장 - 4
숫자 체계
소개
데이터 복구 프로그래밍이나 기타 디스크 문제 해결 프로그래밍에서는 단일 작업이나 작업의 아주 작은 부분(예: CHS(실린더, 헤드, 섹터)를 기준으로 확장된 MBR의 특정 위치를 계산하는 것)을 수행하기 위해 동시에 여러 유형의 숫자 체계를 사용해야 하는 경우가 매우 흔합니다. 이러한 위치는 프로그래머가 전체 작업을 수행하는 데 있어 지침이 됩니다.
아마도 대부분의 새로운 프로그래머는 2진법과 16진법 숫자 체계를 사용해야 하는 어셈블리 언어로 시스템 프로그래밍을 배우려고 할 때, 서로 다른 숫자 체계를 서로 변환하는 데 문제나 혼란에 직면할 것입니다.
이번 장에서는 이진수, 10진수, 16진수 체계를 포함한 여러 중요한 개념과 비트, 니블, 바이트, 워드, 더블 워드 등의 변환과 같은 이진 데이터 구성 및 기타 여러 관련 숫자 체계 주제를 논의합니다.
대부분의 현대 컴퓨터 시스템은 10진법을 사용하여 숫자 값을 나타내지 않고, 일반적으로 2진법이나 2의 보수 방식을 사용합니다.
프로그래밍에 일반적으로 사용되는 숫자 체계는 2진수, 8진수, 10진수, 16진수의 4가지입니다 . 하지만 우리가 가장 자주 접하는 수 체계는 2진법, 10진법, 16진법입니다. 이러한 숫자 체계는 기본 숫자에 따라 달라집니다.
각 숫자 체계에는 고유한 기본 숫자와 표현 기호가 있습니다. 다음 표에는 이 네 가지 숫자가 나와 있습니다.
| 숫자 체계의 이름 |
기본 번호 |
나타내는 데 사용되는 기호 |
| 이진법 |
2 |
비 |
| 8진법 |
8 |
Q 또는 O |
| 소수 |
10 |
D 또는 아니오 |
| 16진법 |
16 |
시간 |
10진수 체계
10진수 체계는 10진법을 사용하고 0에서 9까지의 숫자를 포함합니다. 혼동하지 마세요. 이것은 우리가 일상 생활에서 계산을 위해 사용하는 일반적인 숫자 체계입니다. 각 위치의 전력 가중치 값은 다음과 같습니다.

따라서 10진수 218이 있고 이를 위와 같은 방식으로 표현하고자 한다면, 218은 다음과 같이 표현됩니다.
2 * 102 + 1 * 101 + 8 * 100
= 2 * 100 + 1 * 10 + 8 * 1
= 200 + 10 + 8
= 218
이제 분수 소수의 예를 살펴보겠습니다. 예를 들어 821,128이라는 숫자가 있다고 가정해 보겠습니다. 소수점 왼쪽의 각 숫자는 0에서 9까지의 값을 나타내며, 10의 거듭제곱은 숫자의 위치(0부터 시작)로 표현됩니다.
소수점 오른쪽에 나타나는 숫자는 0에서 9까지의 값을 10의 음수 거듭제곱으로 곱한 값을 나타냅니다. 살펴보겠습니다.
8*102+2*101+1*100+1*10-1+2*10-2+8*10-3
= 8 * 100 + 2 * 10 + 1 * 1 + 1 * 0,1 + 2 * 0,01 + 8 * 0,001
= 800 + 20 + 1 + 0,1 + 0,02 + 0,008
= 821,128
이진수 체계
오늘날 대부분의 현대 컴퓨터 시스템은 이진 논리를 사용하여 작동합니다. 컴퓨터는 0과 1을 사용하여 OFF 또는 ON을 나타내는 두 가지 전압 레벨을 사용하여 값을 표현합니다 . 예를 들어, 0V의 전압은 일반적으로 논리 0으로 표현되고 +3.3V 또는 +5V의 전압은 논리 1로 표현됩니다. 따라서 두 가지 레벨을 사용하면 정확히 두 가지 다른 값을 표현할 수 있습니다. 이는 서로 다른 두 값일 수 있지만 관례에 따라 0과 1의 값을 사용합니다.
컴퓨터가 사용하는 논리 레벨과 이진수 체계에서 사용하는 두 숫자는 대응 관계가 있으므로 컴퓨터가 이진수를 사용한다는 것은 놀라운 일이 아닙니다.
이진수 체계는 십진수 체계와 동일하게 작동합니다. 다만 이진수 체계는 2를 기수로 사용하고 0과 1만 사용하고 다른 숫자를 사용하면 해당 숫자는 유효하지 않은 이진수가 됩니다.
각 항목의 가중치는 다음과 같이 표시됩니다.

다음 표는 이진수와 10진수의 표현을 비교해서 보여줍니다.
| 10진수 |
숫자의 이진 표현 |
| 0 |
0000 |
| 1 |
0001 |
| 2 |
0010 |
| 3 |
0011 |
| 4 |
0100 |
| 5 |
0101 |
| 6 |
0110 |
| 7 |
0111 |
| 8 |
1000 |
| 9 |
1001 |
| 10 |
1010 |
| 11 |
1011 |
| 12 |
1100 |
| 13 |
1101 |
| 14 |
1110 |
| 15 |
1111 |
일반적으로 10진수의 경우, 3개의 10진수 자릿수는 쉼표로 구분되어 큰 숫자를 읽기 쉽게 합니다. 예를 들어, 840349823보다 840,349,823이라는 숫자를 읽는 것이 훨씬 쉽습니다.
같은 아이디어에서 영감을 얻어 이진수에도 비슷한 규칙이 있어 이진수를 읽기 쉽게 할 수 있지만 이진수의 경우 소수점 왼쪽의 최하위 자릿수부터 시작하여 네 자리마다 공백을 추가합니다.
예를 들어 , 이진값이 1010011001101011이면 1010 0110 0110 1011로 작성됩니다.
2진수에서 10진수로 변환
이진수를 십진수로 변환하려면 각 자릿수를 가중치가 있는 위치로 곱하고 가중치가 있는 각 값을 더합니다. 예를 들어, 이진수 값 1011 0101은 다음을 나타냅니다.
1*27 + 0*26 + 1*25 + 1*24 + 0*23 + 1*22 + 0*21 + 1*20 = 1 * 128 + 0 * 64 + 1 * 32 + 1 * 16 + 0 * 8 + 1 * 4 + 0 * 2 + 1 * 1 = 128 + 0 + 32 + 16 + 0 + 4 + 0 + 1 = 181
10진수에서 2진수로 변환
10진수를 2진수로 변환하려면 일반적으로 10진수를 2로 나눈 후, 나머지가 0이면 옆에 0을 적습니다. 나머지가 1이면 1을 적습니다.
이 과정은 몫을 2로 나누고 이전 나머지를 버려 몫이 0이 될 때까지 계속됩니다. 나누기를 수행할 때 10진수의 2진수 등가를 나타내는 나머지는 가장 낮은 유효 자릿수(오른쪽)에서 시작하여 쓰고 각각의 새로운 자릿수는 이전 자릿수의 더 높은 유효 자릿수(왼쪽)에 씁니다.
예를 들어 보겠습니다 . 숫자 2671을 생각해 보세요. 숫자 2671의 이진 변환은 다음 표에 나와 있습니다.
| 분할 |
몫 |
나머지 |
이진수 |
| 2671 / 2 |
1335 |
1 |
1 |
| 1335 / 2 |
667 |
1 |
11 |
| 667 / 2 |
333 |
1 |
111 |
| 333 / 2 |
166 |
1 |
1111 |
| 166 / 2 |
83 |
0 |
0 1111 |
| 83 / 2 |
41 |
1 |
10 1111 |
| 41 / 2 |
20 |
1 |
110 1111 |
| 20 / 2 |
10 |
0 |
0110 1111 |
| 10 / 2 |
5 |
0 |
0 0110 1111 |
| 5 / 2 |
2 |
1 |
10 0110 1111 |
| 2 / 2 |
1 |
0 |
010 0110 1111 |
| 1 / 2 |
0 |
1 |
1010 0110 1111 |
이 표는 변환의 각 단계를 명확히 하기 위한 것이지만 실제로는 변환을 쉽고 빠르게 하려면 다음 방식에 따라 결과를 얻을 수 있습니다.
1980을 2진수로 변환할 10진수로 지정하세요. 그런 다음 표에 나와 있는 방법에 따라 다음과 같은 방식으로 이 문제를 해결합니다.
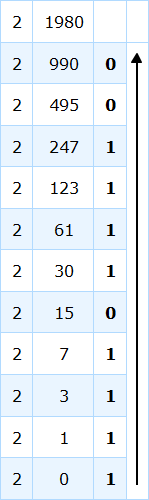
나머지를 화살표 방향에 따라 배열하면 10진수 1980에 해당하는 2진수 = 0111 1011 1100이 됩니다.
이진수 형식
일반적으로 우리는 이진수를 비트 시퀀스로 씁니다. "비트"는 기계에서 "이진 숫자"의 줄임말입니다. 이러한 비트에 대한 정의된 형식 경계가 있습니다. 이러한 형식 경계는 다음 표에 표시되어 있습니다.
| 이름 |
크기 (비트) |
예 |
| 조금 |
1 |
1 |
| 조금씩 깨물다 |
4 |
0101 |
| 바이트 |
8 |
0000 0101 |
| 단어 |
16 |
0000 0000 0000 0101 |
| 더블워드 |
32 |
0000 0000 0000 0000 0000 0000 0000 0101 |
우리는 값을 변경하지 않고도 원하는 만큼 많은 선행 0을 추가할 수 있지만, 일반적으로 선행 0을 추가하여 이진수를 원하는 크기 경계로 조정합니다.
예를 들어, 표에 표시된 것처럼 숫자 7을 다른 경우로 표현할 수 있습니다.
| | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 조금 | | | | | | | | | | | | | | 1 | 1 | 1 |
| 조금씩 깨물다 | | | | | | | | | | | | | 0 | 1 | 1 | 1 |
| 바이트 | | | | | | | | | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
| 단어 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
이진수의 가장 오른쪽 비트는 비트 위치 0이고, 왼쪽의 각 비트에는 위 표에 나와 있는 것처럼 바로 다음 비트 번호가 지정됩니다.
비트 0은 보통 최하위 비트 또는 LSB라고 하며 가장 왼쪽 비트는 보통 최상위 비트 또는 MSB라고 합니다. 이러한 표현 형식에 대해 알려주세요.
더 비트
비트는 이진 컴퓨터에서 가장 작은 데이터 단위입니다. 단일 비트는 0 또는 1 중 하나의 값만 나타낼 수 있습니다. 부울(참/거짓) 값을 나타내기 위해 비트를 사용하는 경우 해당 비트는 참 또는 거짓을 나타냅니다 .
더 니블
니블은 특히 숫자 체계, BCD(2진수 10진수) 또는 16진수(기수 16)에 대해 이야기할 때 관심 있는 분야에 포함됩니다.
니블은 4비트 경계에 있는 비트 모음입니다. 단일 BCD 또는 16진수 숫자를 나타내려면 4비트가 필요합니다. 니블을 사용하면 최대 16개의 고유한 값을 나타낼 수 있습니다.
16진수의 경우 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F의 값은 4비트로 표현됩니다. BCD는 10개의 다른 숫자(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)를 사용하고 4비트가 필요합니다.
사실, 16개의 고유한 값은 니블로 표현할 수 있지만 16진수와 BCD 숫자는 단일 니블로 표현할 수 있는 주요 항목입니다. 니블의 비트 수준 표현은 다음과 같습니다.
바이트
바이트는 80x86 마이크로프로세서에서 사용하는 가장 중요한 데이터 구조입니다. 바이트는 8비트로 구성되며 마이크로프로세서에서 가장 작은 주소 지정 가능 데이터 항목입니다. 컴퓨터의 주 메모리와 I/O 주소는 모두 바이트 주소이므로 80x86 마이크로프로세서 프로그램에서 개별적으로 액세스할 수 있는 가장 작은 항목은 8비트 값입니다.
더 작은 것에 접근하려면 데이터가 들어 있는 바이트를 읽고 원치 않는 비트를 마스크해야 합니다. 다음 장에서 이를 위한 프로그래밍을 할 것입니다.
바이트의 가장 중요한 용도는 문자 코드를 보관하는 것입니다. 바이트의 비트는 다음과 같이 비트 0(b0)에서 7(b7)까지 번호가 매겨집니다.

비트 0(b0)은 바이트의 하위 비트 또는 최하위 비트이고 비트 7(b7)은 바이트의 상위 비트 또는 최상위 비트입니다.
여기서 우리는 바이트가 정확히 두 개의 니블을 포함하는 것을 볼 수 있는데, 비트 b0~b3는 하위 니블을 구성하고 비트 b4~b7은 상위 니블을 형성합니다.
바이트는 정확히 두 개의 니블을 포함하므로 바이트 값에는 두 개의 16진수 숫자가 필요합니다.
기존의 현대 컴퓨터는 바이트 주소 지정이 가능한 머신이므로 개별 비트나 니블보다 전체 바이트를 조작하는 것이 더 효율적입니다.
이것이 대부분의 프로그래머가 256개 항목 이상을 필요로 하지 않는 데이터 유형을 나타내기 위해 전체 바이트를 사용하는 이유입니다.
바이트는 8비트로 구성되어 있으므로 28개 또는 256개의 다른 값을 나타낼 수 있습니다. 최대 8비트 이진수는 1111 1111로 256(10진수)과 같기 때문입니다. 따라서 일반적으로 바이트는 다음을 나타내는 데 사용됩니다.
- 0~255 범위의 부호 없는 숫자 값
- -128~+127 범위의 부호 있는 숫자
- ASCII 문자 코드
- 그리고 256개 이하의 서로 다른 값이 필요한 특수 데이터 유형도 있습니다. 많은 데이터 유형이 256개 미만의 항목을 갖기 때문에 일반적으로 8비트로 충분합니다.
말씀
워드는 16비트의 그룹입니다 . 하지만 전통적으로 워드의 경계는 16비트 또는 프로세서의 데이터 버스 크기로 정의되고 더블 워드는 두 워드입니다. 따라서 워드와 더블 워드는 고정된 크기가 아니라 프로세서에 따라 시스템마다 다릅니다. 하지만 개념적으로 읽기 위해 워드를 두 바이트로 정의하겠습니다.
비트 수준에서 단어를 볼 때, 그것은 비트 0(b0)에서 15(b15)까지 시작하는 단어의 비트로 번호가 매겨집니다. 비트 수준 표현은 다음과 같습니다.

여기서 비트 0은 LSB(최하위 비트)이고 비트 15는 MSB(최상위 비트)입니다. 단어의 다른 비트를 참조해야 할 경우 해당 비트의 비트 위치 번호를 사용하여 참조합니다.
이런 방식으로 단어는 정확히 두 바이트를 포함하며, 비트 b0에서 비트 b7은 하위 바이트를 형성하고 비트 b8에서 b15는 상위 바이트를 형성합니다. 16비트 단어로 216(65536)개의 다른 값을 표현할 수 있습니다. 이러한 값은 다음과 같을 수 있습니다.
- 0~65,535 범위의 부호 없는 숫자 값입니다.
- -32,768 ~ +32,767 범위의 부호 있는 숫자 값
- 65,536개 이하의 값을 가진 모든 데이터 유형. 이런 식으로 단어는 주로 다음과 같은 용도로 사용됩니다.
- 16비트 정수 데이터 값
- 16비트 메모리 주소
- 16비트 이하를 필요로 하는 모든 숫자 시스템
더블 워드
더블 워드는 정확히 그 이름대로 두 개의 워드입니다. 따라서 더블 워드 양은 32비트입니다 . 더블 워드는 상위 워드와 하위 워드, 4바이트 또는 8니블 등으로 나눌 수도 있습니다.
이런 식으로 더블 워드는 모든 종류의 다른 데이터를 나타낼 수 있습니다. 다음과 같을 수 있습니다.
- 0~4,294,967,295 범위의 부호 없는 더블워드
- -2,147,483,648 ~ 2,147,483,647 범위의 부호 있는 이중 단어
- 32비트 부동 소수점 값
- 또는 32비트 이하가 필요한 다른 데이터입니다.
8진수 체계
8진수 체계는 오래된 컴퓨터 시스템에서는 인기가 있었지만 오늘날에는 거의 사용되지 않습니다. 그러나 우리는 지식을 위해 8진수 체계의 이상을 취할 것입니다.
8진수 체계는 3비트 경계를 가진 2진수 체계를 기반으로 합니다. 8진수 수 체계는 8진수를 사용하고 0에서 7까지의 숫자만 포함합니다. 이런 식으로 다른 숫자가 있으면 숫자가 유효하지 않은 8진수가 됩니다.
각 위치의 가중치는 표에 표시된 대로 다음과 같습니다.
| (베이스)파워 |
85 |
84 |
83 |
82 |
81 |
80 |
| 값 |
32768 |
4096 |
512 |
64 |
8 |
1 |
2진수에서 8진수로 변환
정수 2진수를 8진수로 변환하려면 다음 두 단계를 따릅니다.
먼저 2진수를 LSB에서 MSB까지 3비트 섹션으로 나눕니다 . 그런 다음 3비트 2진수를 8진수와 동등한 것으로 변환합니다. 더 잘 이해하기 위해 예를 들어 보겠습니다. 11001011010001과 같은 2진수가 8진수 체계로 변환되도록 주어졌다면 위의 두 단계를 다음과 같이 이 숫자에 적용합니다.
| 2진수의 3비트 섹션 |
011 |
001 |
011 |
010 |
001 |
| 동등한 숫자 |
3 |
1 |
3 |
2 |
1 |
따라서 2진수 11001011010001에 해당하는 8진수는 31321입니다.
8진수에서 2진수로 변환
정수 8진수를 해당 2진수로 변환하려면 다음 두 단계를 따릅니다.
먼저 10진수를 3비트 2진수로 변환합니다. 그런 다음 공백을 제거하여 3비트 섹션을 결합합니다. 예를 들어 보겠습니다. 8진수 정수 31321(Q)를 해당 2진수로 변환할 경우 위의 두 단계를 다음과 같이 적용합니다.
| 동등한 숫자 |
3 |
1 |
3 |
2 |
1 |
| 2진수의 3비트 섹션 |
011 |
001 |
011 |
010 |
001 |
따라서 8진수 31321(Q)의 2진수는 011 0010 1101 0001입니다.
8진수에서 10진수로 변환
8진수를 10진수로 변환하려면 각 위치의 값에 8진수 가중치를 곱하고 각 값을 더합니다.
이를 더 잘 이해하기 위해 예를 들어보겠습니다. 8진수 31321Q를 해당 10진수로 변환한다고 가정해 보겠습니다. 그런 다음 다음 단계를 따릅니다.
3*84 + 1*83 + 3*82 + 2*81 + 1*80 = 3*4096 + 1*512 + 3*64 + 2*8 + 1*1 = 12288 + 512 + 192 + 16 + 1 = 13009
10진수에서 8진수로 변환
10진수를 8진수로 변환하는 것은 약간 더 어렵습니다. 10진수에서 8진수로 변환하는 일반적인 방법은 8로 반복해서 나누는 것입니다. 이 방법에서는 10진수를 8로 나누고 나머지를 가장 낮은 유효 숫자로 옆에 씁니다. 이 과정은 몫을 8로 나누고 나머지를 몫이 0이 될 때까지 쓰는 것으로 계속됩니다.
나누기를 수행할 때, 10진수의 8진수에 해당하는 나머지는 가장 낮은 유효 자릿수(오른쪽)에서 시작하여 적고, 각각의 새로운 자릿수는 이전 자릿수의 바로 다음 유효 자릿수(왼쪽)에 적습니다.
예를 들어 더 잘 이해해 보겠습니다. 13009와 같은 10진수가 있다면(위의 예에서 이 10진수를 찾았고 8진수로 다시 변환하면 이전 예도 확인할 수 있습니다.) 이 방법은 다음 표에 설명되어 있습니다.
| 분할 |
몫 |
나머지 |
8진수 |
| 13009 / 8 |
1626 |
1 |
1 |
| 1626 / 8 |
203 |
2 |
21 |
| 203 / 8 |
25 |
3 |
321 |
| 25 / 8 |
3 |
1 |
1321 |
| 3 / 8 |
0 |
3 |
31321 |
보시다시피, 우리는 원래 숫자로 돌아왔습니다. 그것이 우리가 기대해야 할 것입니다. 이 표는 절차를 이해하기 위한 것입니다. 이제 작업의 용이성을 얻고 시간도 절약하기 위해 실제로 따라야 할 방법을 이해하기 위해 동일한 변환을 반복해 보겠습니다. 사실 둘 다 같은 것입니다.
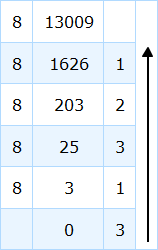
나머지를 화살표 방향에 따라 배열하면 예상했던 8진수 31321이 나옵니다.
16진수 체계
16진수는 데이터 복구 또는 기타 유형의 디스크 문제 해결 또는 디스크 분석 프로그래밍에서 가장 일반적으로 사용됩니다. 그 이유는 16진수가 다음과 같은 두 가지 기능을 제공하기 때문입니다.
16진수는 매우 간결합니다. 그리고 16진수에서 2진수로, 2진수에서 16진수로 변환하기 쉽습니다. 하드 디스크의 실린더, 헤드, 섹터 수와 같은 많은 중요한 것을 계산하거나 하드 디스크 편집 프로그램을 사용하여 다양한 특성과 문제를 분석할 때 16진수 시스템에 대한 좋은 지식이 필요합니다. 16진수 시스템은 니블 또는 4비트 경계를 사용하는 2진 시스템을 기반으로 합니다.
16 진수 체계는 16진법을 사용 하고 숫자 0~9와 문자 A, B, C, D, E, F만 포함합니다. 우리는 숫자와 함께 H를 사용하여 모든 16진수를 나타냅니다. 다음 표는 다양한 숫자 체계의 표현을 서로 구별하여 보여줍니다.
| 이진법 | 8진법 | 소수 | 마녀 |
| 0000B | 00Q | 00 | 00시 |
| 0001비 | 01Q | 01 | 01시 |
| 0010B | 02Q | 02 | 02시 |
| 0011B | 03Q | 03 | 03시 |
| 0100비 | 04Q | 04 | 04시 |
| 0101B | 05Q | 05 | 05시 |
| 0110B | 06Q | 06 | 06시 |
| 0111B | 07Q | 07 | 07시 |
| 1000B | 10Q | 08 | 08시 |
| 1001B | 11분기 | 09 | 09시 |
| 1010B | 12분기 | 10 | 0아 |
| 1011B | 13Q | 11 | 0비에이치 |
| 1100B | 14분기 | 12 | 0CH |
| 1101B | 15Q | 13 | 0DH |
| 1110B | 16Q | 14 | 0EH |
| 1111B | 17Q | 15 | 0FH |
| 1 0000B | 20Q | 16 | 10시간 |
이 표는 0에서 16까지의 10진수 값을 한 숫자 기수에서 다른 숫자 기수로 변환하는 데 필요한 모든 정보를 제공합니다.
16진수 각 위치의 가중치 값은 다음 표에 표시되어 있습니다.
| (기본)전력 |
163 |
162 |
161 |
160 |
| 값 |
4096 |
256 |
16 |
1 |
2진수에서 16진수로 변환
이진수를 16진수 형식으로 변환하려면 먼저 이진수에 가장 왼쪽에 선행 0을 채워 이진수에 4비트의 배수가 포함되도록 합니다. 그런 다음 다음 두 단계를 따릅니다.
먼저, 이진수를 LSB에서 MSB까지 4비트 섹션으로 나눕니다. 그런 다음 4비트 이진수를 16진수로 변환합니다. 이 방법을 더 잘 이해하기 위해 예를 들어 보겠습니다. 이진수 100 1110 1101 0011을 해당 16진수로 변환합니다. 그런 다음 아래에 표시된 것처럼 위의 두 단계를 적용합니다.
| 4비트 2진수 섹션 |
0100 |
1110 |
1101 |
0011 |
| 16진수 값 |
4 |
그리고 |
디 |
3 |
따라서 2진수 100 1110 1101 0011 에 해당하는 16진수 값 은 4ED3입니다.
16진수에서 2진수로 변환
16진수를 2진수로 변환하려면 다음 두 단계를 따릅니다.
먼저 16진수를 4비트 2진수로 변환합니다. 그런 다음 공백을 제거하여 4비트 섹션을 결합합니다. 절차를 더 잘 이해하기 위해 위의 16진수, 즉 4ED3의 예를 들어 다음과 같이 두 단계를 적용합니다.
| 16진수 값 |
4 |
그리고 |
디 |
3 |
| 4비트 2진수 섹션 |
0100 |
1110 |
1101 |
0011 |
따라서 16진수 4ED3에 대해 우리는 해당 2진수 = 0100 1110 1101 0011을 얻습니다.
예상되는 대답입니다.
16진수에서 10진수로 변환 16진수에서 10진수로 변환하려면 각 위치의 값을 16진수 가중치로 곱하고 각 값을 더합니다. 절차를 더 잘 이해하기 위해 예를 들어 보겠습니다. 16진수 3ABE를 동등한 10진수로 변환한다고 가정합니다. 그러면 절차는 다음과 같습니다. 3*163 + A*162 + B*161 + E*160 = 3* 4096 + 10* 256 + 11*16 + 14 = 12288 + 2560 + 176 + 14 = 15038
따라서 16진수 3ABE에 해당하는 10진수는 15038입니다.
10진수에서 16진수로 변환
10진수를 16진수로 변환하는 일반적인 방법은 16으로 반복 나누는 것 입니다 . 이 방법에서는 10진수를 16으로 나누고 나머지를 가장 낮은 유효 숫자로 옆에 씁니다.
이 과정은 몫을 16으로 나누고 몫이 0이 될 때까지 나머지를 쓰는 것으로 계속됩니다. 나누기를 수행할 때 10진수의 16진수에 해당하는 나머지는 가장 덜 중요한 자릿수(오른쪽)에서 시작하여 쓰고, 각각의 새로운 자릿수는 이전 자릿수의 바로 다음 더 중요한 자릿수(왼쪽)에 씁니다.
예를 들어 알아보도록 하죠. 위에서 변환한 후 얻은 10진수 15038을 취합니다. 이를 통해 위의 변환을 확인할 수 있고 그 반대도 가능합니다.
| 분할 |
몫 |
나머지 |
16진수 |
| 15038 / 16 |
939 |
14 ( E H) |
그리고 |
| 939 / 16 |
58 |
11 ( 비에이치 ) |
BE |
| 58 / 16 |
3 |
10 ( A H) |
아베 |
| 3 / 16 |
0 |
3 ( 3 시간) |
03아베 |
따라서 우리는 16진수 03ABE H를 얻습니다. 이것은 10진수 15038과 동일하며 이런 식으로 우리는 원래의 숫자로 돌아갑니다. 이것이 우리가 기대해야 할 것입니다.
다음 표는 0에서 255까지의 10진수 범위에서 16진수를 10진수로 변환하거나 그 반대로 변환하는 것을 빠르게 검색하는 데 도움이 될 수 있습니다.
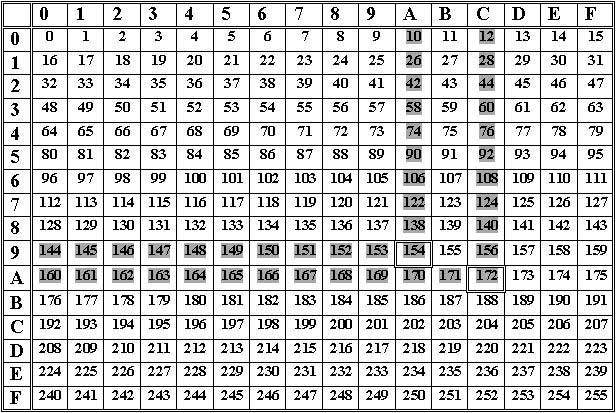
이 Square 표에는 0에서 A까지 시작하는 16개의 행이 있고, 0에서 A까지 시작하는 16개의 열이 있습니다. 이 표에서 0H에서 FFH 범위 사이에 있는 16진수의 10진수 값을 찾을 수 있습니다. 즉, 숫자의 10진수 값은 0에서 255까지의 10진수 범위 사이에 있어야 합니다.
- 위 표에서 16진수에 대한 10진수 값 찾기: 위 표에서 행 수는 16진수의 첫 번째 숫자(왼쪽 16진수 숫자)를 나타내고, 열 수는 16진수의 두 번째 숫자(오른쪽 16진수 숫자)를 나타냅니다.
ACH와 같은 16진수를 동등한 10진수로 변환할 수 있다고 합시다. 그러면 표의 Ath 행의 Cth 열에서 10진수 값을 보고 16진수 ACH에 대한 동등한 10진수인 172라는 10진수 값을 얻습니다.
- 위 표에서 10진수에 대한 16진수 값 찾기: 위 표에서 행 수는 16진수의 첫 번째 숫자(왼쪽 16진수 숫자)를 나타내고 열 수는 16진수의 두 번째 숫자(오른쪽 16진수 숫자)를 나타냅니다. 따라서 10진수를 동등한 16진수로 변환해야 하는 경우 표에서 숫자를 검색하여 다음과 같이 동등한 16진수 값을 찾으세요.
10진수 숫자에 대한 16진수 값 = (행 번호)(열 번호)
예를 들어 10진수 154에 대한 동등한 16진수 값을 찾으려면 표에서 숫자의 위치를 확인하세요. 숫자 154는 표의 9번째 행, A번째 열에 있습니다. 따라서 10진수 154에 대한 동등한 16진수 값은 9AH입니다.
아스키 코드
약어 ASCII는 American Standard Code for Information Interchange의 약자입니다. ASCII 문자 집합의 처음 128개 문자와 동일하지만 나머지 문자와는 다른 문자, 숫자 및 기호에 대한 코딩 표준입니다. 이러한 다른 문자는 일반적으로 IBM에서 정의한 특수 ASCII 문자 또는 확장 문자라고 합니다.
ASCII 코드 0에서 1FH까지의 처음 32개 문자는 인쇄되지 않는 특수 문자 집합을 형성합니다. 이러한 문자는 기호를 표시하는 대신 다양한 프린터 및 디스플레이 제어 작업을 수행하기 때문에 제어 문자라고 합니다. 이러한 문자는 이 장에서 제공하는 ASCII 문자 표에 나열되어 있습니다. 이러한 제어 문자는 다음과 같은 의미를 갖습니다.
ZERO(제로):
문자 없음. 데이터가 없는 저장 장치의 표면(예: 플래터 표면)에 시간을 채우거나 공간을 채우는 데 사용됩니다. 데이터 와이퍼(파괴적, 비파괴적 모두)를 프로그래밍할 때 이 문자를 사용하여 할당되지 않은 공간을 지워서 삭제된 데이터가 어떤 사람이나 어떤 프로그램에 의해서도 복구되지 않도록 합니다.
SOH(방향 시작):
이 문자는 주소나 라우팅 정보를 포함할 수 있는 제목의 시작을 나타내는 데 사용됩니다.
TX(텍스트 시작):
이 문자는 텍스트의 시작을 나타내는 데 사용되며, 이런 방식으로 제목의 끝을 나타내는 데도 사용됩니다.
ETX (텍스트 끝):
이 문자는 STX로 시작하는 텍스트를 종료하는 데 사용됩니다.
EOT(전송 종료):
이 문자는 전송의 끝을 나타내며, 여기에는 제목이 있는 하나 이상의 "테스트"가 포함될 수 있습니다.
ENQ (문의):
원격 스테이션으로부터 응답을 요청하는 것입니다. 스테이션이 자신을 식별하도록 요청하는 것입니다.
ACK(확인):
수신 장치에서 샌더에 대한 긍정 응답으로 전송되는 문자입니다. 여론조사 메시지에 대한 긍정적 응답으로 사용됩니다.
BEL(벨):
인간의 주의를 환기할 필요가 있을 때 사용됩니다. 알람이나 주의 장치를 제어할 수 있습니다. 아래와 같이 명령 프롬프트에 이 문자를 입력하면 컴퓨터에 부착된 스피커에서 벨 톤을 들을 수 있습니다.
C:\> 에코 ^G
여기서 ^G는 Ctrl + G 키 조합으로 인쇄됩니다.
BS (백스페이스):
이 문자는 인쇄 메커니즘이나 디스플레이 커서가 한 위치에서 뒤로 움직이는 것을 나타냅니다.
HT(수평 탭):
이는 인쇄 메커니즘 또는 디스플레이 커서가 다음에 미리 지정된 "탭" 또는 정지 위치로 앞으로 이동하는 것을 나타냅니다.
LF(줄바꿈):
인쇄 장치나 디스플레이 커서가 다음 줄의 시작 부분으로 이동하는 것을 나타냅니다.
VT(수직 탭):
이는 인쇄 메커니즘 또는 디스플레이 커서가 미리 지정된 일련의 인쇄 줄 중 다음 줄로 이동하는 것을 나타냅니다.
FF(양식 피드):
이는 인쇄 장치 또는 디스플레이 커서가 다음 페이지 또는 화면의 시작 위치로 이동하는 것을 나타냅니다.
CR(캐리지 리턴):
인쇄 장치나 디스플레이 커서가 같은 줄의 시작 위치로 이동하는 것을 나타냅니다.
SO (교대근무):
이는 다음 코드 조합이 Shift In 문자에 도달할 때까지 표준 문자 집합 외부로 해석되어야 함을 나타냅니다.
나 (Shift In):
이는 다음 코드 조합이 표준 문자 집합에 따라 해석되어야 함을 나타냅니다.
DLE(데이터 링크 이스케이프):
연속적으로 이어지는 하나 이상의 문자의 의미를 변경하는 문자입니다. 보충 제어를 제공하거나 모든 비트 조합을 가진 데이터 문자를 보낼 수 있습니다.
DC1, DC2, DC3 및 DC4(장치 제어):
이는 보조 장치나 특수 단말 기능을 제어하기 위한 문자입니다.
NAK(부정적 확인):
수신 장치가 송신자에게 부정적인 응답으로 전송하는 문자입니다. 폴링 메시지에 대한 부정적인 응답으로 사용됩니다.
SYN(동기/유휴):
동기식 전송 시스템에서 데이터가 전송되지 않을 때 동기화를 달성하기 위해 사용됩니다. 동기식 전송 시스템은 SYN 문자를 지속적으로 전송할 수 있습니다.
ETB(전송 블록 종료):
이 문자는 통신 목적으로 데이터 블록의 끝을 나타냅니다. 블록 구조가 처리 형식과 반드시 관련이 없는 데이터 차단에 사용됩니다.
CAN(취소): 일반적으로 오류가 감지되었기 때문에 메시지나 블록에서 앞에 오는 데이터를 무시해야 함을 나타냅니다.
EM(매체 끝): 테이프, 표면(보통 디스크 플래터), 다른 매체의 물리적 끝이나 매체의 필요 부분 또는 사용된 부분의 끝을 나타냅니다.
SUB (대체): 오류가 있거나 유효하지 않은 문자를 대체하는 것입니다.
ESC(이스케이프): 이 문자는 연속해서 나오는 지정된 수의 문자에 대체 의미를 부여하여 코드 확장을 제공하기 위한 문자입니다.
FS(파일 구분 문자): 이 문자는 파일 구분 문자로 사용됩니다.
GS(그룹 구분 기호): 그룹 구분 문자로 사용됩니다.
RS(레코드 구분 기호): 레코드 구분 문자로 사용됩니다.
미국(United Separator):
이는 통합 구분 기호입니다.
두 번째 32개 ASCII 문자 코드 그룹에는 다양한 구두점 기호, 특수 문자 및 숫자가 있습니다. 이 그룹에서 가장 주목할 만한 문자는 다음과 같습니다.
공백 문자(ASCII 코드 20H) 숫자 0~9(ASCII 코드 30h~39h) 수학 및 논리 기호
SP (스페이스):
단어를 구분하거나 인쇄 메커니즘을 이동하거나 커서를 한 위치 앞으로 표시하는 데 사용되는 인쇄되지 않는 문자입니다.
세 번째 32개 ASCII 문자 그룹은 대문자 알파벳 문자 그룹입니다. A에서 Z까지의 문자에 대한 ASCII 코드는 41H에서 5AH 범위에 있습니다. 알파벳 문자는 26개뿐이므로 나머지 6개 코드는 다양한 특수 기호를 포함합니다.
32개의 ASCII 문자 코드로 구성된 네 번째 그룹은 소문자 알파벳 기호, 5개의 추가 특수 기호 및 또 다른 제어 문자인 삭제로 구성됩니다.
DEL (삭제):
이는 원치 않는 문자를 삭제한다는 것보다는 원치 않는 문자를 지우는 데 사용됩니다.
다음은 ASCII 코드와 확장 문자를 나타내는 두 개의 표입니다. 첫 번째 표는 설명된 네 가지 유형의 문자를 모두 나타냅니다. 이 표는 다음에 표시된 것처럼 데이터 표현 및 ASCII 표입니다.
데이터 표현 및 ASCII 코드 표:
| 마녀 | 12월 | 한국어: | CTRL 키 |
|---|
| 00 | 0 | 널(NULL) | ^@ |
| 01 | 1 | 소오 | ^아 |
| 02 | 2 | 에스엑스티엑스 | ^비 |
| 03 | 3 | 이엑스 | ^ 씨 |
| 04 | 4 | 종료 | ^디 |
| 05 | 5 | 엔큐 | ^이 |
| 06 | 6 | 확인 | ^F |
| 07 | 7 | 벨 | ^ 지 |
| 08 | 8 | 학사 | ^H |
| 09 | 9 | 하이퍼텍스트 | ^나 |
| 0A | 10 | 라프 | ^ 제이 |
| 0비 | 11 | 버몬트 | ^케이 |
| 0도 | 12 | FF | ^ 엘 |
| 0일 | 13 | 크. | ^ ㅁ |
| 0이 | 14 | 그래서 | ^아니요 |
| 0F | 15 | 그리고 | ^오 |
| 10 | 16 | 에 따르면 | ^ 피 |
| 11 | 17 | 디씨1 | ^큐 |
| 12 | 18 | DC2 | ^ 알 |
| 13 | 19 | DC3 | ^ 에 |
| 14 | 20 | DC4 | ^ 티 |
| 15 | 21 | 원티드 | ^ 유 |
| 16 | 22 | 그의 | ^V |
| 17 | 23 | 영어: ETB는 영어권 국가입니다. | ^ ㅁ |
| 18 | 24 | 할 수 있다 | ^X |
| 19 | 25 | 안에 | ^그리고 |
| 1A | 26 | 보결 | ^Z |
| 1B | 27 | 키보드 |
| 1씨 | 28 | FS |
| 1D | 29 | GS |
| 1이 | 30 | RS |
| 1층 | 31 | 우리를 |
| 마녀 | 12월 | 한국어: |
|---|
| 20 | 32 | 에스. |
| 21 | 33 | ! |
| 22 | 34 | " |
| 23 | 35 | # |
| 24 | 36 | $ |
| 25 | 37 | % |
| 26 | 38 | & |
| 27 | 39 | ' |
| 28 | 40 | ( |
| 29 | 41 | ) |
| 2A | 42 | * |
| 2B | 43 | + |
| 2씨 | 44 | , |
| 2차원 | 45 | - |
| 2이전 | 46 | . |
| 2층 | 47 | / |
| 30 | 48 | 0 |
| 31 | 49 | 1 |
| 32 | 50 | 2 |
| 33 | 51 | 3 |
| 34 | 52 | 4 |
| 35 | 53 | 5 |
| 36 | 54 | 6 |
| 37 | 55 | 7 |
| 38 | 56 | 8 |
| 39 | 57 | 9 |
| 3A | 58 | : |
| 3B | 59 | ; |
| 3씨 | 60 | < |
| 3D | 61 | = |
| 3E | 62 | > |
| 3층 | 63 | ? |
| 마녀 | 12월 | 한국어: |
|---|
| 40 | 64 | @ |
| 41 | 65 | 에이 |
| 42 | 66 | 비 |
| 43 | 67 | 기음 |
| 44 | 68 | 디 |
| 45 | 69 | 그리고 |
| 46 | 70 | 에프 |
| 47 | 71 | G |
| 48 | 72 | 시간 |
| 49 | 73 | 나 |
| 4A | 74 | 제이 |
| 4B | 75 | 케이 |
| 4씨 | 76 | 엘 |
| 4D | 77 | 중 |
| 4E | 78 | N |
| 4층 | 79 | 그만큼 |
| 50 | 80 | 피 |
| 51 | 81 | 큐 |
| 52 | 82 | 아르 자형 |
| 53 | 83 | 에스 |
| 54 | 84 | 티 |
| 55 | 85 | 안에 |
| 56 | 86 | ~ 안에 |
| 57 | 87 | 안에 |
| 58 | 88 | 엑스 |
| 59 | 89 | 그리고 |
| 5A | 90 | 와 함께 |
| 5B | 91 | [ |
| 5도씨 | 92 | \ |
| 5일 | 93 | ] |
| 5E | 94 | ^ |
| 5층 | 95 | _ |
| 마녀 | 12월 | 한국어: |
|---|
| 60 | 96 | ` |
| 61 | 97 | 에이 |
| 62 | 98 | 비 |
| 63 | 99 | 기음 |
| 64 | 100 | 디 |
| 65 | 101 | 그리고 |
| 66 | 102 | 에프 |
| 67 | 103 | g |
| 68 | 104 | 시간 |
| 69 | 105 | 나 |
| 6A | 106 | 제이 |
| 6B | 107 | 케이 |
| 6세기 | 108 | 엘 |
| 6일 | 109 | 중 |
| 6E | 110 | N |
| 6층 | 111 | 그만큼 |
| 70 | 112 | 피 |
| 71 | 113 | 큐 |
| 72 | 114 | 아르 자형 |
| 73 | 115 | 에스 |
| 74 | 116 | 티 |
| 75 | 117 | ~에 |
| 76 | 118 | ~에 |
| 77 | 119 | ~ 안에 |
| 78 | 120 | 엑스 |
| 79 | 121 | 그리고 |
| 7A | 122 | 와 함께 |
| 7비 | 123 | {[} |
| 7세기 | 124 | | |
| 7일 | 125 | } |
| 7E | 126 | ~ |
| 7층 | 127 | 의 |
다음 표는 종종 확장 ASCII 문자라고 불리는 128개의 특수 ASCII 문자 세트를 보여줍니다.
| 마녀 | 12월 | 한국어: |
|---|
| 80 | 128 | 무엇 |
| 81 | 129 | 유 |
| 82 | 130 | 그리고 |
| 83 | 131 | 에이 |
| 84 | 132 | 에이 |
| 85 | 133 | 가지다 |
| 86 | 134 | 에게 |
| 87 | 135 | 무엇 |
| 88 | 136 | ~ 할 것이다 |
| 89 | 137 | 에스 |
| 8A | 138 | 그리고 |
| 8비 | 139 | 나 |
| 8씨 | 140 | 큐 |
| 8일 | 141 | ~에 |
| 8E | 142 | 에이 |
| 8층 | 143 | 오 |
| 90 | 144 | 그리고 |
| 91 | 145 | 오 |
| 92 | 146 | 오, 오 |
| 93 | 147 | 우산 |
| 94 | 148 | 그 |
| 95 | 149 | 아니요 |
| 96 | 150 | 그리고 |
| 97 | 151 | 유 |
| 98 | 152 | 와이 |
| 99 | 153 | 그 |
| 9A | 154 | 유 |
| 9B | 155 | ¢ |
| 9세기 | 156 | £ |
| 9일 | 157 | ¥ |
| 9E | 158 | ₧ |
| 9층 | 159 | ƒ |
| A0 | 160 | ~에 |
| A1 | 161 | ~에 |
| A2 | 162 | ~에서 |
| A3 | 163 | 음 |
| A4 | 164 | N |
| 마녀 | 12월 | 한국어: |
|---|
| A5 | 165 | N |
| A6 | 166 | ª |
| A7 | 167 | º |
| A8 | 168 | ¿ |
| A9 | 169 | ⌐ |
| 금주 모임 | 170 | ¬ |
| 아비 | 171 | ½ |
| 교류 | 172 | ¼ |
| 광고 | 173 | ¡ |
| 하지만 | 174 | « |
| 의 | 175 | » |
| 비0 | 176 | ░ |
| 비1 | 177 | ▒ |
| 비2 | 178 | ▓ |
| 비3 | 179 | │ |
| 비4 | 180 | ┤ |
| 비5 | 181 | ╡ |
| 비6 | 182 | ╢ |
| 비7 | 183 | ╖ |
| 비8 | 184 | ╕ |
| 비9 | 185 | ╣ |
| 아니다 | 186 | ║ |
| 비비 | 187 | ╗ |
| 기원전 | 188 | ╝ |
| 비디 | 189 | ╜ |
| BE | 190 | ╛ |
| 남자친구 | 191 | ┐ |
| 씨0 | 192 | └ |
| C1 | 193 | ┴ |
| C2 | 194 | ┬ |
| C3 | 195 | ├ |
| C4 | 196 | ─ |
| C5 | 197 | ┼ |
| C6 | 198 | ╞ |
| C7 | 199 | ╟ |
| C8 | 200 | ╚ |
| C9 | 201 | ╔ |
| 마녀 | 12월 | 한국어: |
|---|
| 저것 | 202 | ╩ |
| 시비(CB) | 203 | ╦ |
| 참조 | 204 | ╠ |
| CD | 205 | ═ |
| 이것 | 206 | ╬ |
| CF | 207 | ╧ |
| 디0 | 208 | ╨ |
| 디1 | 209 | ╤ |
| 디2 | 210 | ╥ |
| 디3 | 211 | ╙ |
| 디4 | 212 | ╘ |
| 디5 | 213 | ╒ |
| 디6 | 214 | ╓ |
| 디7 | 215 | ╫ |
| 디8 | 216 | ╪ |
| 디9 | 217 | ┘ |
| 그리고 | 218 | ┌ |
| 비디 | 219 | █ |
| 컬럼비아 특별구 | 220 | ▄ |
| 디.디. | 221 | ▌ |
| 에서 | 222 | ▐ |
| 디에프 | 223 | ▀ |
| 이0 | 224 | 에이 |
| 이1 | 225 | 봄 여름 시즌 |
| 이2 | 226 | 와 함께 |
| 이3 | 227 | N |
| E4 | 228 | 와 함께 |
| E5 | 229 | ~와 함께 |
| E6 | 230 | µ |
| E7 | 231 | 티 |
| E8 | 232 | 에프 |
| E9 | 233 | 나 |
| 예 | 234 | 생각 |
| 이.이. | 235 | G |
| 유럽 연합 | 236 | ∞ |
| 에드 | 237 | 에프 |
| 전자 | 238 | 이자형 |
| 16진법 | 12월 | HRC |
|---|
| 만약에 | 239 | ∩ |
| F0 | 240 | ≡ |
| F1 | 241 | ± |
| F2 | 242 | ≥ |
| F3 | 243 | ≤ |
| F4 | 244 | ⌠ |
| F5 | 245 | ⌡ |
| F6 | 246 | ÷ |
| F7 | 247 | ≈ |
| F8 | 248 | ° |
| F9 | 249 | ∙ |
| 하지만 | 250 | · |
| 페이스북 | 251 | √ |
| FC | 252 | ⁿ |
| FD | 253 | ² |
| 여 | 254 | ■ |
| FF | 255 | |
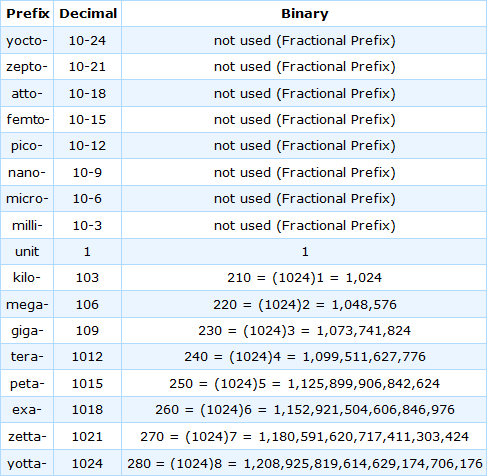
데이터를 표현하고 저장하는 데 자주 사용되는 숫자 시스템의 몇 가지 중요한 용어
아래 표는 분수 접두사와 증분 접두사로 사용되는 다양한 접두사를 보여줍니다.
바이트:
바이트의 가장 중요한 용도는 문자 코드를 저장하는 것입니다. 우리는 이에 대해 이전에 논의한 적이 있습니다.
킬로바이트
기술적으로 킬로바이트는 1024바이트와 같지만, 종종 1000바이트의 동의어로 느슨하게 사용됩니다. 10진법 체계에서 킬로는 1000과 같지만, 2진법 체계에서 킬로는 1024(210)와 같습니다.
킬로바이트는 일반적으로 K 또는 Kb로 표시됩니다. 10진수 K(1000)와 2진수 K(1024)를 구별하기 위해 IEEE(Institute of Electrical and Electronics Engineers) 표준은 10진수 킬로에는 소문자 k를, 2진수 킬로에는 대문자 K를 사용하는 관례를 따르기로 제안했지만, 이 관례가 엄격하게 지켜지는 것은 아닙니다.
메가바이트
메가바이트는 1,048,576(220)바이트의 데이터 저장 용량을 나타내는 데 사용되지만, MB/s와 같이 데이터 전송 속도를 나타내는 데 사용될 경우 100만 바이트를 의미합니다. 메가바이트는 보통 M 또는 MB로 줄여서 표기합니다.
기가바이트
기가바이트는 1,073,741,824(230)바이트의 저장 용량을 설명하는 데 사용되며, 1기가바이트는 1,024메가바이트와 같습니다. 기가바이트는 보통 G 또는 GB로 줄여서 표기합니다.
테라바이트
테라바이트는 1,099,511,627,776(240)바이트로 약 1조 바이트입니다. 테라바이트는 때로 1012(1,000,000,000,000)바이트로 표현되는데, 정확히 1조에 해당합니다.
페타바이트
페타바이트는 1,125,899,906,842,624(250)바이트로 표시됩니다. 페타바이트는 1,024테라바이트와 같습니다.
엑사바이트
엑사바이트는 1,152,921,504,606,846,976(260)바이트로 설명됩니다. 엑사바이트는 1,024페타바이트와 같습니다.
제타바이트
제타바이트는 1,180,591,620,717,411,303,424(270)바이트로 설명되며, 이는 약 1021(1,000,000,000,000,000,000,000)바이트입니다. 제타바이트는 1.024엑사바이트와 같습니다.
요타바이트
요타바이트는 1,208,925,819,614,629,174,706,176(280)바이트로 설명되며, 이는 약 1024(1,000,000,000,000,000,000,000)바이트입니다. 요타바이트는 1.024 제타바이트와 같습니다.
데이터 저장의 일반 조건
앞서 언급한 다양한 데이터 비트 그룹을 지칭하는 용어를 지칭하는 데에는 다양한 이름이 사용됩니다. 가장 일반적으로 사용되는 몇 가지 사항은 다음 표에 나와 있습니다.
| 사선 |
비트 수 |
| 페이지 / 번호 / 플래그 |
1 |
| 물다 / 물다 |
4 |
| 바이트/문자 |
8 |
| 단어 |
16 |
| 더블워드 / 롱워드 |
32 |
| 매우 긴 단어 |
64 |