャン ソフトウェアの完全なモデルではありません。
プログラムを調べてみましょう:
#include<dos.h>
#include<conio.h>
int メイン()
{
int rp、ヘッド、トラック、セクター、ステータス;
char *バッファ;
ユニオン REGS in、out;
構造体SREGs;
clrscr();
/* ディスクシステムをリセットしてディスクを初期化します */
printf("\n ディスクシステムをリセットしています....");
(rp=0;rp<=2;rp++) の場合
{
in.h.ah = 0;
in.h.dl = 0x00;
int86(0x13,&in,&out);
}
printf("\n\n\n ディスクの不良セクタをテストしています....");
/* 不良セクタをスキャンする */
(トラック=0;トラック<=79;トラック++)
{
(ヘッド=0;ヘッド<=1;ヘッド++)
{
for(セクター=1;セクター<=18;セクター++)
{
in.h.ah = 0x04;
内径 = 1;
in.h.dl = 0x00;
in.h.ch = トラック;
in.h.dh = ヘッド;
in.h.cl = セクター;
in.x.bx = FP_OFF(buf);
s.es = FP_SEG(buf);
int86x(0x13,&in,&out,&s);
if(out.x.cflag)
{
ステータス=out.h.ah;
printf("\n トラック:%d ヘッド:%d セクター:%d ステータス ==0x%X",track,head,sector,status);
}
}
}
}
printf("\n\n\n完了");
0を返します。
}
では、フロッピー ディスクに不良セクタがある場合の出力がどのようになるかを見てみましょう。
ディスク システムをリセットしています....
ディスクの不良セクタをテストしています...
トラック:0 ヘッド:0 セクター:4 ステータス ==0xA
トラック:0 ヘッド:0 セクター:5 ステータス ==0xA
トラック:1 ヘッド:0 セクター:4 ステータス ==0xA
トラック:1 ヘッド:0 セクター:5 ステータス ==0xA
トラック:1 ヘッド:0 セクター:6 ステータス ==0xA
トラック:1 ヘッド:0 セクター:7 ステータス ==0xA
トラック:1 ヘッド:0 セクター:8 ステータス ==0xA
トラック:1 ヘッド:0 セクター:11 ステータス ==0xA
トラック:1 ヘッド:0 セクター:12 ステータス ==0xA
トラック:1 ヘッド:0 セクター:13 ステータス ==0xA
トラック:1 ヘッド:0 セクター:14 ステータス ==0xA
トラック:1 ヘッド:0 セクター:15 ステータス ==0xA
トラック:1 ヘッド:0 セクター:16 ステータス ==0xA
トラック:1 ヘッド:0 セクター:17 ステータス ==0xA
トラック:1 ヘッド:0 セクター:18 ステータス ==0xA
トラック:1 ヘッド:1 セクター:5 ステータス ==0xA
トラック:1 ヘッド:1 セクター:6 ステータス ==0xA
トラック:1 ヘッド:1 セクター:7 ステータス ==0xA
トラック:1 ヘッド:1 セクター:8 ステータス ==0xA
トラック:1 ヘッド:1 セクター:9 ステータス ==0xA
トラック:1 ヘッド:1 セクター:10 ステータス ==0xA
トラック:1 ヘッド:1 セクター:11 ステータス ==0xA
トラック:1 ヘッド:1 セクター:12 ステータス ==0xA
トラック:1 ヘッド:1 セクター:13 ステータス ==0xA
トラック:1 ヘッド:1 セクター:14 ステータス ==0xA
トラック:1 ヘッド:1 セクター:15 ステータス ==0xA
トラック:1 ヘッド:1 セクター:16 ステータス ==0xA
トラック:1 ヘッド:1 セクター:17 ステータス ==0xA
トラック:1 ヘッド:1 セクター:18 ステータス ==0xA
トラック:2 ヘッド:0 セクター:4 ステータス ==0xA
トラック:2 ヘッド:0 セクター:5 ステータス ==0xA
トラック:14 ヘッド:0 セクター:6 ステータス ==0xA
終わり
このプログラムでディスクの不良セクタを検証したり、ディスク システムをリセットしたりするために使用される関数と割り込みを理解するのは少し難しいかもしれませんが、心配する必要はありません。これらのことはすべて、次の章の後半の BIOS と割り込みプログラミングのセクションで学習します。
C でのファイル処理
C言語でのファイルアクセスは、ストリームをファイルに関連付けることによって実現されます。C言語は、ファイルポインタと呼ばれる新しいデータ型を使用してファイルと通信します。この型はstdio.h内で定義され、FILE *として記述されます。output_fileと呼ばれるファイルポインタは、次のようなステートメントで宣言されます。
ファイル *出力ファイル;
fopen関数のファイルモード
プログラムがファイルにアクセスするには、まずファイルを開く必要があります。これは、必要なファイル ポインタを返す fopen 関数を使用して行われます。何らかの理由でファイルを開くことができない場合は、NULL 値が返されます。通常、fopen は次のように使用します。
((出力ファイル = fopen("出力ファイル", "w")) == NULL)の場合
fprintf(stderr, "%s を開けません\n",
"出力ファイル");
fopen は 2 つの引数を取ります。どちらも文字列で、最初の引数は開くファイルの名前、2 番目の引数はアクセス文字 (通常は r、a、w など) です。次の表に示すように、ファイルはさまざまなモードで開くことができます。
| ファイルモード |
| r |
テキストファイルを読み取り用に開きます。 |
| で |
書き込み用のテキスト ファイルを作成します。ファイルが存在する場合は上書きされます。 |
| 1つの |
テキスト ファイルを追加モードで開きます。テキストはファイルの末尾に追加されます。 |
| rb |
バイナリファイルを読み取り用に開きます。 |
| ウェブページ |
書き込み用のバイナリ ファイルを作成します。ファイルが存在する場合は上書きされます。 |
| アブ |
バイナリ ファイルを追加モードで開きます。データはファイルの末尾に追加されます。 |
| r+ |
テキスト ファイルを読み書き用に開きます。 |
| イン+ |
読み書き用のテキスト ファイルを作成します。ファイルが存在する場合は上書きされます。 |
| プラス |
最後にテキストファイルを読み書き用に開きます。 |
| r+b または rb+ |
バイナリ ファイルを読み書き用に開きます。 |
| w+b または wb+ |
読み取りおよび書き込み用のバイナリ ファイルを作成します。ファイルが存在する場合は上書きされます。 |
| a+b または ab+ |
最後にテキストファイルを読み書き用に開きます。 |
更新モードは、fseek、fsetpos、rewind 関数で使用されます。fopen 関数はファイル ポインターを返します。エラーが発生した場合は NULL を返します。
次の例では、ファイル tarun.txt を読み取り専用モードで開きます。ファイルが存在するかどうかをテストすることは、プログラミングの良い習慣です。
((in = fopen("tarun.txt", "r")) == NULLの場合)
{
puts("ファイルを開けません");
0を返します。
}
ファイルを閉じる
ファイルは fclose 関数を使用して閉じられます。構文は次のとおりです。
fclose(in);
ファイルの読み取り
feof 関数は、ファイルの終わりをテストするために使用されます。関数 fgetc、fscanf、および fgets は、ファイルからデータを読み取るために使用されます。
次の例では、fgetc を使用してファイルを 1 文字ずつ読み取り、ファイルの内容を画面に一覧表示します。
#include <stdio.h>
int メイン()
{
ファイル *in;
int キー;
((in = fopen("tarun.txt", "r")) == NULLの場合)
{
puts("ファイルを開けません");
0を返します。
}
ながら (!feof(in))
{
キー = fgetc(in);
/* 最後に読み取られた文字はファイル終了マーカーなので印刷しないでください */
もし(!feof(in))
putchar(キー);
}
fclose(in);
0を返します。
}
ファイル内のデータが fscanf で使用される書式文字列の形式である場合、次の例のように fscanf 関数を使用してファイルからさまざまなデータ型を読み取ることができます。
fscanf(in, "%d/%d/%d", &day, &month, &year);
fgets 関数は、ファイルから一定数の文字を読み取るために使用されます。stdin は標準入力ファイル ストリームであり、fgets 関数を使用して入力を制御できます。
ファイルへの書き込み
fputc と fprintf を使用して、データをファイルに書き込むことができます。次の例では、fgetc 関数と fputc 関数を使用してテキスト ファイルのコピーを作成します。
#include <stdio.h>
int メイン()
{
ファイル *in、*out;
int キー;
((in = fopen("tarun.txt", "r")) == NULLの場合)
{
puts("ファイルを開けません");
0を返します。
}
out = fopen("copy.txt", "w");
ながら (!feof(in))
{
キー = fgetc(in);
もし(!feof(in))
fputc(キー、出力);
}
fclose(in);
fclose(アウト);
0を返します。
}
fprintf 関数を使用すると、フォーマットされたデータをファイルに書き込むことができます。
fprintf(out, "日付: %02d/%02d/%02d\n",
日、月、年);
C のコマンドライン引数
main() 関数を宣言するための ANSI C 定義は次のいずれかです。
int main() または int main(int argc, char **argv)
2 番目のバージョンでは、コマンドラインから引数を渡すことができます。パラメータ argc は引数カウンターであり、コマンドラインから渡されたパラメータの数が含まれます。パラメータ argv は引数ベクトルであり、渡された実際のパラメータを表す文字列へのポインタの配列です。
次の例では、コマンドラインから任意の数の引数を渡し、それを出力します。argv[0] は実際のプログラムです。プログラムはコマンドプロンプトから実行する必要があります。
#include <stdio.h>
int main(int argc, char **argv)
{
整数カウンター;
puts("プログラムへの引数は次のとおりです:");
(counter=0; counter<argc; counter++) の場合
puts(argv[カウンター]);
0を返します。
}
プログラム名が count.c の場合、コマンドラインから次のように呼び出すことができます。
3を数える
または
7を数える
または
192 などを数えます。
次の例では、ファイル処理ルーチンを使用してテキスト ファイルを新しいファイルにコピーします。たとえば、コマンド ライン引数は次のように呼び出すことができます。
txtcpy 1.txt 2.txt
#include <stdio.h>
int main(int argc, char **argv)
{
ファイル *in、*out;
int キー;
(引数<3)の場合
{
puts("使用法: txtcpy ソース 宛先\n");
puts("ソースは既存のファイルである必要があります");
puts("宛先ファイルが存在する場合は、
上書きされました");
0を返します。
}
((in = fopen(argv[1], "r")) == NULLの場合)
{
puts("コピーするファイルを開けません");
0を返します。
}
((out = fopen(argv[2], "w")) == NULLの場合)
{
puts("出力ファイルを開けません");
0を返します。
}
ながら (!feof(in))
{
キー = fgetc(in);
もし(!feof(in))
fputc(キー、出力);
}
fclose(in);
fclose(アウト);
0を返します。
}
ビット操作子
ハードウェア レベルでは、データは 2 進数として表されます。数値 59 の 2 進数表現は 111011 です。ビット 0 は最下位ビットで、この場合はビット 5 が最上位ビットです。
各ビット セットは、2 のビット セット乗として計算されます。ビット演算子を使用すると、ビット レベルで整数変数を操作できます。次の図は、数値 59 の 2 進表現を示しています。
| 59の2進数表現 |
| ビット 5 4 3 2 1 0 |
| 2乗n32168421 |
| セット 1 1 1 0 1 1 |
3 ビットで 0 から 7 までの数字を表すことができます。次の表は、0 から 7 までの数字を 2 進数で示したものです。
| 2進数 |
| 000 |
0 |
| 001 |
1 |
| 010 |
2 |
| 011 |
3 |
| 100 |
4 |
| 101 |
5 |
| 110 |
6 |
| 111 |
7 |
次の表は、2 進数を操作するために使用できるビット演算子を示しています。
| 2進数 |
| & |
ビットAND |
| | |
ビットOR |
| ^ |
ビットごとの排他的論理和 |
| 〜 |
ビット補数 |
| << |
ビット単位の左シフト |
| >> |
ビット右シフト |
ビットAND
ビット AND は、両方のビットが設定されている場合にのみ True になります。次の例は、数値 23 と 12 のビット AND の結果を示しています。
| 10111 (23)
01100 (12) および
____________________
00100 (結果 = 4) |
マスク値を使用して、特定のビットが設定されているかどうかを確認できます。ビット 1 と 3 が設定されているかどうかを確認する場合は、数値を 10 (ビット 1 と 3 の値) でマスクし、結果をマスクに対してテストできます。
#include <stdio.h>
int メイン()
{
int 数値、マスク = 10;
printf("数字を入力してください: ");
scanf("%d", &num);
if ((num & mask) == mask)
puts("ビット 1 と 3 が設定されています");
それ以外
puts("ビット 1 と 3 は設定されていません");
0を返します。
}
ビットOR
いずれかのビットが設定されている場合、ビットごとの OR は真になります。以下は、数値 23 と 12 のビットごとの OR の結果を示しています。
| 10111 (23)
01100 (12) または
______________________
11111 (結果 = 31) |
マスクを使用して、1 つまたは複数のビットが設定されているかどうかを確認できます。次の例では、ビット 2 が設定されていることを確認します。
#include <stdio.h>
int メイン()
{
int num、マスク = 4;
printf("数字を入力してください: ");
scanf("%d", &num);
num |= マスク;
printf("ビット 2 が設定されていることを確認した後: %d\n", num);
0を返します。
}
ビットごとの排他的論理和
ビットごとの排他的論理和は、どちらかのビットが設定されている場合のみ True になりますが、両方のビットが設定されている場合は True になります。以下は、数値 23 と 12 のビットごとの排他的論理和の結果を示しています。
| 10111 (23)
01100 (12) 排他的論理和 (XOR)
_____________________________
11011 (結果 = 27) |
排他的論理和には興味深い特性があります。数値自体を排他的論理和すると、ゼロはゼロのままになり、1 は両方設定できないためゼロに設定されるので、数値自体がゼロに設定されます。
この結果、ある数値と別の数値を排他的論理和し、その結果と別の数値を再度排他的論理和すると、結果は元の数値になります。上記の例で使用した数値でこれを試すことができます。
23 または 12 = 27
27 または 12 = 23
27 または 23 = 12
この機能は暗号化に使用できます。次のプログラムは、暗号化キー 23 を使用して、ユーザーが入力した数値の特性を示しています。
#include <stdio.h>
int メイン()
{
int 数値、キー = 23;
printf("数字を入力してください: ");
scanf("%d", &num);
num ^= キー;
printf("%d との排他的論理和は %d になります\n", key, num);
num ^= キー;
printf("%d との排他的論理和は %d になります\n", key, num);
0を返します。
}
ビット補数
ビット補数は、ビットのオン/オフを切り替える 1 の補数演算子です。1 の場合は 0 に設定され、0 の場合は 1 に設定されます。
#include <stdio.h>
int メイン()
{
整数 = 0xFFFF;
printf("%X の補数は %X です\n", num, ~num);
0を返します。
}
ビット単位の左シフト
ビット単位の左シフト演算子は、数値を左にシフトします。数値が左に移動すると最上位ビットは失われ、空いた最下位ビットはゼロになります。以下は、43 の 2 進表現を示しています。
0101011 (10進数43)
ビットを左にシフトすると、最上位ビット (この場合はゼロ) が失われ、最下位ビットにゼロが埋め込まれます。結果の数値は次のとおりです。
1010110 (10進数では86)
ビット右シフト
ビット右シフト演算子は、数値を右にシフトします。空になった最上位ビットにゼロが導入され、空になった最下位ビットは失われます。以下は、数値 43 の 2 進表現を示しています。
0101011 (10進数43)
ビットを右にシフトすると、最下位ビット (この場合は 1) が失われ、最上位ビットに 0 が埋め込まれます。結果の数値は次のとおりです。
0010101 (10進数21)
次のプログラムは、ビット単位の右シフトとビット単位の AND を使用して、数値を 16 ビットの 2 進数として表示します。数値は 16 から 0 まで右に連続的にシフトされ、1 とのビット単位の AND 演算が行われ、ビットが設定されているかどうかが確認されます。別の方法としては、ビット単位の OR 演算子で連続したマスクを使用する方法があります。
#include <stdio.h>
int メイン()
{
int カウンター、数値;
printf("数字を入力してください: ");
scanf("%d", &num);
printf("%d はバイナリです: ", num);
(カウンター=15; カウンター>=0; カウンター--)
printf("%d", (num >> counter) & 1);
'\n' を putchar('\n') に格納します。
0を返します。
}
2進数から10進数への変換関数
次に示す 2 つの関数は、2 進数から 10 進数への変換と、10 進数から 2 進数への変換です。次に示す 10 進数を対応する 2 進数に変換する関数は、最大 32 ビットの 2 進数をサポートします。必要に応じて、この関数または前に示したプログラムを変換に使用できます。
10進数から2進数への変換関数:
void 小数点から二進数へ(void)
{
整数入力 =0;
整数 i;
整数カウント = 0;
int binary [32]; /* 32ビット、最大32要素 */
printf ("変換する10進数を入力してください
バイナリ:");
scanf ("%d", &input);
する
{
i = input%2; /* MOD 2 で 1 または 0 を取得します*/
binary[count] = i; /* バイナリ配列に要素をロードする */
input = input/2; /* 入力を2で割って2進数で減算する */
count++; /* 必要な要素の数を数える*/
}while (入力 > 0);
/* 2進数を反転して出力します */
printf ("バイナリ表現は: ");
する
{
printf ("%d", バイナリ[count - 1]);
カウント - ;
} while (count > 0);
printf("\n");
}
2進数から10進数への変換関数:
次の関数は、任意の 2 進数を対応する 10 進数に変換します。
void バイナリから小数点への変換(void)
{
charバイナリホールド[512];
char *バイナリ;
整数 i=0;
整数10進数 = 0;
整数z;
printf ("2進数を入力してください。\n");
printf ("2進数は0か1のみです ");
printf ("バイナリエントリ: ");
バイナリ = 取得(バイナリホールド)。
i=strlen(バイナリ);
(z=0; z<i; ++z) の場合
{
dec=dec*2+(binary[z]=='1'? 1:0); /* Binary[z]が
1に等しい、
1 なら 1、そうでなければ 0 */
}
printf("\n");
printf ("%s の 10 進数値は %d です",
2進数、10進数);
printf("\n");
}
デバッグとテスト
構文エラー
構文とは、文法、構造、およびステートメント内の要素の順序を指します。ステートメントをセミコロンで終了し忘れるなど、ルールに違反すると構文エラーが発生します。プログラムをコンパイルすると、コンパイラは遭遇する可能性のある構文エラーのリストを生成します。
優れたコンパイラは、エラーの説明を含むリストを出力し、可能な解決策を提供する場合があります。エラーを修正すると、再コンパイル時にさらにエラーが表示される場合があります。これは、以前のエラーによってプログラムの構造が変更され、元のコンパイル中にさらにエラーが抑制されたためです。
同様に、1 つの間違いが複数のエラーを引き起こす可能性があります。コンパイルされて正常に実行されるプログラムのメイン関数の最後にセミコロンを付けてみてください。再コンパイルすると、膨大なエラー リストが表示されますが、実際にはセミコロンの位置が間違っているだけです。
構文エラーだけでなく、コンパイラは警告も発行する場合があります。警告はエラーではありませんが、プログラムの実行中に問題を引き起こす可能性があります。たとえば、倍精度浮動小数点数を単精度浮動小数点数に割り当てると、精度が失われる可能性があります。これは構文エラーではありませんが、問題を引き起こす可能性があります。この特定の例では、変数を適切なデータ型にキャストすることで意図を示すことができます。
x が単精度浮動小数点数で、 y が倍精度浮動小数点数である次の例を考えてみましょう。 y は割り当て中に明示的に float にキャストされるため、コンパイラの警告は表示されなくなります。
x = (浮動小数点)y;
論理エラー
ロジック エラーは、ロジックにエラーがある場合に発生します。たとえば、数値が 4 未満で 8 より大きいかどうかをテストするとします。これは決して真になりませんが、構文が正しければプログラムは正常にコンパイルされます。次の例を考えてみましょう。
(x < 4 && x > 8)の場合
puts("決して起こりません!");
構文は正しいのでプログラムはコンパイルされますが、 x の値が同時に 4 未満かつ 8 より大きい値になることはあり得ないため、 puts ステートメントは印刷されません。
ほとんどの論理エラーは、プログラムの初期テストで発見されます。プログラムが期待どおりに動作しない場合は、論理ステートメントを詳しく検査して修正します。これは、明らかな論理エラーの場合のみに当てはまります。プログラムが大きくなるほど、プログラムを通過するパスの数が増え、プログラムが期待どおりに動作することを確認するのが難しくなります。
テスト
ソフトウェア開発プロセスでは、開発のどの段階でもエラーが挿入される可能性があります。これは、ソフトウェア開発の初期段階の検証方法が手動であるためです。したがって、コーディング アクティビティ中に開発されたコードには、コーディング アクティビティ中に導入されたエラーに加えて、要件エラーや設計エラーが含まれる可能性があります。テスト中は、テスト対象のプログラムが一連のテスト ケースを使用して実行され、テスト ケースのプログラムの出力が評価されて、プログラミングが期待どおりに実行されているかどうかが判断されます。
したがって、テストとは、ソフトウェア項目を分析して、既存の条件と必要な条件 (つまり、バグ) の違いを検出し、ソフトウェア項目の機能を評価するプロセスです。つまり、テストとは、エラーを見つけることを目的としてプログラムを分析するプロセスです。
いくつかのテスト原則
- テストでは欠陥が存在しないことは示せません。欠陥が存在することだけが示せます。
- エラーが早く発生するほど、コストは高くなります。
- エラーの検出が遅くなるほど、コストが高くなります。
ここで、いくつかのテスト手法について説明します。
ホワイトボックステスト
ホワイト ボックス テストは、プログラムのすべてのパスをすべての可能な値でテストする手法です。このアプローチでは、プログラムがどのように動作するかについての知識が必要です。たとえば、プログラムが 1 から 50 までの整数値を受け入れる場合、ホワイト ボックス テストでは、50 個の値すべてを使用してプログラムをテストし、それぞれの値に対して正しいことを確認してから、整数が取る可能性のある他のすべての値をテストし、期待どおりに動作するかどうかをテストします。一般的なプログラムに含まれるデータ項目の数を考えると、大規模なプログラムでは、可能な組み合わせによってホワイト ボックス テストが非常に難しくなります。
ホワイト ボックス テストは、大規模プログラムの安全性が重要な機能に適用され、残りの大部分は、以下で説明するブラック ボックス テストを使用してテストされます。組み合わせの数が多いため、ホワイト ボックス テストは通常、テスト ハーネスを使用して実行されます。テスト ハーネスでは、値の範囲が特別なプログラムを通じてプログラムに迅速に入力され、予想される動作に対する例外がログに記録されます。ホワイト ボックス テストは、構造的テスト、クリア ボックス テスト、またはオープン ボックス テストと呼ばれることもあります。
ブラックボックステスト
ブラック ボックス テストはホワイト ボックス テストに似ていますが、すべての可能な値をテストするのではなく、選択された値をテストします。このタイプのテストでは、テスターは入力と予想される結果が何であるかを知っていますが、プログラムがどのようにしてそれらの結果に到達したかは必ずしも知りません。ブラック ボックス テストは機能テストと呼ばれることもあります。
ブラックボックステストのテストケースは、通常、プログラム仕様が完成した直後に開発されます。テスト ケースは同値クラスに基づいています。
同値類
各入力に対して、同値クラスは有効な状態と無効な状態を定義します。通常、同値クラスを定義するときに計画するシナリオは 3 つあります。
入力データに範囲または特定の値が指定されている場合は、有効な状態が 1 つと無効な状態が 2 つ定義されます。たとえば、数値が 1 から 20 までの範囲でなければならない場合、有効な状態は 1 から 20 までとなり、1 未満の値の場合は無効な状態、20 より大きい値の場合は無効な状態となります。
入力データに範囲または特定の値が含まれていない場合、2 つの有効な状態と 1 つの無効な状態が定義されます。たとえば、数値が 1 から 20 までの範囲にあってはならない場合、有効な状態は 1 未満かつ 20 より大きい値になり、無効な状態は 1 から 20 までの範囲になります。
入力にブール値を指定する場合、有効な状態と無効な状態の 2 つの状態のみになります。
境界値分析
境界値分析では、入力データの境界にある値のみを考慮します。たとえば、1 から 20 までの数字の場合、テスト ケースは 1、20、0、21 になるかもしれません。これらの値でプログラムが期待どおりに動作すれば、他の値でも期待どおりに動作する、という考え方です。
次の表は、定義する必要がある一般的な境界の概要を示しています。
| テスト範囲 |
| 入力タイプ |
テスト値 |
| 範囲 |
- x[下限]-1
- x[下限]
- x[上限]
- x[上限]+1
|
| ブール |
|
テスト計画の作成
同等クラスを定義し、各クラスの境界を決定します。クラスの境界を定義したら、境界での許容値と許容されない値、および期待される動作のリストを記述します。その後、テスターは境界値を使用してプログラムを実行し、境界値を必要な結果に対してテストしたときに何が起こったかを示すことができます。
以下は、許容値の範囲が 10 ~ 110 である入力年齢を検証するために使用される一般的なテスト プランです。
| 同値クラス |
| 有効 |
正しくない |
| 10~110の間 |
> 110 |
|
< 10 |
同等クラスを決定したら、年齢のテスト計画を作成できます。
| テスト計画 |
| 価値 |
州 |
期待される結果 |
実際の結果 |
| 10 |
有効 |
名前を取得するために実行を続けます |
|
| 110 |
有効 |
名前を取得するために実行を続けます |
|
| 9 |
正しくない |
年齢をもう一度聞く |
|
| 111 |
正しくない |
年齢をもう一度聞く |
|
「実際の結果」列はテスト中に入力されるため空白のままになります。結果が予想どおりであれば、列がチェックされます。そうでない場合は、何が起こったかを示すコメントを入力する必要があります。